Others-大数据平台Lambda架构浅析(全量计算+增量计算)
笔者刚接触大数据方面时,只知道Hadoop和时下很火的Spark,对Hadoop、Spark的认知只停留在跑跑demo,写点离线小app,后来随着学业项目的需要,开始逐步了解时下工业界的大数据平台是如何搭建起来的。在搜刮大量资料后,从一篇paper里看到Lambda这一陌生的字眼,再一搜,发现这正是我需要的大数据平台基础架构。Oryx2正是基于Lambda架构和Spark搭建的大数据处理开源框架。
废话不多说,谨以此篇博文记录自己对lambda架构的理解 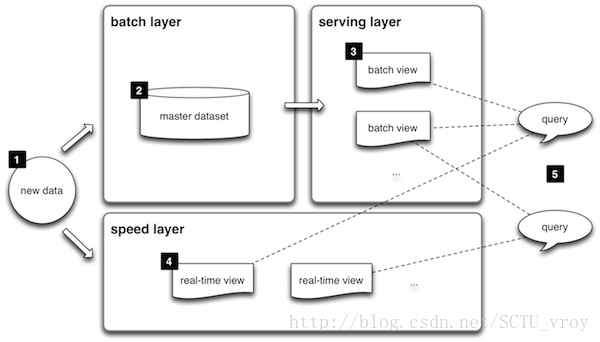
上图便是从lambda官网盗取的架构图
1:所有数据都来自于同一入口,然后被分发到batch layer(批处理层)和speed layer(实时计算层)
对于数据来源,可参考Oryx2的做法,统一采用Kafka接入Spark Streaming,然后再根据订阅的topic分发数据到batch layer和speed layer。关于Kafka接入Spark Streaming,确实挺多坑,当然对Kafka熟悉的大神就很easy,对我这种菜鸡来说着实吃力。
我试了两种方式(Kafka 0.10.1 + Spark 2.0.0):
1)Spark官网提供的方法,详尽参考Spark Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher),按照教程一步一步来,肯定可以成功
2)使用开源框架kafka-spark-consumer,由于此框架对应的spark版本是spark1.6.0,kafka支持的版本有0.8、0.9、0.10,所以可以放心接入,只是使用spark2.0+的童鞋需要手动更改下框架中提供的demo(SampleConsumer.java),此框架亲测可用!
2:batch layer官网给出简略解释是:两个作用{1)管理全量数据(不可变的,且只用append方式增加数据;2)处理全量数据得出模型–>结果)
对于batch layer,主要用于全量计算,处理所有历史数据,这里有三点注意:
1)数据是有限的
2)数据需要被持久化
3)数据量大–>导致处理过程high latency
那么,批处理层怎么实现好呢?
从Kafka接入数据到Spark Streaming后,处理每个rdd,将rdd中数据解析结构化并持久化到HDFS中。笔者是基于HBase+Parquet+Spark SQL的机制来做处理,首先将所有原数据保存到HBase的一张表中,然后根据row key(可加入时间戳)读取HBase数据,根据读取到的数据从remote server文件数据源服务器fetch文件到平台的HDFS,用Parquet记录文件中需要作为训练集的信息,训练模型时再用Spark SQL去读parquet file(仅供参考,过程可根据业务不同调整)
3:serving layer主要用于merge 批处理层和speed层结果,供外部web接口查询结果用的
4:speed layer的出现主要是弥补batch layer高延时的缺点,是一种增量计算的处理层
怎么理解和实现“增量计算”呢?说实话,这着实让我费解了好久……
其实,说白了,就是对从时间起始点开始进入系统的数据,采用分块处理的方式,将数据分成各自独立的进行处理,即micro-batch processing。Spark Streaming就是基于这种思想衍生而来的。
对于流入speed layer的数据集,有三点需要注意:
1)数据是“无限”的
2)当前处理中的数据集(工作集)可能是相关的,且同时只限制于当前数据集(即与其他数据集无关)
3)处理是基于事件的,只有被明确停止才会结束;得到的结果会立即生效并且随着新数据进入会实时更新
当前很火的流计算框架有:Storm、Spark Streaming等
Spark Streaming官网这张图就很直观的解释了什么是micro-batch processing: 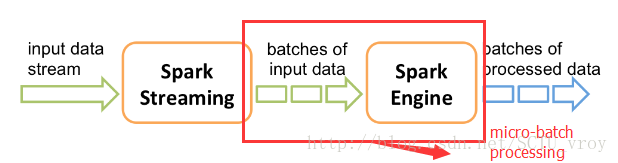
Spark Streaming还提供另一个操作:window operations(滑动窗) 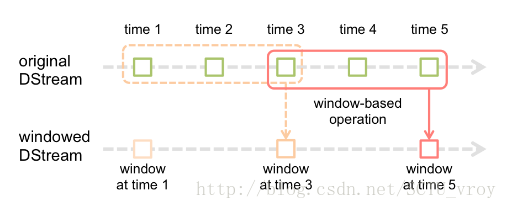
通过指定window length(窗的长度)+ sliding interval(滑动间隔),即可将数据流分成相对独立的小块,随着窗口的滑动即可分批处理流入的数据,这正是speed layer处理数据流的精髓所在
像Oryx2,batch layer和speed layer是开启两个不同的StreamingContext,从kafka消化数据做处理(Spark中,一个JVM进程只能同时存在一个streamingContext)
Others-大数据平台Lambda架构浅析(全量计算+增量计算)的更多相关文章
- 大数据平台Lambda架构详解
Lambda架构由Storm的作者Nathan Marz提出.旨在设计出一个能满足.实时大数据系统关键特性的架构,具有高容错.低延时和可扩展等特. Lambda架构整合离线计算和实时计算,融合不可变( ...
