机器学习算法整理(七)支持向量机以及SMO算法实现
以下均为自己看视频做的笔记,自用,侵删!
还参考了:http://www.ai-start.com/ml2014/
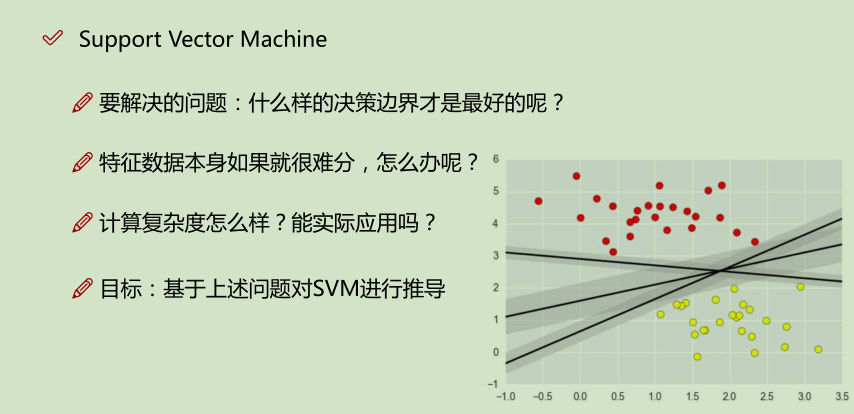
在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法A还是学习算法B,而更重要的是,应用这些算法时,所创建的大量数据在应用这些算法时,表现情况通常依赖于你的水平。比如:你为学习算法所设计的特征量的选择,以及如何选择正则化参数,诸如此类的事。还有一个更加强大的算法广泛的应用于工业界和学术界,它被称为支持向量机(Support Vector Machine)。与逻辑回归和神经网络相比,支持向量机,或者简称SVM,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
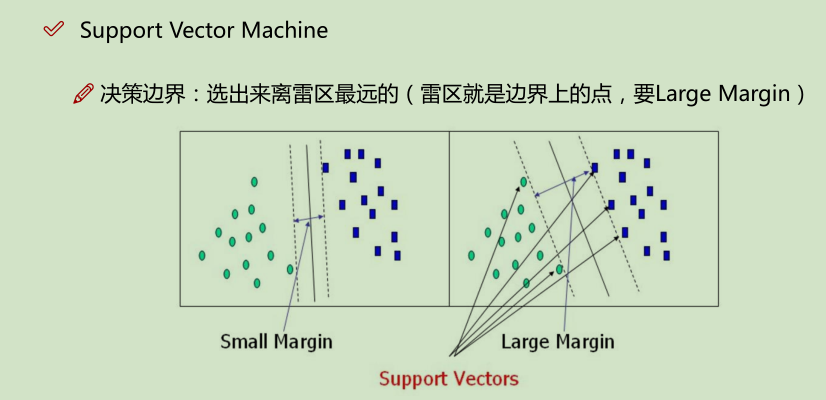
容错能力越强越好
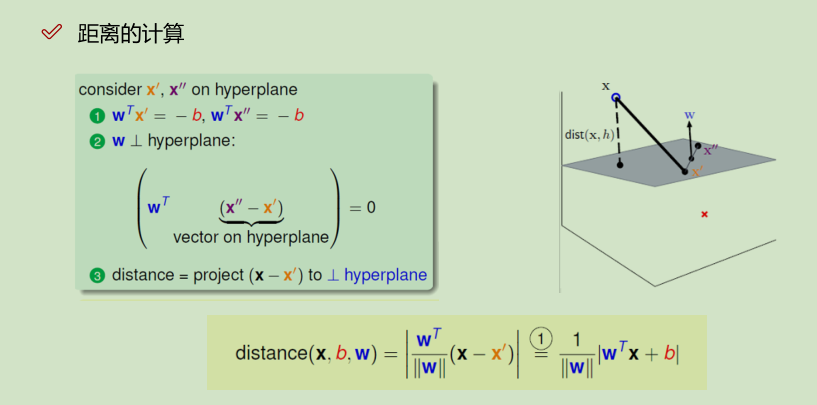
b为平面的偏正向,w为平面的法向量,x到平面的映射: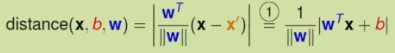



先求的是,距分界线距离最小的点;然后再求的是 什么样的w和b,使得这样的点,距离分界线的值最大。
放缩之后: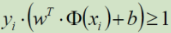 ; 又要取 其为min,即 取 yi*(w^T*Q(xi) + b) = 1 =>
; 又要取 其为min,即 取 yi*(w^T*Q(xi) + b) = 1 => 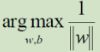


补充:

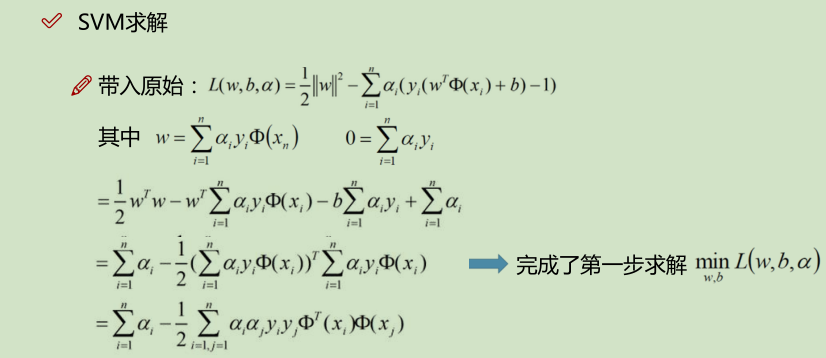

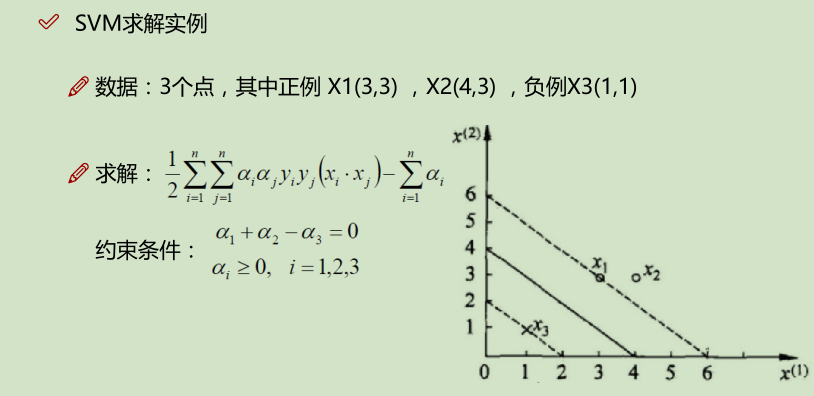
下面的 x_i · x_j 是算的内积:如,(3_i, 3_i) · (3_j, 3_j) ==> 3_i * 3_j + 3_i * 3_j = 18;


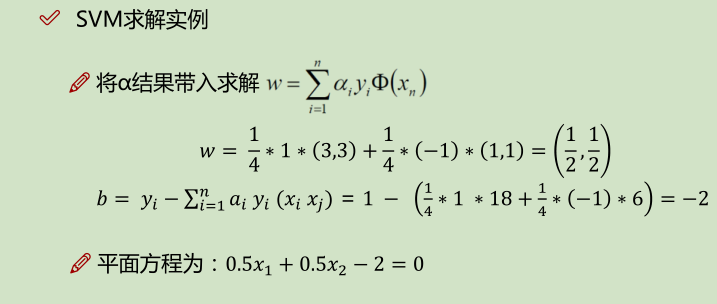
如上面实例,x2就是没有发挥作用的数据点,α为0;x1, x2就是支持向量,α不为0的点;
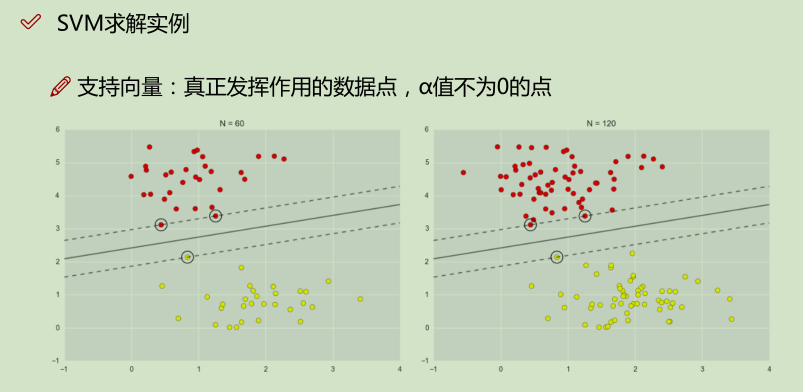
松弛因子:


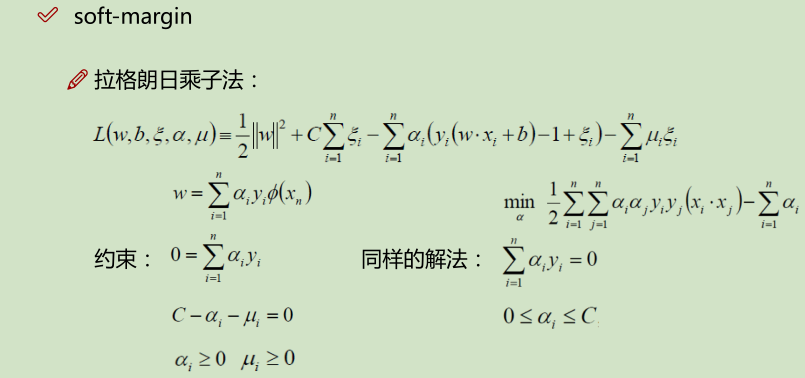
核变换:低微不可分==> 映射到高维
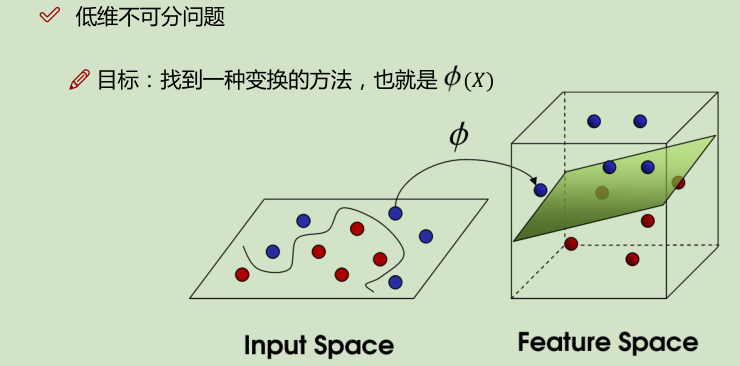
