基于Java+Selenium的WebUI自动化测试框架(六)---浏览器初始化
本篇我们来讨论,如何写一个浏览器初始化的类。在写之前,先思考一下,我们需要一个什么样的初始化?
先来看看使用原生的Java + selenium是怎么做的。(以firefox为例)
System.setProperty("webdriver.gecko.driver", "c:\\geckodriver.exe");
driver = new FirefoxDriver();
上面是个典型的例子,System.setProperty("webdriver驱动名",“webdriver的路径”),然后去new一个新的driver对象。这里引出一个问题,即webdriver的版本问题。
先贴两张图,后续可以继续更新维护。
ChromeDriver的
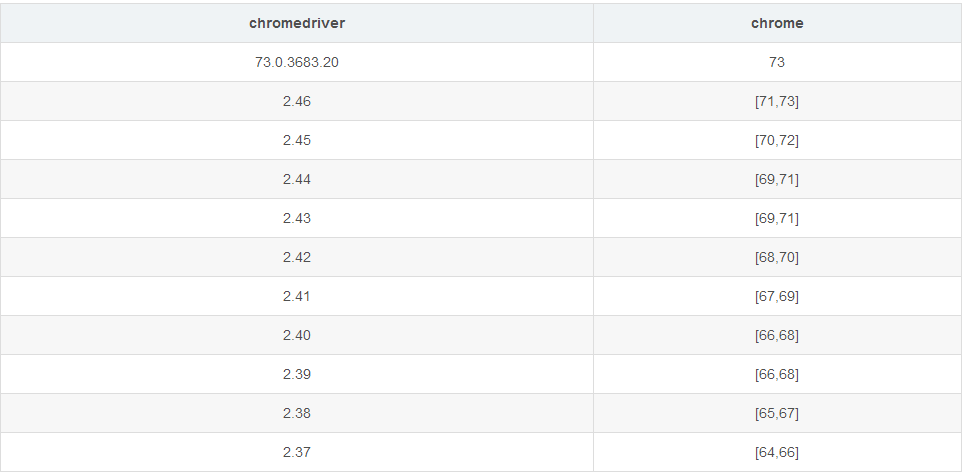
下载地址(国内淘宝镜像):https://npm.taobao.org/mirrors/chromedriver
firefox-geckodriver的
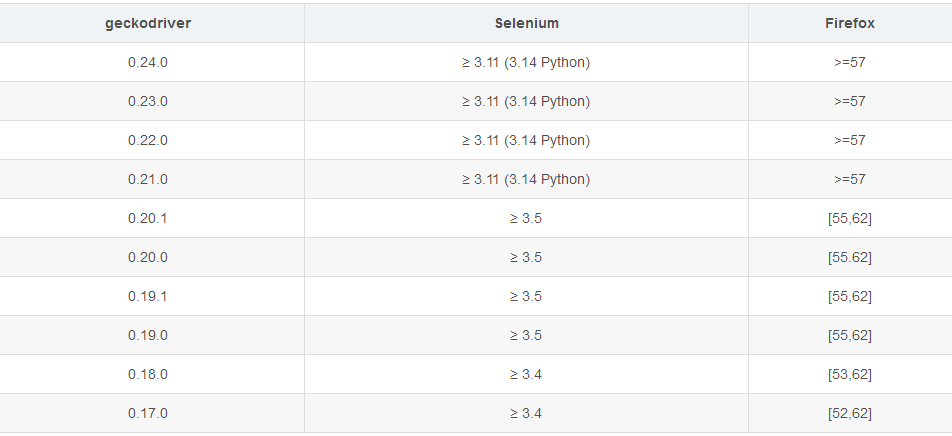
下载路径:https://github.com/mozilla/geckodriver/releases
再放一个参考网址:http://selenium-release.storage.googleapis.com/index.html
总之,我们在构建Selenium+WebDriver这套环境的时候,需要注意Selenium,WebDriver以及浏览器版本之间的对应关系。笔者自己使用的组合:
selenium-server-standalone-3.9.1
chrome浏览器 版本 76.0.3809.132(正式版本) ------->不小心升级了。。。。chromedriver版本 76.0.3809.126
firefox浏览器 63.0.1 ------->geckodriver 版本 0.24.0
PS:Chorme浏览器在70版本之后,所使用的chomedriver与浏览器版本尽量保持一致。
好了,说完浏览器与WebDriver时间的版本对应,我们就要来着手开始写浏览器初始化的代码了。
在黑盒手工测试中,我们经常说“启动XX浏览器输入XXX网址并打开”,那么浏览器初始化,我们就基本定义2个参数。一个是XX浏览器,一个XXX是网址。
package webui.xUtils; import java.util.concurrent.TimeUnit; import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxOptions;
import org.openqa.selenium.firefox.FirefoxProfile;
import org.openqa.selenium.ie.InternetExplorerDriver;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.testng.Reporter; public class browserUtil {
static WebDriver driver;
static logUtil logs = new logUtil(browserUtil.class);
@SuppressWarnings("deprecation")
public static WebDriver setDriver(String browserName,String url) {
logs.info("读取执行xml配置的"+browserName+"浏览器初始化\n");
Reporter.log("读取执行xml配置的"+browserName+"浏览器初始化\n");
switch (browserName) {
case "firefox":
//此处设置firefox的webdriver地址
System.setProperty("webdriver.gecko.driver", ".\\libs\\webdriver\\geckodriver.exe");
FirefoxProfile profile = new FirefoxProfile();
//设置成 0 代表下载到浏览器默认下载路径, 设置成 2 则可以保存到指定目录。
profile.setPreference("browser.download.folderList", 2);
profile.setPreference("browser.download.dir", ".\\firefox-download");
//browser.helperApps.neverAsk.saveToDisk
//指定要下载页面的 Content-type 值, “binary/octet-stream” 为文件的类型。
//下载的文件不同,这里的类型也会有所不一样。如果不清楚你下载的文件什么类型,请用Fiddler抓包。
profile.setPreference("browser.helperApps.neverAsk.saveToDisk", "application/vnd.ms-excel");
profile.setPreference("plugin.state.flash", 2);
FirefoxOptions options = new FirefoxOptions();
options.setProfile(profile);
driver = new FirefoxDriver(options);
driver.manage().window().maximize();
//隐式等待
// driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