- 知名大厂如何搭建大数据平台&架构
今天我们来看一下淘宝.美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图.通过大厂的这些架构图,你就会发现,不但这些知名大厂的大数据平台设计方案大同小 ...
- Spark大型项目实战:电商用户行为分析大数据平台
本项目主要讲解了一套应用于互联网电商企业中,使用Java.Spark等技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.页面跳转行为.购物行为.广告点击行为等)进行复杂的分析.用统计分 ...
- 时间序列大数据平台建设(Time Series Data,简称TSD)
来源:https://blog.csdn.net/bluishglc/article/details/79277455 引言在大数据的生态系统里,时间序列数据(Time Series Data,简称T ...
- 大数据平台迁移实践 | Apache DolphinScheduler 在当贝大数据环境中的应用
大家下午好,我是来自当贝网络科技大数据平台的基础开发工程师 王昱翔,感谢社区的邀请来参与这次分享,关于 Apache DolphinScheduler 在当贝网络科技大数据环境中的应用. 本次演讲主要 ...
- 携程实时大数据平台演进:1/3 Storm应用已迁到JStorm
携程大数据平台负责人张翼分享携程的实时大数据平台的迭代,按照时间线介绍采用的技术以及踩过的坑.携程最初基于稳定和成熟度选择了Storm+Kafka,解决了数据共享.资源控制.监控告警.依赖管理等问题之 ...
- AI加持的阿里云飞天大数据平台技术揭秘
摘要:2019云栖大会大数据&AI专场,阿里云智能计算平台事业部研究员关涛.资深专家徐晟来为我们分享<AI加持的阿里云飞天大数据平台技术揭秘>.本文主要讲了三大部分,一是原创技术优 ...
- 电竞大数据平台 FunData 的系统架构演进
电竞大数据时代,数据对比赛的观赏性和专业性都起到了至关重要的作用.同样的,这也对电竞数据的丰富性与实时性提出了越来越高的要求. 电竞数据的丰富性从受众角度来看,可分为赛事.战队和玩家数据:从游戏角 ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
随机推荐
- Aysnc的异步执行的线程池
ProxyAsyncConfiguration.java源码: @Configuration @Role(BeanDefinition.ROLE_INFRASTRUCTURE) public clas ...
- Underscore.js(1.9.1) 封装库
// Underscore.js 1.9.1// http://underscorejs.org// (c) 2009-2018 Jeremy Ashkenas, DocumentCloud and ...
- ngx_lua_waf
Web应用防护系统Web Application Firewall,简称WAF.针对HTTP/HTTPS的安全策略专门为Web应用提供保护的产品. OpenResty是一个基于 Nginx 与 Lua ...
- 制作OpenStack云平台centos6.5镜像
创建虚拟镜像 # qemu-img create -f raw Cloud_Centos6.5_64bit.img 10G [root@localhost ~]# ll /opt/CentOS-6.5 ...
- T-SQL 事务2
启用事务完成转账存储过程 use StudentManager go if exists(select * from sysobjects where name='usp_TransferAccoun ...
- Javascript-关于for in和forEach
JS-for in:用来遍历对象 //遍历对象 for in var opts={name:'xiaofei',age:'28岁',job:'web前端工程师'} for (var k in opts ...
- OpenCV-Python基本功能
一.图像读取/保存 import cv2 img = cv2.imread("name.png") cv2.imwrite('save.jpg', img) #显示图像 cv2.i ...
- Android收发短信
效果:点击发送短信开始发送短信 收到短信时将短信的内容显示出来 代码如下: 一.权限声明 <uses-permission android:name="android.permissi ...
- Devlopment Env Setup install ubuntu16.04
http://blog.csdn.net/ljheee/article/details/52966048 1.add chinese language support settings -> i ...
- Don't afraid point
int p; int *p; int p[3]; int *p[3];分析方式:首先从P开始分析,先与[]结合因为其优先级比*高,所以p是一个数组,然后再与*结合,说明数组里的元素是指针类型,然后再与 ...