李宏毅 Gradient Descent Demo 代码讲解
何为梯度下降,直白点就是,链式求导法则,不断更新变量值。
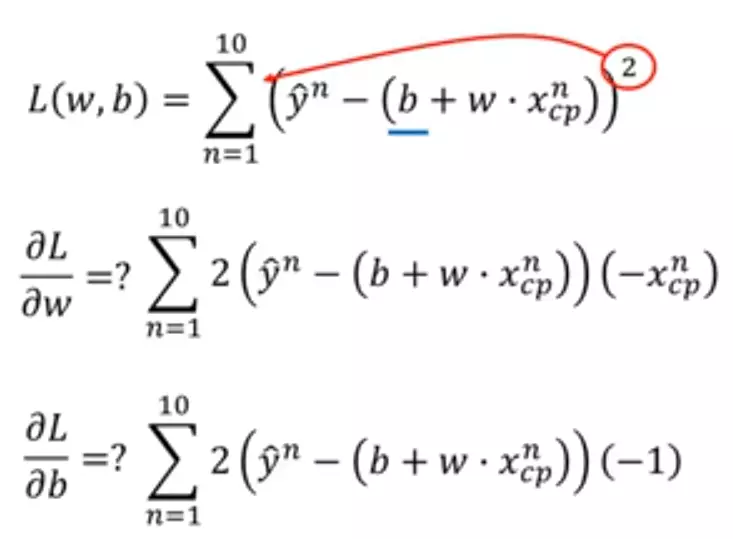
Loss函数
python代码如下
import numpy as np
import matplotlib.pyplot as plt # y_data = b + w * x_data
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.] # 10 个数
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.] # 10 个数 x = np.arange(-200, -100, 1) # bias
y = np.arange(-5, 5, 0.1) # weight
z = np.zeros((len(x), len(y))) # zeros函数表示输出的数组为 100行 100列 #X, Y = np.meshgrid(x, y) 个人感觉这句话没用。。。 for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
z[j][i] = 0
for n in range(len(x_data)):
# z[j][i]为 b=x[i] 及 w=y[j] 时,对应的 Loss Function 的大小
z[j][i] = z[j][i] + (y_data[n] - b - w * x_data[n]) ** 2
z[j][i] = z[j][i] / len(x_data) # 求 loss function 均值 # y_data = b + w * x_data
b = -120 # initial b
w = -4 # initial w
lr = 0.0000001 # learning rate
iteration = 100000 # 迭代运行次数 # store initial values for plotting
b_history = [b]
w_history = [w] # iterations
for i in range(iteration): # 在 100000 次迭代下,看最后结果
b_grad = 0.0 # 对 b_grad 重新赋值为0
w_grad = 0.0 # 对 w_grad 重新赋值为0
for n in range(len(x_data)):
# 此处应该注意的是,求导的是Loss函数,因此对应的变量是w、b,是看w、b在各自的轴上的移动
b_grad = b_grad + 2.0 * (y_data[n] - b - w * x_data[n]) * ( - 1.0)
w_grad = w_grad + 2.0 * (y_data[n] - b - w * x_data[n]) * ( - x_data[n]) # update parameters
b = b - lr * b_grad
w = w - lr * w_grad # store parameters for plotting
b_history.append(b)
w_history.append(w) # plot the figure
plt.contourf(x, y, z, 50, alpha = 0.5, cmap = plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms = 12, markeredgewidth = 3, color = 'orange')
plt.plot(b_history, w_history, 'o-', ms = 3, lw = 1.5, color = 'black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$', fontsize=16)
plt.ylabel(r'$w$', fontsize=16)
plt.show()
当learning rate 即 lr = 0.0000001时
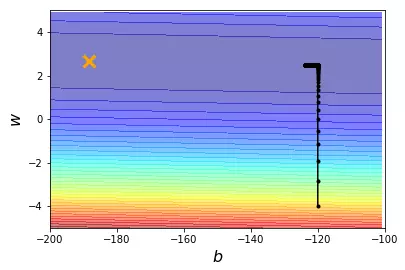
当learning rate 即 lr = 0.000001时

learning rate 即 lr = 0.00001时

可以看到效果不是很好 所以改变learning rate
import numpy as np
import matplotlib.pyplot as plt # y_data = b + w * x_data
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.] # 10 个数
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.] # 10 个数 x = np.arange(-200, -100, 1) # bias
y = np.arange(-5, 5, 0.1) # weight
z = np.zeros((len(x), len(y))) # zeros函数表示输出的数组为 100 行 100 列 # X, Y = np.meshgrid(x, y) for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
z[j][i] = 0
for n in range(len(x_data)):
# z[j][i]为 b=x[i] 及 w=y[j] 时,对应的 Loss Function 的大小
z[j][i] = z[j][i] + (y_data[n] - b - w * x_data[n]) ** 2
z[j][i] = z[j][i] / len(x_data) # 求 loss function 均值 # ydata = b + w * xdata
b = -120 # initial b
w = -4 # initial w
lr = 1 # learning rate
iteration = 100000 # 迭代运行次数 # store initial values for plotting
b_history = [b]
w_history = [w] # 个性化 w 和 b 的 learning rate
lr_b = 0
lr_w = 0 # iterations
for i in range(iteration): # 在 100000 次迭代下,看最后结果
b_grad = 0.0 # 对 b_grad 重新赋值为0
w_grad = 0.0 # 对 w_grad 重新赋值为0
for n in range(len(x_data)):
# 此处应该注意的是,求导的是L函数,因此对应的变量是w、b,是看w、b在各自的轴上的移动
b_grad = b_grad + 2.0 * (y_data[n] - b - w * x_data[n]) * (- 1.0)
w_grad = w_grad + 2.0 * (y_data[n] - b - w * x_data[n]) * (- x_data[n]) lr_b = lr_b + b_grad ** 2