logs.info("打开浏览器,访问"+url+"网址!");
Reporter.log("打开浏览器,访问"+url+"网址!");
driver.get(url);
break;
case "chrome":
System.setProperty("webdriver.chrome.driver", ".\\libs\\webdriver\\chromedriver.exe");
driver = new ChromeDriver();
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
logs.info("打开浏览器,访问"+url+"网址!");
Reporter.log("打开浏览器,访问"+url+"网址!");
driver.get(url);
break;
case "IE":
System.setProperty("webdriver.ie.driver", ".\\libs\\webdriver\\IEDriverServer32.exe");
DesiredCapabilities dc = DesiredCapabilities.internetExplorer();
dc.setCapability(InternetExplorerDriver.INTRODUCE_FLAKINESS_BY_IGNORING_SECURITY_DOMAINS, true);
dc.setCapability("ignoreProtectedModeSettings", true);
driver=new InternetExplorerDriver(dc);
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
logs.info("打开浏览器,访问"+url+"网址!");
Reporter.log("打开浏览器,访问"+url+"网址!");
driver.get(url);
break;
default:
break;
}
return driver;
} public static void quit() {
driver.quit();
}
}
在这里说两个问题。一个是有关于文件的下载,另外一个是关于IE浏览器的设置问题。
针对Firefox浏览器,我们可以参考一下的思路来进行设置。(请参考前面的红色部分代码)
先 new 一个FirefoxProfile()类,通过setPreference 设置浏览器下载类型、路径等。
参数:
browser.download.folderList
设置成 0 代表下载到浏览器默认下载路径, 设置成 2 则可以保存到指定目录。
browser.download.dir
用于指定所下载文件的目录。
browser.helperApps.neverAsk.saveToDisk
指定要下载页面的 Content-type 值, “binary/octet-stream” 为文件的类型。下载的文件不同,这里的类型也会有所不一样。如果不清楚下载的文件什么类型,请使用Fiddler抓包查看。
针对chrome浏览器,我们可以采用类似的思路。可以参考以下的代码段:
String downloadFilepath = "D:\\java";
HashMap<String, Object> chromePrefs = new HashMap<String, Object>();
chromePrefs.put("profile.default_content_settings.popups", 0);
chromePrefs.put("download.default_directory", downloadFilepath);
ChromeOptions options = new ChromeOptions();
HashMap<String, Object> chromeOptionsMap = new HashMap<String, Object>();
options.setExperimentalOption("prefs",chromePrefs);
options.addArguments("--test-type");
DesiredCapabilities cap = DesiredCapabilities.chrome();
cap.setCapability(ChromeOptions.CAPABILITY, chromeOptionsMap);
cap.setCapability(CapabilityType.ACCEPT_SSL_CERTS, true);
cap.setCapability(ChromeOptions.CAPABILITY, options); WebDriver driver = new ChromeDriver(cap); driver.get(url);
参数说明:
相比较Firefox来说,Chrome的下载默认不会弹出下载窗口的,我们主要是想修改默认的默认下载路径。
Chrome的设置看上去要比Firefox复杂一次,不过,你需要关注两个设置:
profile.default_content_settings.popups 0 设置为禁止弹出下载窗口
download.default_directory 设置为文件下载路径
下一篇我们来继续关注IE浏览器的设置。
基于Java+Selenium的WebUI自动化测试框架(六)---浏览器初始化的更多相关文章
- 基于Java+Selenium的WebUI自动化测试框架(一)---页面元素定位器
对于自动化测试,尤其是UI的自动化测试.是很多做黑盒功能测试的同学,入门自动化测试一个最为直观的或者说最容易理解的途径之一. 对于手工测试和自动化测试的优劣,网上有很多论述,在这里不作展开讨论.但是, ...