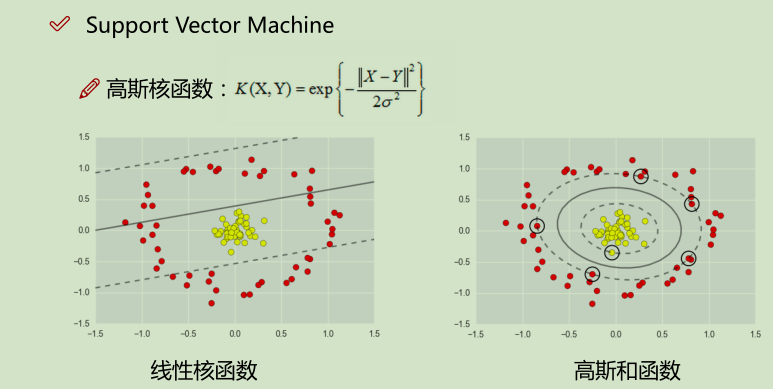
举例:

SMO算法实现:

除了α1,α2当成变量,其他的α都当成常数项。



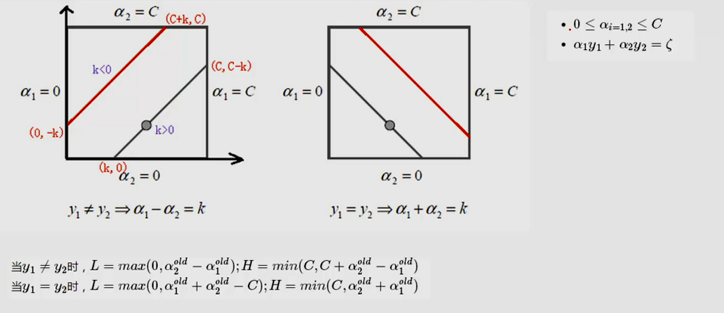
(L是取值的下界,H是取值的上界)


代码实现:
import numpy as np
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(np.random.uniform(0,m))
return j
# 控制aj的上下界
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# dataMat: 数据; classLabels: Y值; C:V值; toler:容忍程度; maxIter: 最大迭代次数
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
#初始化操作
dataMatrix = np.mat(dataMatIn); labelMat = np.mat(classLabels).transpose()
b = 0; m,n = np.shape(dataMatrix)
# 进行初始化
alphas = np.mat(np.zeros((m,1)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
# m : 数据样本数
for i in range(m):
# 先计算FXi,这里只用了线性的 kernel,相当于不变。
fXi = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])#if checks if an example violates KKT conditions
# 设置限制条件
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
#随机再选一个不等于i的数
j = selectJrand(i,m)
fXj = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
# 控制边界条件
# 定义了上(H)下(L)界取值范围
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H: print "L==H"; continue
#算出 eta = K11 + K22 - K12
#这里需要添加一个负号
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0: print "eta>=0"; continue
