CS229 7.1应用机器学习中的一些技巧
本文所讲述的是怎么样去在实践中更好的应用机器学习算法,比如如下经验风险最小化问题:
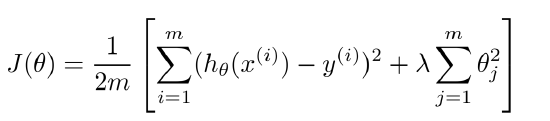
当求解最优的 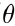 后,发现他的预测误差非常之大,接下来如何处理来使得当前的误差尽可能的小呢?这里给出以下几个选项,下面介绍的是如何在一下这些应对策略中选择正确的方法来助力以上问题。
后,发现他的预测误差非常之大,接下来如何处理来使得当前的误差尽可能的小呢?这里给出以下几个选项,下面介绍的是如何在一下这些应对策略中选择正确的方法来助力以上问题。

当模型的variance比较大时,可能存在过拟合,这时可以尝试增多样本或者减少特征或者增大正则参数。
当模型的bias比较大时,可能存在欠拟合,这时可以尝试增加更多的特征或者增加多项特征或减小正则参数。
首先,一般的Mechine Learning问题,我们会把数据分为训练集,交叉验证集,测试集,比例分别为6:2:2.

这样,即可以用一下三哥公式分别计算假设函数在三个集合上的损失:

接下来,用交叉验证集合找到最优的 ,用该 去到测试机上验证来得到测试误差Jerr():

