用ufile和S3代替hdfs存储数据
一,添加ufile需在配置中添加:
core-site.xml
添加如下配置:
<property>
<name>fs.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFileSystem</value>
</property>
<property>
<name>ufile.properties.file</name>
<value>/data/ufile.properties</value>
</property>
<property>
<name>fs.AbstractFileSystem.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFs</value>
</property>
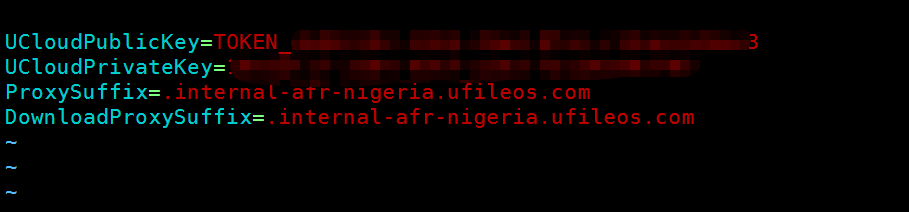
ufile.properties:
格式如下:
UCloudPublicKey=${API公钥或者TOKEN公钥}
UCloudPrivateKey=${API私钥或者TOKEN私钥}
ProxySuffix=${域名后缀} // ⻅见下⾯面域名后缀说明
DownloadProxySuffix=${域名后缀} // ⻅见下⾯面域名后缀说明
ls /data/ufile.properties
例子:
操作ufile测试:
hdfs dfs -put test.txt ufile://<bucket名>/test.txt
hdfs dfs -ls ufile://opay-datalake
<bucket名>是整段名字最前面的一段,也可点域名管理看

jar包放的目录:
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib |grep uhadoop*
uhadoop-1.0-SNAPSHOT.jar
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib |grep ufile
ufilesdk-1.0-SNAPSHOT.jar
如要使用impala,还需要在impala下放置:
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/ufile*
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/uhadoop*
scp ufilesdk-1.0-SNAPSHOT.jar 10.52.172.232:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib
scp uhadoop-1.0-SNAPSHOT.jar 10.52.172.232:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib
要hive使用ufile还需要拷到这些位置:
scp /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/udf-1.0-SNAPSHOT-jar-with-dependencies.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/
scp uhadoop-1.0-SNAPSHOT.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/
scp ufilesdk-1.0-SNAPSHOT.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib
#要用beeline,还得在下面的位置都放置两个jar包:
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/sqoop/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-hdfs/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/jars/ufilesdk-1.0-SNAPSHOT.jar
理论上讲:
读: 5G B /s 40G b/s
写: 0.56G B/s 1TB 30min
问题:
1/ 当用 orc格式插入数据,起初是14万条,后来是140万条,报错如下:

改为stored as parquet格式正常
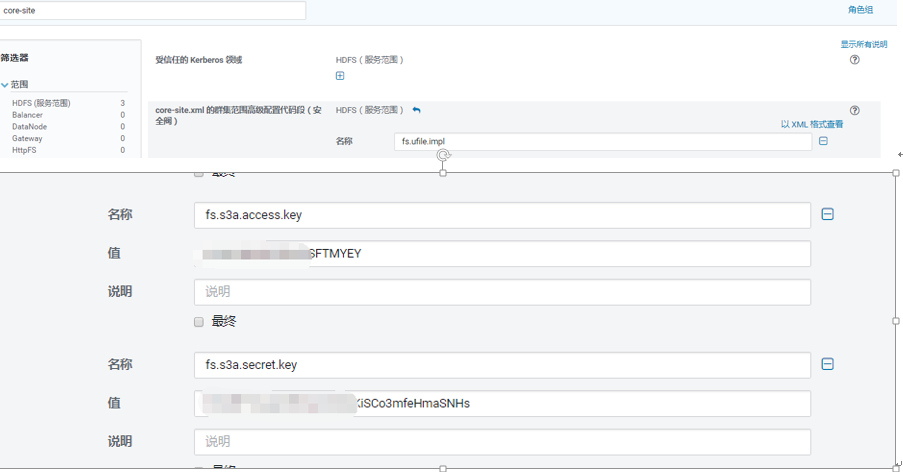
二, 添加s3的访问,因为aws的jar已经内置到了CDH,所以只需要改core-site.xml就可以了
<property>
<name>fs.AbstractFileSystem.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFs</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>AKI</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>l8IvM8s</value>
</property>
</configuration>
hadoop dfs -ls s3a://opay-bi/
#CDH要在配置中加:
参考:
https://www.cloudera.com/documentation/enterprise/6/6.2/topics/admin_s3_docs_ref.html
https://www.cloudera.com/documentation/enterprise/6/6.2/topics/admin_s3_docs_ref.html
用ufile和S3代替hdfs存储数据的更多相关文章
- Hadoop第三天---分布式文件系统HDFS(大数据存储实战)
1.开机启动Hadoop,输入命令: 检查相关进程的启动情况: 2.对Hadoop集群做一个测试: 可以看到新建的test1.txt和test2.txt已经成功地拷贝到节点上(伪分布式只有一个节 ...