# 即这里就用一个减号
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
# 控制上下界
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; continue
# 算出αi
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])#update i by the same amount as j
#the update is in the oppostie direction
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
alphaPairsChanged += 1
print "iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
if (alphaPairsChanged == 0): iter += 1
else: iter = 0
print "iteration number: %d" % iter
return b,alphas
if __name__ == '__main__':
dataMat,labelMat = loadDataSet('testSet.txt')
b,alphas = smoSimple(dataMat, labelMat, 0.06, 0.01, 100)
print 'b:',b
print 'alphas',alphas[alphas>0]
SMO实例:
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
from matplotlib.colors import ListedColormap def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],alpha=0.8, c=cmap(idx),marker=markers[idx], label=cl)
# highlight test samples
if test_idx:
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0], X_test[:, 1], c='', alpha=1.0, linewidth=1, marker='o', s=55, label='test set')
from sklearn import datasets
import numpy as np
from sklearn.cross_validation import train_test_split iris = datasets.load_iris() # 由于Iris是很有名的数据集,scikit-learn已经原生自带了。
X = iris.data[:, [1, 2]]
y = iris.target # 标签已经转换成0,1,2了
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # 为了看模型在没有见过数据集上的表现,随机拿出数据集中30%的部分做测试 # 为了追求机器学习和最优化算法的最佳性能,我们将特征缩放
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train) # 估算每个特征的平均值和标准差
sc.mean_ # 查看特征的平均值,由于Iris我们只用了两个特征,所以结果是array([ 3.82857143, 1.22666667])
sc.scale_ # 查看特征的标准差,这个结果是array([ 1.79595918, 0.77769705])
X_train_std = sc.transform(X_train)
# 注意:这里我们要用同样的参数来标准化测试集,使得测试集和训练集之间有可比性
X_test_std = sc.transform(X_test)
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test)) # 导入SVC
from sklearn.svm import SVC
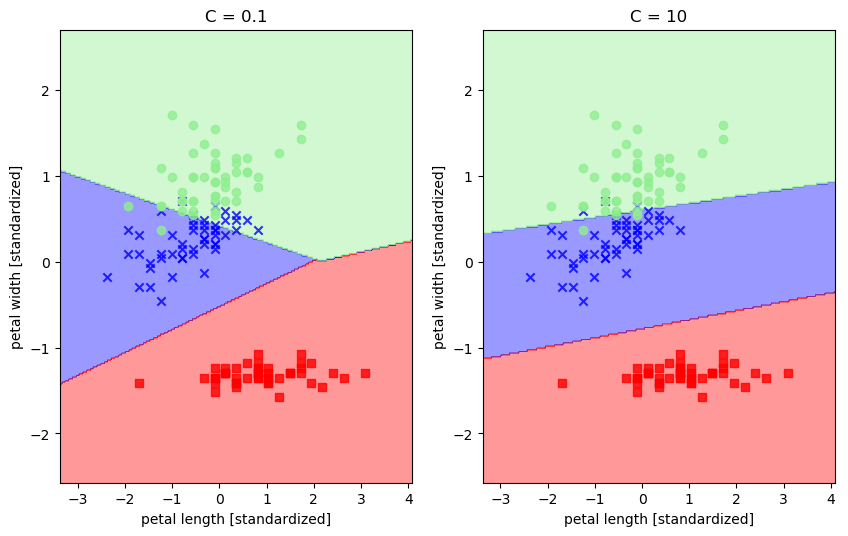
svm1 = SVC(kernel='linear', C=0.1, random_state=0) # 用线性核
svm1.fit(X_train_std, y_train) svm2 = SVC(kernel='linear', C=10, random_state=0) # 用线性核
svm2.fit(X_train_std, y_train) fig = plt.figure(figsize=(10,6))
ax1 = fig.add_subplot(1,2,1)
#ax2 = fig.add_subplot(1,2,2) plot_decision_regions(X_combined_std, y_combined, classifier=svm1)
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.title('C = 0.1') ax2 = fig.add_subplot(1,2,2)
