注意机制CBAM
这是一种用于前馈卷积神经网络的简单而有效的注意模块。 给定一个中间特征图,我们的模块会沿着两个独立的维度(通道和空间)依次推断注意力图,然后将注意力图乘以输入特征图以进行自适应特征修饰。 由于CBAM是轻量级的通用模块,因此可以以可忽略的开销将其无缝集成到任何CNN架构中,并且可以与基础CNN一起进行端到端训练。
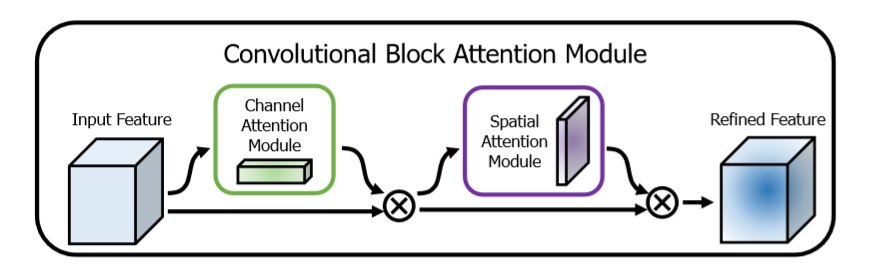
为了实现这一目标,我们依次应用频道和空间关注模块(如图1所示),以便每个分支机构都可以分别学习在频道和空间轴上参与的“内容”和“位置”。结果,我们的模块通过学习要强调或抑制的信息来有效地帮助网络中的信息流。将结果先通过通道加权模块,再通过空间位置加权模块
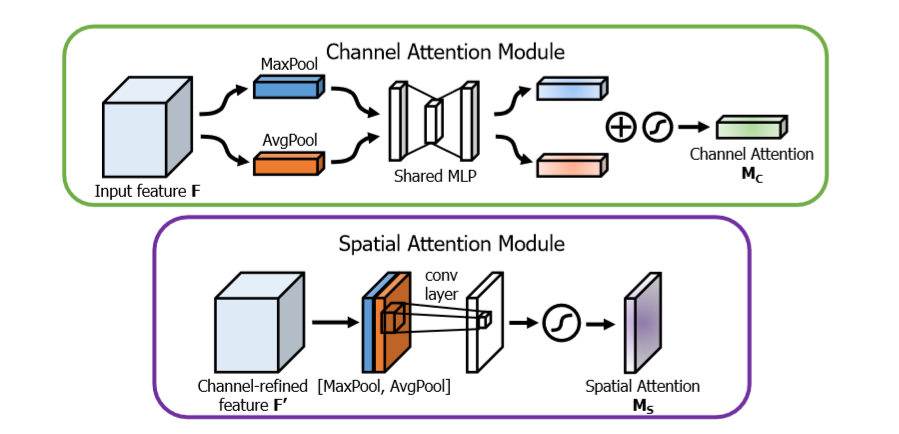
这里对网络做一个实际性的分析,
channel attention Module 主要是关注哪些通道对网络的最后输出结果起到作用,即文章中提到的‘什么’,即哪些特征对最终的预测起到了决定性的作用
channel 特征分析,输入通过一个最大值池化和均值池化
最大值池化分析:首先通过对宽度和高度进行最大值池化,然后对特征通道进行全连接,为了减少参数,这里的输出通道为 channel / 8, 下一步再进行全连接,使得输出通道为 channel。
均值池化分析:首先通过对宽度和高度进行均值池化,然后对特征通道进行全连接,为了减少参数,这里的输出通道为channel / 8, 下一步再使用全连接,使得输出通道为channel。
下一步:将两个进行加和,然后通过sigmoid进行输出,最后的结果与输入结果进行相乘操作,进行注意机制加权。
Spatial Attention Module 主要是关注哪些位置对网络的最后输出结果起到作用,即文章中提到的‘哪里’,即哪些位置信息对最终的预测起到了决定性的作用
spatial 特征分析:输入通过一个最大值池化和均值池化
最大值池化分析:对通道求取最大值池化
均值池化:对通道求取均值池化
下一步:将两个特征进行axis=3的通道串接,进行卷积操作,保证axis=3的特征数为1,进行sigmoid输出,最后结果与输入进行相乘操作,进行注意机制加权
attention_module.py
import tensorflow as tf def cbam_block(input_feature, name, ratio=8):
"""Contains the implementation of Convolutional Block Attention Module(CBAM) block.
