用ufile和S3代替hdfs存储数据
一,添加ufile需在配置中添加:
core-site.xml
添加如下配置:
<property>
<name>fs.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFileSystem</value>
</property>
<property>
<name>ufile.properties.file</name>
<value>/data/ufile.properties</value>
</property>
<property>
<name>fs.AbstractFileSystem.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFs</value>
</property>
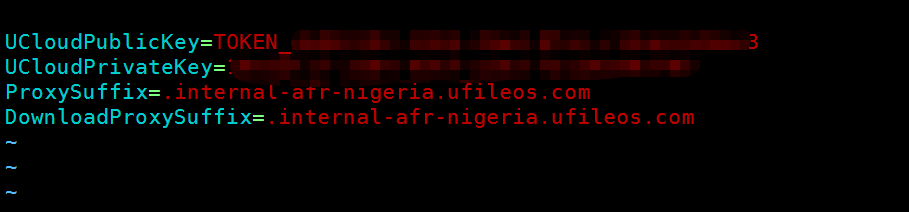
ufile.properties:
格式如下:
UCloudPublicKey=${API公钥或者TOKEN公钥}
UCloudPrivateKey=${API私钥或者TOKEN私钥}
ProxySuffix=${域名后缀} // ⻅见下⾯面域名后缀说明
DownloadProxySuffix=${域名后缀} // ⻅见下⾯面域名后缀说明
ls /data/ufile.properties
例子:
操作ufile测试:
hdfs dfs -put test.txt ufile://<bucket名>/test.txt
hdfs dfs -ls ufile://opay-datalake
<bucket名>是整段名字最前面的一段,也可点域名管理看

jar包放的目录:
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib |grep uhadoop*
uhadoop-1.0-SNAPSHOT.jar
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib |grep ufile
ufilesdk-1.0-SNAPSHOT.jar
如要使用impala,还需要在impala下放置:
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/ufile*
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/uhadoop*
scp ufilesdk-1.0-SNAPSHOT.jar 10.52.172.232:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib
scp uhadoop-1.0-SNAPSHOT.jar 10.52.172.232:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib
要hive使用ufile还需要拷到这些位置:
scp /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/udf-1.0-SNAPSHOT-jar-with-dependencies.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/
scp uhadoop-1.0-SNAPSHOT.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/
scp ufilesdk-1.0-SNAPSHOT.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib
#要用beeline,还得在下面的位置都放置两个jar包:
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/sqoop/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-hdfs/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/jars/ufilesdk-1.0-SNAPSHOT.jar
理论上讲:
读: 5G B /s 40G b/s
写: 0.56G B/s 1TB 30min
问题:
1/ 当用 orc格式插入数据,起初是14万条,后来是140万条,报错如下:

改为stored as parquet格式正常
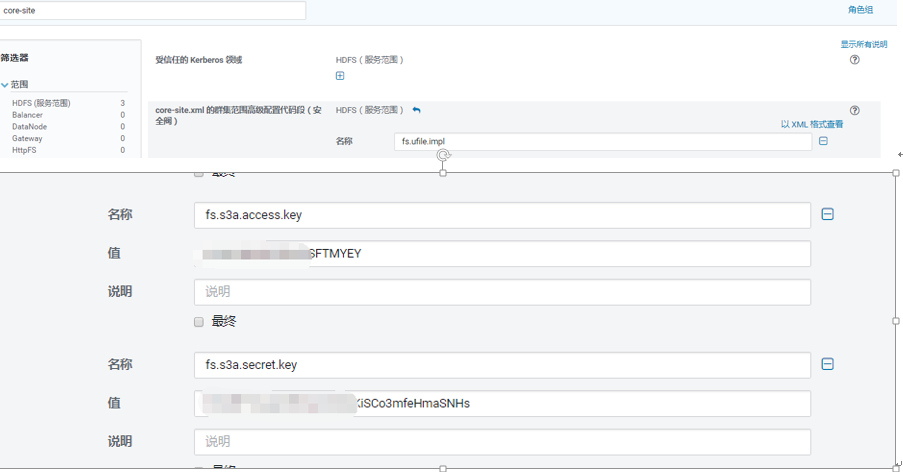
二, 添加s3的访问,因为aws的jar已经内置到了CDH,所以只需要改core-site.xml就可以了
<property>
<name>fs.AbstractFileSystem.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFs</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>AKI</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>l8IvM8s</value>
</property>
</configuration>
hadoop dfs -ls s3a://opay-bi/
#CDH要在配置中加:
参考:
https://www.cloudera.com/documentation/enterprise/6/6.2/topics/admin_s3_docs_ref.html
https://www.cloudera.com/documentation/enterprise/6/6.2/topics/admin_s3_docs_ref.html
用ufile和S3代替hdfs存储数据的更多相关文章
- Hadoop第三天---分布式文件系统HDFS(大数据存储实战)
1.开机启动Hadoop,输入命令: 检查相关进程的启动情况: 2.对Hadoop集群做一个测试: 可以看到新建的test1.txt和test2.txt已经成功地拷贝到节点上(伪分布式只有一个节 ...