plot_decision_regions(X_combined_std, y_combined, classifier=svm2)
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.title('C = 10') plt.show()
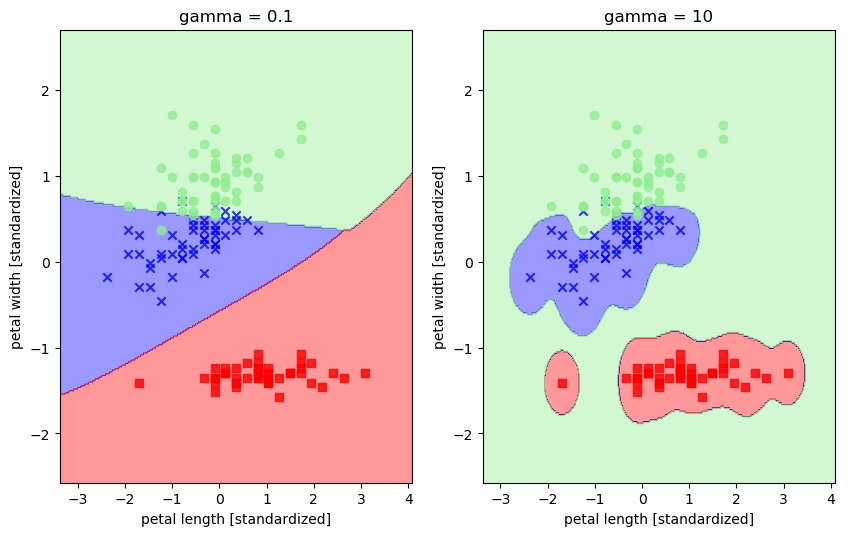
svm1 = SVC(kernel='rbf', random_state=0, gamma=0.1, C=1.0) # 令gamma参数中的x分别等于0.1和10
svm1.fit(X_train_std, y_train) svm2 = SVC(kernel='rbf', random_state=0, gamma=10, C=1.0)
svm2.fit(X_train_std, y_train) fig = plt.figure(figsize=(10,6))
ax1 = fig.add_subplot(1,2,1) plot_decision_regions(X_combined_std, y_combined, classifier=svm1)
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.title('gamma = 0.1') ax2 = fig.add_subplot(1,2,2)
plot_decision_regions(X_combined_std, y_combined, classifier=svm2)
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.title('gamma = 10') plt.show()
机器学习算法整理(七)支持向量机以及SMO算法实现的更多相关文章
- SVM-非线性支持向量机及SMO算法
SVM-非线性支持向量机及SMO算法 如果您想体验更好的阅读:请戳这里littlefish.top 线性不可分情况 线性可分问题的支持向量机学习方法,对线性不可分训练数据是不适用的,为了满足函数间隔大 ...
- [置顶]
【机器学习PAI实践七】文本分析算法实现新闻自动分类
一.背景 新闻分类是文本挖掘领域较为常见的场景.目前很多媒体或是内容生产商对于新闻这种文本的分类常常采用人肉打标的方式,消耗了大量的人力资源.本文尝试通过智能的文本挖掘算法对于新闻文本进行分类.无需任 ...
- 《机器学习_07_01_svm_硬间隔支持向量机与SMO》
一.简介 支持向量机(svm)的想法与前面介绍的感知机模型类似,找一个超平面将正负样本分开,但svm的想法要更深入了一步,它要求正负样本中离超平面最近的点的距离要尽可能的大,所以svm模型建模可以分为 ...