As described in https://arxiv.org/abs/1807.06521.
""" with tf.variable_scope(name):
attention_feature = channel_attention(input_feature, 'ch_at', ratio) # 通道注意机制
attention_feature = spatial_attention(attention_feature, 'sp_at')
print("CBAM Hello")
return attention_feature def channel_attention(input_feature, name, ratio=8):
kernel_initializer = tf.contrib.layers.variance_scaling_initializer() # 通道的参数卷积初始化
bias_initializer = tf.constant_initializer(value=0.0) # 偏置的初始化 with tf.variable_scope(name):
channel = input_feature.get_shape()[-1] # 输入的通道数
avg_pool = tf.reduce_mean(input_feature, axis=[1, 2], keepdims=True) # 进行均值平均 assert avg_pool.get_shape()[1:] == (1, 1, channel)
avg_pool = tf.layers.dense(inputs=avg_pool,
units=channel // ratio,
activation=tf.nn.relu,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
name='mlp_0',
reuse=None)
assert avg_pool.get_shape()[1:] == (1, 1, channel // ratio)
avg_pool = tf.layers.dense(inputs=avg_pool,
units=channel,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
name='mlp_1',
reuse=None)
assert avg_pool.get_shape()[1:] == (1, 1, channel) max_pool = tf.reduce_max(input_feature, axis=[1, 2], keepdims=True)
assert max_pool.get_shape()[1:] == (1, 1, channel)
max_pool = tf.layers.dense(inputs=max_pool,
units=channel // ratio,
activation=tf.nn.relu,
name='mlp_0',
reuse=True)
assert max_pool.get_shape()[1:] == (1, 1, channel // ratio)
max_pool = tf.layers.dense(inputs=max_pool,
units=channel,
name='mlp_1',
reuse=True)
assert max_pool.get_shape()[1:] == (1, 1, channel) scale = tf.sigmoid(avg_pool + max_pool, 'sigmoid') return input_feature * scale def spatial_attention(input_feature, name):
kernel_size = 7
kernel_initializer = tf.contrib.layers.variance_scaling_initializer()
with tf.variable_scope(name):
avg_pool = tf.reduce_mean(input_feature, axis=[3], keepdims=True)
assert avg_pool.get_shape()[-1] == 1
max_pool = tf.reduce_max(input_feature, axis=[3], keepdims=True)
assert max_pool.get_shape()[-1] == 1
concat = tf.concat([avg_pool, max_pool], 3)
assert concat.get_shape()[-1] == 2 concat = tf.layers.conv2d(concat,
filters=1,
kernel_size=[kernel_size, kernel_size],
strides=[1, 1],
padding="same",
activation=None,
kernel_initializer=kernel_initializer,
use_bias=False,
name='conv')
assert concat.get_shape()[-1] == 1
concat = tf.sigmoid(concat, 'sigmoid') return input_feature * concat
注意机制CBAM的更多相关文章
- CVPR2021| 继SE,CBAM后的一种新的注意力机制Coordinate Attention
前言: 最近几年,注意力机制用来提升模型性能有比较好的表现,大家都用得很舒服.本文将介绍一种新提出的坐标注意力机制,这种机制解决了SE,CBAM上存在的一些问题,产生了更好的效果,而使用与SE,CBA ...
- CBAM: 卷积块注意模块
CBAM: Convolutional Block Attention Module 论文地址:https://arxiv.org/abs/1807.06521 简介:我们提出了卷积块注意模块 ( ...
- [论文理解] CBAM: Convolutional Block Attention Module
CBAM: Convolutional Block Attention Module 简介 本文利用attention机制,使得针对网络有了更好的特征表示,这种结构通过支路学习到通道间关系的权重和像素 ...
- CBAM: Convolutional Block Attention Module
1. 摘要 作者提出了一个简单但有效的注意力模块 CBAM,给定一个中间特征图,我们沿着空间和通道两个维度依次推断出注意力权重,然后与原特征图相乘来对特征进行自适应调整. 由于 CBAM 是一个轻量级 ...