bias. variance.
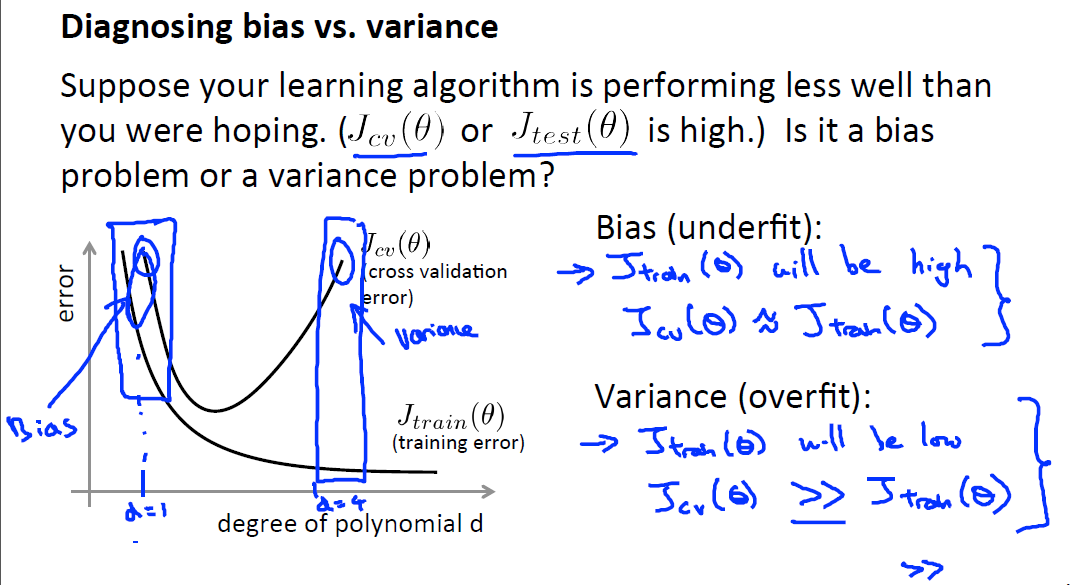
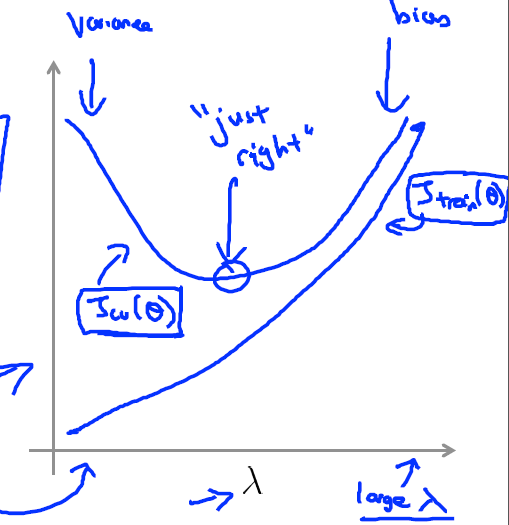
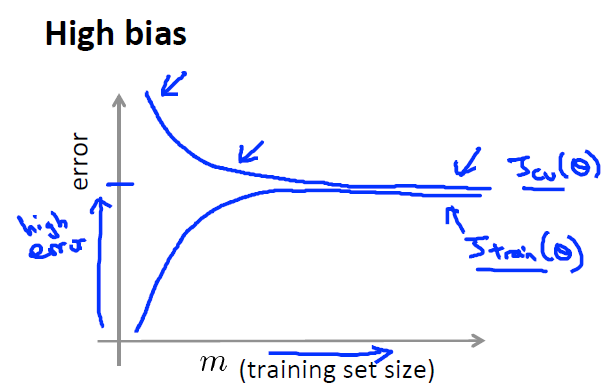
如果目前的算法表现不是很好Jcv或者Jtest很高,可以绘制如下关于bias与variance的图来确定是哪里的问题,如果Jtrain与Jcv均过高,则为bais问题,模型还处于欠拟合的状态,或Jtrain相对Jcv很低,则为variance问题。
正则化项 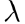 的选取问题,随着 的增大,参数 的取值会越来越小,模型处于欠拟合状态,偏差bais会越来越大,Jtrain也会随之增大
的选取问题,随着 的增大,参数 的取值会越来越小,模型处于欠拟合状态,偏差bais会越来越大,Jtrain也会随之增大
在交叉验证集合上,当 很小时, 取值很大,模型可能处于过拟合状态,variance会很大,随着 增大,Jcv会先减小到最小值,此处的最小值点即为bais与variance比较平衡的地方。当 继续增大,Jcv也会便也会开始增大,最终会导致bais比较大。所以此处Jcv处于最小值的情况下才是最优的 。
增加训练数据
首先注意,随着训练数据的增多,根据6 2 2 的比例,交叉验证集 与 测试集的数据均会增加。
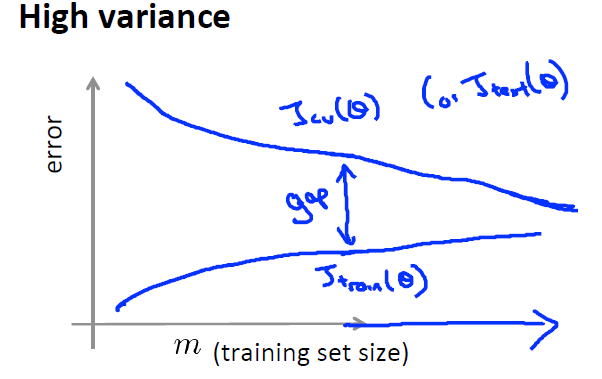
1)当使用一个相对合适的模型时,当数据比较少时,Jtrain会完美拟合训练数据,但此时Jcv会比较大,因为数据少得话模型很难范化到交叉验证集,数据的增加会导致Jtrain增大,Jcv减小,此时增多数据的效果会越来越好。
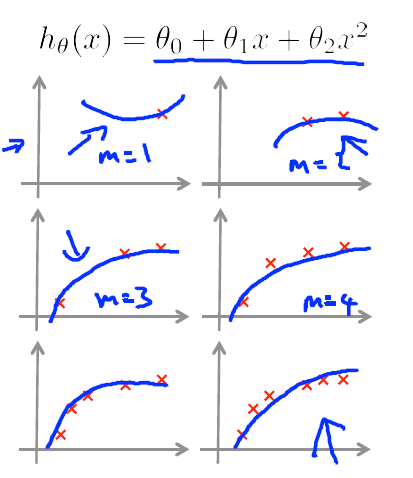
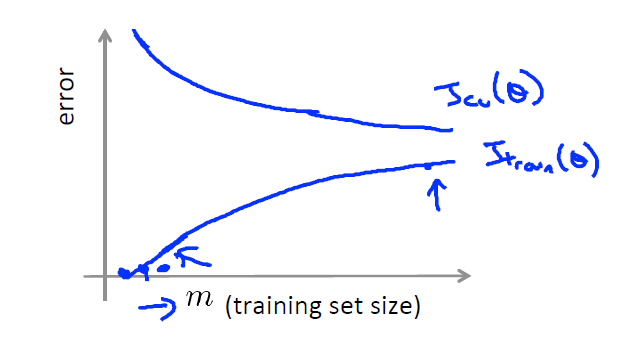
2)当使用一个欠拟合的模型时,会导致Jtrain非常之大,此时,增大数据量不会有任何效果,因为Jcv不会变的更小,模型无论在测试集还是训练集上都不会有很好的效果。
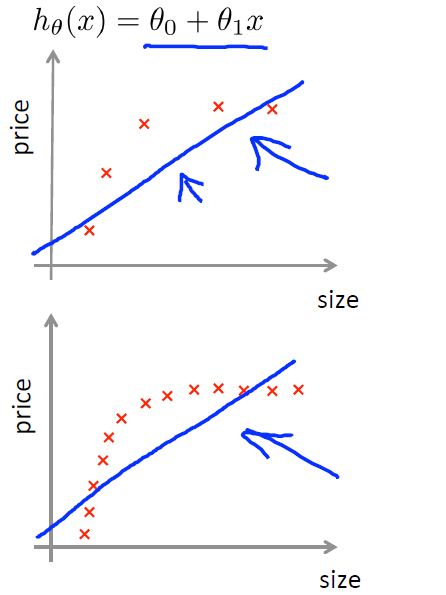
3)当使用一个过拟合的模型时,当数据较少时,Jtrain与Jcv之间的间隔会比较大,此时增大数据量,效果会有一些提升,Jtrain与Jcv的间隔会减小,这也就是所谓的增多训练数据来避免过拟合。