- 用hdfs存储海量的视频数据的设计思路
用hdfs存储海量的视频数据 存储海量的视频数据,主要考虑两个因素:如何接收视频数据和如何存储视频数据. 我们要根据数据block在集群上的位置分配计算量,要充分利用带宽的优势. 1.接收视频数据 将 ...
- hdfs冷热数据分层存储
hdfs如何让某些数据查询快,某些数据查询慢? hdfs冷热数据分层存储 本质: 不同路径制定不同的存储策略. hdfs存储策略 hdfs的存储策略 依赖于底层的存储介质. hdfs支持的存储介质: ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- 【漫画解读】HDFS存储原理(转载)
以简洁易懂的漫画形式讲解HDFS存储机制与运行原理. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下: Client:客户端,系统使用者,调用HDFS API操作文件;与NN交互获取文件元数 ...
- QString内部仍采用UTF-16存储数据且不会改变(一共10种不同情况下的编码)
出处:https://blog.qt.io/cn/2012/05/16/source-code-must-be-utf-8-and-qstring-wants-it/ 但是注意,这只是QT运行(Run ...
- 【转】【漫画解读】HDFS存储原理
根据Maneesh Varshney的漫画改编,以简洁易懂的漫画形式讲解HDFS存储机制与运行原理. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下: Client:客户端,系统使用者,调用 ...
- 【漫画解读】HDFS存储原理
根据Maneesh Varshney的漫画改编,以简洁易懂的漫画形式讲解HDFS存储机制与运行原理,非常适合Hadoop/HDFS初学者理解. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下 ...
- Hadoop -- HDFS 读写数据
一.HDFS读写文件过程 1.读取文件过程 1) 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件 2) FileSyst ...
随机推荐
- jq load()方法实现html 模块化。
在我们写项目的时候,会遇到一个模块在多个页面使用,如果没有页面都写一次,那就太费劲了. 如果你使用了框架(vue,react,Angular)的话,那框架都有模块化,可以轻松解决. 如果你使用原生开发 ...
- 油猴Tampermonkey离线安装流程(附文件)
1.下载插件插件包,然后解压(解压到你想放插件的位置,其实任意位置都可以,记住解压的位置) 链接:https://pan.baidu.com/s/1aanhsb6ZlapnzBeBRtp3Hg 提取码 ...
- MessagePack Java 0.6.X 动态类型
我们知道 Java 是一个静态类型的语言.通过输入 Value MessagePack能够实现动态的特性. Value 有方法来检查自己的类型(isIntegerType(), isArrayType ...
- 灰度图像--图像分割 Scharr算子
学习DIP第46天 转载请标明本文出处:http://blog.csdn.net/tonyshengtan ,出于尊重文章作者的劳动,转载请标明出处!文章代码已托管,欢迎共同开发: https://g ...
- windows驱动开发详解学习笔记
1. windows驱动分两类,NT式驱动和WDM驱动,后者支持即插即用: 2. DriverEntry是入口函数,传入参数:pDriverObject由IO管理器传入: 3. WDM驱动中,AddD ...
- bootstrap单选框复选框的使用
<form role="form"> <div class="form-group"> <label class="ch ...
- webuploader的一些体验
WebUploader是由Baidu WebFE(FEX)团队开发的一个简单的以HTML5为主,FLASH为辅的现代文件上传组件.支持大文件分片并发上传. 具体api文档参考:http://fex.b ...
- template模板循环嵌套循环
template嵌套循环写法:在第一次循环里面需要循环的地方再写个循环,把要循环的数据对象改为第一层的循环对象别名 //template模板循环嵌套循环 <script id="ban ...
- ansible模块文件操作
Ansible常用模块文件操作 [root@tiandong etc]# ansible-doc -l 列出ansible所支持的模块 [root@tiandong ~]# ansible-doc ...
- Oracle、SQLServer 删除表中的重复数据,只保留一条记录
原文地址: https://blog.csdn.net/yangwenxue_admin/article/details/51742426 https://www.cnblogs.com/spring ...