lr_w = lr_w + w_grad ** 2 # update parameters
b = b - lr / np.sqrt(lr_b) * b_grad
w = w - lr / np.sqrt(lr_w) * w_grad # store parameters for plotting
b_history.append(b)
w_history.append(w) # plot the figure
plt.contourf(x, y, z, 50, alpha=0.5, cmap=plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms=12, markeredgewidth=3, color='orange')
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$', fontsize=16)
plt.ylabel(r'$w$', fontsize=16)
plt.show()
结果展示
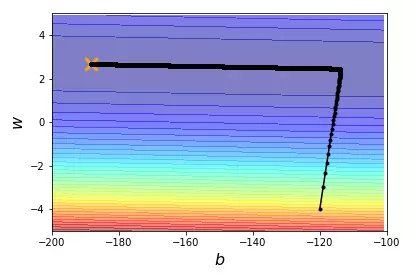
一些说明:
np.array np.asarray的区别
array和asarry都可以将结构数据转换为ndarray类型
但是主要的区别在于当数据源是ndarray时,array仍会copy出一个副本,占用新的内存,但asarray不会。
np.meshgrid的作用
生成网格点坐标矩阵
李宏毅 Gradient Descent Demo 代码讲解的更多相关文章
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- 李宏毅机器学习笔记2:Gradient Descent(附带详细的原理推导过程)
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习课程---4、Gradient Descent (如何优化 )
李宏毅机器学习课程---4.Gradient Descent (如何优化) 一.总结 一句话总结: 调整learning rates:Tuning your learning rates 随机Grad ...
- Logistic Regression Using Gradient Descent -- Binary Classification 代码实现
1. 原理 Cost function Theta 2. Python # -*- coding:utf8 -*- import numpy as np import matplotlib.pyplo ...
- Linear Regression Using Gradient Descent 代码实现
参考吴恩达<机器学习>, 进行 Octave, Python(Numpy), C++(Eigen) 的原理实现, 同时用 scikit-learn, TensorFlow, dlib 进行 ...
- 【笔记】机器学习 - 李宏毅 - 4 - Gradient Descent
梯度下降 Gradient Descent 梯度下降是一种迭代法(与最小二乘法不同),目标是解决最优化问题:\({\theta}^* = arg min_{\theta} L({\theta})\), ...
- 【论文翻译】An overiview of gradient descent optimization algorithms
这篇论文最早是一篇2016年1月16日发表在Sebastian Ruder的博客.本文主要工作是对这篇论文与李宏毅课程相关的核心部分进行翻译. 论文全文翻译: An overview of gradi ...
- 梯度下降算法实现原理(Gradient Descent)
概述 梯度下降法(Gradient Descent)是一个算法,但不是像多元线性回归那样是一个具体做回归任务的算法,而是一个非常通用的优化算法来帮助一些机器学习算法求解出最优解的,所谓的通用就是很 ...
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
随机推荐
- ORM高阶补充:only, defer,select_related
Queryset官方文档:https://docs.djangoproject.com/en/1.11/ref/models/querysets/ 1.需求1:只取某n列 1.方法1:values 2 ...
- 脚本实现PXE装机
#!/bin/bash read -p "请输入您的装机服务器:" ip read -p "请输入您想要的ip最小值(1-255):" min read -p ...
- [Python自学] day-21 (1) (请求信息、html模板继承与导入、自定义模板函数、自定义分页)
一.路由映射的参数 1.映射的一般使用 在app/urls.py中,我们定义URL与视图函数之间的映射: from django.contrib import admin from django.ur ...
- ImageSharp跨平台图片处理
添加nuget引用 SixLabors.ImageSharp 和SixLabors.ImageSharp.Drawing 暂时只实现了缩略图..<pre>using SixLabors.I ...
- Linux查看进程的启动路径——pwdx
想要找到transfer的启动路径. 一般是ps -ef | grep keyward 但是这个刚好是没有用绝对路径执行. 再用pwdx pid获得
- html页面之间相互传值
常见的在页面登录过后会获得一个token值然后页面跳转时传给下一个页面 sessionStorage.setItem("token",result.token);//传输token ...
- Codeforces 869E. The Untended Antiquity (二维Fenwick,Hash)
Codeforces 869E. The Untended Antiquity 题意: 在一张mxn的格子纸上,进行q次操作: 1,指定一个矩形将它用栅栏围起来. 2,撤掉一个已有的栅栏. 3,询问指 ...
- BUUCTF平台-web-边刷边记录-2
1.one line tool <?php if (isset($_SERVER['HTTP_X_FORWARDED_FOR'])) { $_SERVER['REMOTE_ADDR'] = $_ ...
- FreeMarker学习(常用指令)
参考:http://freemarker.foofun.cn/dgui_quickstart_basics.html assign: 使用该指令你可以创建一个新的变量, 或者替换一个已经存在的变量 a ...
- 搭建Django项目虚拟环境(Windows系统下)
一.安装virtualenv 我们可以使用正式的Python环境中的pip进行安装.进入cmd界面,运行“ pip install virtualenv ”,完成安装后,可以运行“ where vir ...