- 用hdfs存储海量的视频数据的设计思路
用hdfs存储海量的视频数据 存储海量的视频数据,主要考虑两个因素:如何接收视频数据和如何存储视频数据. 我们要根据数据block在集群上的位置分配计算量,要充分利用带宽的优势. 1.接收视频数据 将 ...
- hdfs冷热数据分层存储
hdfs如何让某些数据查询快,某些数据查询慢? hdfs冷热数据分层存储 本质: 不同路径制定不同的存储策略. hdfs存储策略 hdfs的存储策略 依赖于底层的存储介质. hdfs支持的存储介质: ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- 【漫画解读】HDFS存储原理(转载)
以简洁易懂的漫画形式讲解HDFS存储机制与运行原理. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下: Client:客户端,系统使用者,调用HDFS API操作文件;与NN交互获取文件元数 ...
- QString内部仍采用UTF-16存储数据且不会改变(一共10种不同情况下的编码)
出处:https://blog.qt.io/cn/2012/05/16/source-code-must-be-utf-8-and-qstring-wants-it/ 但是注意,这只是QT运行(Run ...
- 【转】【漫画解读】HDFS存储原理
根据Maneesh Varshney的漫画改编,以简洁易懂的漫画形式讲解HDFS存储机制与运行原理. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下: Client:客户端,系统使用者,调用 ...
- 【漫画解读】HDFS存储原理
根据Maneesh Varshney的漫画改编,以简洁易懂的漫画形式讲解HDFS存储机制与运行原理,非常适合Hadoop/HDFS初学者理解. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下 ...
- Hadoop -- HDFS 读写数据
一.HDFS读写文件过程 1.读取文件过程 1) 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件 2) FileSyst ...
随机推荐
- ListView如何添加数据如何不闪烁
public class DoubleBufferListView : ListView { public DoubleBufferListView() ...
- luogu 1072 Hankson 的趣味题 唯一分解定理+线性筛
貌似是比大多数题解优的 $O(n^2logn)$ ~ Code: #include <bits/stdc++.h> #define N 50004 #define setIO(s) fre ...
- tar:文件打包归档
造冰箱的大熊猫@cnblogs 2018/12/24 1.什么是tar 1.1.tar tar命令将指定的文件.文件夹打包(存储)为一个文件(归档文件,archive file).tar将被归档文件以 ...
- luoguP1739 表达式括号匹配 x
P1739 表达式括号匹配 题目描述 假设一个表达式有英文字母(小写).运算符(+,—,*,/)和左右小(圆)括号构成,以“@”作为表达式的结束符.请编写一个程序检查表达式中的左右圆括号是否匹配,若匹 ...
- Java集合框架中底层文档的List与Set
Java集合框架中的List与Set // 简书作者:达叔小生 Collection -> Set 无序不重复 -> 无序HashSet,需要排序TreeSet -> List 有序 ...
- 使用Jmeter对观影券查询接口做性能测试
线程数:虚拟用户数.一个虚拟用户占用一个进程或线程.设置多少虚拟用户数在这里也就是设置多少个线程数. 准备时长: 设置的虚拟用户数需要多长时间全部启动.如果线程数为20 ,准备时长为10 ,那么需要1 ...
- C++入门经典-例9.3-类模板,简单类模板
1:使用template关键字不但可以定义函数模板,而且可以定义类模板.类模板代表一族类,它是用来描述通用数据类型或处理方法的机制,它使类中的一些数据成员和成员函数的参数或返回值可以取任意数据类型.类 ...
- Servlet——理解会话Session
1.什么是会话(Session) 超文本传输协议(HTTP)被设计成一种无状态的协议. 所谓无状态协议就是指在服务器端的请求彼此相互之间是不认识彼此的,哪怕是来自同一个客户端的请求,相互之间也是不认识 ...
- Node JS复制文件
/** * Created by Administrator on 2019/11/6. *指尖敲打着世界 ----一个阳光而又不失帅气的少年!!!. */ var fs=require(" ...
- JDBC的URL
JDBC的URL=协议名+子协议名+数据源名. 协议名总是“jdbc”. 子协议名由JDBC驱动程序的编写者决定. 数据源名也可能包含用户与口令等信息:这些信息也可单独提供. 几种常见的数据库连接 o ...