- SPP、ASPP、RFB、CBAM
SPP:ASPP:将pooling 改为了 空洞卷积RFB:不同大小的卷积核和空洞卷积进行组合,认为大的卷积应该有更大的感受野. CBAM:空间和通道的注意力机制 SPP: Spatial Pyram ...
- 【注意力机制】Attention Augmented Convolutional Networks
注意力机制之Attention Augmented Convolutional Networks 原始链接:https://www.yuque.com/lart/papers/aaconv 核心内容 ...
- 笔记:Binder通信机制
TODO: 待修正 Binder简介 Binder是android系统中实现的一种高效的IPC机制,平常接触到的各种XxxManager,以及绑定Service时都在使用它进行跨进程操作. 它的实现基 ...
- JAVA回调机制(CallBack)详解
序言 最近学习java,接触到了回调机制(CallBack).初识时感觉比较混乱,而且在网上搜索到的相关的讲解,要么一言带过,要么说的比较单纯的像是给CallBack做了一个定义.当然了,我在理解了回 ...
- 谈谈DOMContentLoaded:Javascript中的domReady引入机制
一.扯淡部分 回想当年,在摆脱写页面时js全靠从各种DEMO中copy出来然后东拼西凑的幽暗岁月之后,毅然决然地打算放弃这种处处“拿来主义”的不正之风,然后开启通往高大上的“前端攻城狮”的飞升之旅.想 ...
随机推荐
- export CommonJS AMD ES6
export https://www.cnblogs.com/fayin/p/6831071.html 导入文件: a - b - c ,对象隔代消失,可转成函数返回 导入模块对象(命名) ...
- 4.Struts2-OGNL
/*ognl 是 strut2 特有的表达式,使用 ognl,struts2 就无需将对象手动放值进request等范围,页面(从值栈中)直接传值*/ OGNL <?xml version=&q ...
- element table切换分页不勾选的自带方法
场景一:没有回显勾选的情况 table表格加row-key标识选中行唯一标识,多选框加reserve-selection设置为true <template> <el-table v- ...
- Spring AOP的理解和使用
AOP是Spring框架面向切面的编程思想,AOP采用一种称为“横切”的技术,将涉及多业务流程的通用功能抽取并单独封装,形成独立的切面,在合适的时机将这些切面横向切入到业务流程指定的位置中. 掌握AO ...
- 2.Nginx基本配置
1. Nginx相关概念 代理服务器一般分为正向代理(通常直接称为代理服务器)和反向代理. 通常的代理服务器,只用于代理内部网络对Internet的连接请求,客户机必须指定代理服务器,并将本来要直接发 ...
- Zabbix 监控Windows磁盘IO
Windows下,打开cmd输入 typeperf -qx > c:\typeperf.txt #打开c:\typeperf.txt文件 windows性能计数器里面包含windows相关数值 ...
- java线程基础巩固---同步代码块以及同步方法之间的区别和关系
在上一次中[http://www.cnblogs.com/webor2006/p/8040369.html]采用同步代码块的方式来实现对线程的同步,如下: 对于同步方法我想都知道,就是将同步关键字声明 ...
- Windowsx下Appium环境搭建步骤及问题
1,安装Java jdk配置环境变量 验证方式:cmd >java -version 2,下载Android sdk配置环境变量 验证方式:cmd >adb devices(下载的是zi ...
- [易学易懂系列|rustlang语言|零基础|快速入门|(24)|实战2:命令行工具minigrep(1)]
[易学易懂系列|rustlang语言|零基础|快速入门|(24)|实战2:命令行工具minigrep(1)] 项目实战 实战2:命令行工具minigrep 有了昨天的基础,我们今天来开始另一个稍微有点 ...
- 图片框住一个小视频 谈css padding百分比自适应
今天市场提出活动页,活动页有一块内容是在一个手机背景图框里播放视频,网页是适配的,设计师只给我一张带有手机壳的背景图. 如果用JS画应该也是可以的,但一个简单的活动页没必要,快速实现用背景图调CSS最 ...