CS229 7.1应用机器学习中的一些技巧的更多相关文章
- 机器学习中的相似性度量(Similarity Measurement)
机器学习中的相似性度量(Similarity Measurement) 在做分类时常常需要估算不同样本之间的相似性度量(Similarity Measurement),这时通常采用的方法就是计算样本间 ...
- paper 127:机器学习中的范数规则化之(二)核范数与规则项参数选择
机器学习中的范数规则化之(二)核范数与规则项参数选择 zouxy09@qq.com http://blog.csdn.net/zouxy09 上一篇博文,我们聊到了L0,L1和L2范数,这篇我们絮叨絮 ...
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数
L1正则会产生稀疏解,让很多无用的特征的系数变为0,只留下一些有用的特征 L2正则不让某些特征的系数变为0,即不产生稀疏解,只让他们接近于0.即L2正则倾向于让权重w变小.见第二篇的推导. 所以,样本 ...
- ML 07、机器学习中的距离度量
机器学习算法 原理.实现与实践 —— 距离的度量 声明:本篇文章内容大部分转载于July于CSDN的文章:从K近邻算法.距离度量谈到KD树.SIFT+BBF算法,对内容格式与公式进行了重新整理.同时, ...
- paper 56 :机器学习中的算法:决策树模型组合之随机森林(Random Forest)
周五的组会如约而至,讨论了一个比较感兴趣的话题,就是使用SVM和随机森林来训练图像,这样的目的就是 在图像特征之间建立内在的联系,这个model的训练,着实需要好好的研究一下,下面是我们需要准备的入门 ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数(转)
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- 机器学习中的算法-决策树模型组合之随机森林与GBDT
机器学习中的算法(1)-决策树模型组合之随机森林与GBDT 版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使 ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
随机推荐
- python 术语
python 术语 术语英文 术语中文 说明 PyPI(Python Package Index) 搜索python包的网站:https://pypi.org/ pip.easy_install 包管 ...
- vue-cli、create-react-app 项目如何查看打包分析?
vue-cli.create-react-app 项目如何查看打包分析? 项目 如何查看打包分析 vue-cli 创建的项目 已经集成 webpack-bundle-analyzer,运行npm ru ...
- Go 并发控制--WaitGroup的使用
开发过程中,经常task之间的同步问题.例如,多个子task并发完成一部分任务,主task等待他们最后结束. 在Go语言,实现同步的一种方式就是WaitGroup. Example package m ...
- input子系统详解2
上一节大概了解了输入子系统的流程 这一节认真追踪一下代码 input.c: input_init(void)函数 static int __init input_init(void) { int er ...
- centos7 svn服务器的搭建
centos7下svn的安装与配置 1.环境 centos7 2.安装svnyum -y install subversion 3.配置 建立版本库目录mkdir /www/svndata svn ...
- 第一个Django项目
安装 pip install Django==2.0.5 命令行下创建Django项目 django-admin startproject first_project # 创建项目 cd first_ ...
- NPC问题及证明
致谢:http://www.docin.com/p-1902790324.html
- 宝塔linux面板运行jsp文件的配置工作
第一步宝塔安装和软件安装我们先安装宝塔面板(这个不需要我说咋弄吧) 安装完成后登录到宝塔面板然后安装软件我个人喜欢nginx最新版,mysql由于服务器配置很菜所以没发装56,php什么的我用不到就没 ...
- 引用 自动化测试基础篇--Selenium简介
原文链接:http://www.cnblogs.com/sanzangTst/p/7452636.html 鸣谢参藏法师 一.软件开发的一般流程 二.什么叫软件测试? 软件测试(英语:Software ...
- uoj #49. 【UR #3】铀仓库
http://uoj.ac/problem/49 这题二分答案可以做,同时存在另一个直接二分的解法. 考虑对每个点,二分能向左右延伸的最大半径,由于权值范围较大,不能O(1)查询向一侧走指定距离后到达 ...