- 支持向量机的smo算法(MATLAB code)
建立smo.m % function [alpha,bias] = smo(X, y, C, tol) function model = smo(X, y, C, tol) % SMO: SMO al ...
- 受限玻尔兹曼机(RBM)学习笔记(七)RBM 训练算法
去年 6 月份写的博文<Yusuke Sugomori 的 C 语言 Deep Learning 程序解读>是囫囵吞枣地读完一个关于 DBN 算法的开源代码后的笔记,当时对其中涉及的算 ...
- 改进的SMO算法
S. S. Keerthi等人在Improvements to Platt's SMO Algorithm for SVM Classifier Design一文中提出了对SMO算法的改进,纵观SMO ...
- SMO算法--SVM(3)
SMO算法--SVM(3) 利用SMO算法解决这个问题: SMO算法的基本思路: SMO算法是一种启发式的算法(别管启发式这个术语, 感兴趣可了解), 如果所有变量的解都满足最优化的KKT条件, 那么 ...
- Leetcode——二叉树常考算法整理
二叉树常考算法整理 希望通过写下来自己学习历程的方式帮助自己加深对知识的理解,也帮助其他人更好地学习,少走弯路.也欢迎大家来给我的Github的Leetcode算法项目点star呀~~ 二叉树常考算法 ...
- 机器学习之支持向量机(二):SMO算法
注:关于支持向量机系列文章是借鉴大神的神作,加以自己的理解写成的:若对原作者有损请告知,我会及时处理.转载请标明来源. 序: 我在支持向量机系列中主要讲支持向量机的公式推导,第一部分讲到推出拉格朗日对 ...
随机推荐
- 软件工程第二次作业(One who wants to wear the crown, Bears the crown.)
小镓自述Eclipse使用及自动单元测试技术 因为本人对JAVA有一些兴趣,所以就决定用Eclipse来完成这次作业,从安装Eclipse到学习写代码,最后学会用Junit来进行单元测试.这段过程给我 ...
- CSS技巧收集——巧用滤镜
最近暴雪一款叫<守望先锋>的游戏火到不行,身边很多人都深受其毒害,虽然博主自己没有买(穷),但是耳濡目染也了解了个大概. 由于之前大致学习了一下 css 滤镜的各种用法,所以心血来潮结合二 ...
- Java内存区域的划分和异常
Java内存区域的划分和异常 运行时数据区域 JVM在运行Java程序时候会将内存划分为若干个不同的数据区域. 打开百度App,看更多美图 程序计数器 线程私有.可看作是当前线程所执行的字节码的行 ...
- DRF01
1.web应用模式 在web开发中有两种应用模式: 1)前后端不分离 2)前后端分离 2.api接口 为了在团队内部形成共识.防止个人习惯差异引起的混乱,我们需要找到一种大家都觉得很好的接口实现规范, ...
- openssl证书及配置
我的环境是:Linux+Apache+MySQL+PHP 1.下载openssl 及相关依赖 #yum install -y openssl 2.进入目录 /etc/pki/tls/certs #cd ...
- THE LAST ONE!! 2017《面向对象程序设计》课程作业八
THE LAST ONE!! 2017<面向对象程序设计>课程作业八 031602230 卢恺翔 GitHub传送门 题目描述 1.时间匆匆,本学期的博客作业就要结束了,是否有点不舍,是否 ...
- Java 笔记——MyBatis 生命周期
1.MyBatis 的生命周期 MyBatis的核心组件分为4个部分. SqlSessionFactoryBuilder (构造器): 它会根据配置或者代码来生成SqISessionFactory,采 ...
- [财务知识] debt debit credit 的区别于联系
https://blog.csdn.net/sjpljr/article/details/70169303 剑桥词典解释分别为: Debt [C or U ] n.something, especia ...
- Python的文件读写
目录 读文件 操作文件 读取内容 面试题的例子 写文件 操作模式 指针操作 字符编码 读文件 操作文件 打开一个文件用open()方法(open()返回一个文件对象,它是可迭代的): 文件使用完毕后必 ...
- Shell命令——文件目录
Linux只有一个文件系统树,不同的硬件设备可以挂载在不同目录下. 文件或目录有两种表示方式: - 绝对路径:从根目录”/”开始 - 相对路径:从工作目录开始,使用”..”指向父目录,”.”指向当 ...