- 基于Java+Selenium的WebUI自动化测试框架(十四)-----使用TestNG的Sample
到目前为止,我们所写的东西,都是集中在如何使用Selenium和Java来定位和读取元素.那么,到底如何具体开展测试,如何实现参数化,如何实现判定呢?下面,我们来看看Java应用程序的测试框架吧. 当 ...
- 基于Java+Selenium的WebUI自动化测试框架(八)-----读取元素(XML文件)
我们继续回到自动化测试框架的主线上来,在前面的文章中,我们定义一个页面元素的主要参数有:路径,找寻方式,等待时间,名称,这个四个参数.另外,我们还需要考虑一个问题,就是网站的页面. 举个例子来说,如果 ...
- 基于Java+Selenium的WebUI自动化测试框架(九)-----基础页面类(BasePage)
上篇我们写了java读取xml文件的类,实现了可以从xml文件读取元素的方式.那么,接下来我们需要考虑一个问题.我们拿了这些元素之后怎么去操作呢? 先来看看我们手工测试的时候是怎么进行的. 双击浏览器 ...
- 基于Java+Selenium的WebUI自动化测试框架(七)--IE浏览器的设置
在上一篇我们讲了关于WebDriver的版本,浏览器初始化,以及下载的设定. 在设置IE浏览器进行WebDriver的测试时,通常会遇见以下几种错误: 1.没有关闭IE浏览器的保护模式. 当运行测试用 ...
- 基于Java+Selenium的WebUI自动化测试框架(十三)-----基础页面类BasePage(Excel)
前面,我们讲了如何使用POI进行Excel的“按需读取”.根据前面我们写的BasePageX,我们可以很轻松的写出来基于这个“按需读取”的BasePage. package webui.xUtils; ...
- 基于Java+Selenium的WebUI自动化测试框架(十)-----读取Excel文件(JXL)
之前,我们使用了读取XML文件的方式来实现页面元素的读取,并做成了基础页面类.下面,我们来进行一些扩展,通过Excel来读取页面元素. Excel的使用,大多数人应该都不陌生.那么Java读取Exce ...
- 基于Java+Selenium的WebUI自动化测试框架(五)------页面操作实现类
在编写完Log类和监听类之后,终于要回到正轨上来了.我们继续开始写UIExcutor的实现类. PS:如果你想让你的报告更加美观一些.推荐使用reportNG这个jar包. 在项目中导入reportn ...
- 基于Java+Selenium的WebUI自动化测试框架(四)-----设置监听类
基于上一篇的内容,这里我们开始写监听类Listener.我这里写监听类的思路是,继承TestListenerAdapter这个类,然后对其中的方法进行重写.网上也有很多资料,建议先学习一下,然后写出来 ...
随机推荐
- TS - 问题解决力 - 上篇
本文是已读书籍的内容摘要,少部分有轻微改动,但不影响原文表达. <麦肯锡工作法 - 个人竞争力提升50%的7堂课> ISBN: 9787508644691 https://book.dou ...
- C# 需要引用MySql.Data.dll,请在Nuget安装最新稳定版本,如果有版本兼容问题请先删除原有引用 (SqlSugar)
修改项目的app.config中的引用版本号即可
- Redis概述与基本操作
redis教程 概述 redis是一种nosql数据库,他的数据是保存在内存中,同时redis可以定时把内存数据同步到磁盘,即可以将数据持久化,并且他比memcached支持更多的数据结构(strin ...
- 【VS开发】程序如何捕捉signal函数参数中指定的信号
当说到signal的功能时,我们都知道它会捕捉我们所指定的信号,然后调用我们所指定的信号处理函数.但它是如何捕捉我们指定的信号的呢?下面我就以msdn上关于signal的example为例,说明sig ...
- linux maven环境变量配置
export MAVEN_HOME=/opt/hjyang/soft/maven export MAVEN_HOME export PATH=$PATH:$MAVEN_HOME/bin
- Hive 企业调优
9.企业级调优 9.1 Fetch 抓取 Fetch 抓取:Hive 中对某些情况的查询可以不必使用 MapReduce 计算: hive.fetch.task.conversion:more 9.2 ...
- 【转帖】kubernetes 部署ingress
kubernetes 部署ingress https://www.cnblogs.com/dingbin/p/9754993.html 明天尝试一下 之前的文档里面一直没有提 需要改host文件 我有 ...
- Python07之分支和循环2(if...else、if...elif...else)
一:if语句具体语法: if 表达式: 语句块 (表达式可以是一个布尔值或变量,也可以为一个逻辑表达式或比较表达式,表达式为真(即不为0即可,见下方实例),则运行语句块:表达式为假,则跳过语句块,继续 ...
- 【HC89S003F4开发板】9ASM写定时器1
HC89S003F4开发板ASM写定时器1 一.实现过程 1.外部寄存器设置 扩展 XSFR 采用和 XRAM 同样的访问方式,使用 MOVX A, @DPTR 和 MOVX @DPTR ,A 来进行 ...
- 案例(2)-- 线程不安全对象(SimpleDateFormat)
问题描述: 1.系统偶发性抛出异常:java.lang.NumberFormatException: multiple points ,追溯源头抛出的类为:SimpleDateFormat 问题的定位 ...