单体JOB向分布式JOB迁移案例
一、背景
1.1前言
相信大家在工作中多多少少都离不开定时任务吧,每个公司对定时任务的具体实现都不同。在一些体量小的公司或者一些个人独立项目,服务可能还是单体的,并且在服务器上只有一台实例部署,大多数会采用spring原生注解@Scheduled配合 @EnableScheduling 使用,这也足够了。
稍大一点的项目可能采用分布式部署架构,这时候再使用原来的做法就不合适了,通常一点的做法是将其中一台服务器抽出来独立的作为定时任务部署,这样来说成本最低,实现也最为简单。
下面给大家看一个经典的单体job服务案例。
1.2项目介绍
首先。我们job服务使用了quartz作为定时任务框架,接着使用一张schedule_job表,表中记录了所有我们需要定时任务的相关信息,包括cron表达式,执行的bean名称,执行的方法名,是否激活,备注等相关信息。
CREATE TABLE `schedule_job` (
`job_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '任务id',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`bean_name` varchar(200) DEFAULT NULL COMMENT 'spring bean名称',
`method_name` varchar(100) DEFAULT NULL COMMENT '方法名',
`params` varchar(2000) CHARACTER SET utf8mb4 DEFAULT NULL,
`cron_expression` varchar(100) DEFAULT NULL COMMENT 'cron表达式',
`status` tinyint(4) DEFAULT NULL COMMENT '任务状态 0:正常 1:暂停',
`remark` varchar(255) DEFAULT NULL COMMENT '备注',
`test_params` text COMMENT '测试用户测试条件',
PRIMARY KEY (`job_id`)
) ENGINE=InnoDB AUTO_INCREMENT=138 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;接下来,我们在项目启动后扫描这张表,将所有激活的定时任务的bean信息和method信息通过反射的方式注册进入quartz。
@Component
@Slf4j
public class ScheduleConfigBean {
@Autowired
private Scheduler scheduler;
@Autowired
private ScheduleJobService scheduleJobService;
/**
* 项目启动时,初始化定时器
*/
@PostConstruct
public void init() {
List<ScheduleJobEntity> scheduleJobList = scheduleJobService.selectList();
for (ScheduleJobEntity scheduleJob : scheduleJobList) {
CronTrigger cronTrigger = getCronTrigger(scheduler, scheduleJob.getJobId());
log.info("初始化 job " + scheduleJob.getBeanName() + "." + scheduleJob.getMethodName());
//如果不存在,则创建
if (cronTrigger == null) {
ScheduleUtils.createScheduleJob(scheduler, scheduleJob);
} else {
ScheduleUtils.updateScheduleJob(scheduler, scheduleJob);
}
}
}
}
public void createScheduleJob(Scheduler scheduler, ScheduleJobEntity scheduleJob) {
try {
//构建job信息
JobDetail jobDetail = JobBuilder.newJob(ScheduleJob.class).withIdentity(getJobKey(scheduleJob.getJobId())).build();
//表达式调度构建器
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule(scheduleJob.getCronExpression())
.withMisfireHandlingInstructionDoNothing();
//按新的cronExpression表达式构建一个新的trigger
CronTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity(getTriggerKey(scheduleJob.getJobId()))
.withSchedule(scheduleBuilder).build();
//放入参数,运行时的方法可以获取
jobDetail.getJobDataMap().put(ScheduleJobEntity.JOB_PARAM_KEY, scheduleJob);
scheduler.deleteJob(getJobKey(scheduleJob.getJobId()));
scheduler.scheduleJob(jobDetail, trigger);
//暂停任务
if (scheduleJob.getStatus() == Constant.ScheduleStatus.PAUSE.getValue()
||scheduleJob.getStatus() == Constant.ScheduleStatus.MIGREATE.getValue()) {
pauseJob(scheduler, scheduleJob.getJobId());
}
} catch (Exception e) {
throw new EBException("创建定时任务失败", e);
}
}这样,我们就可以通过操作表的方式灵活的去控制定时任务的创建和删除,并且可以灵活修改cron表达式,无需修改项目代码,非常适合单体服务,但是同样也十分适合作为单体式的项目部署。但是,他同样也存在着许多问题。
首先,任务是独立运行在job上的,这导致他需要拥有几乎所有的业务代码,而这些往往可以是属于不同服务的,比如说后台服务,前台服务,虽然他们没有做成微服务的形式,但是他们可以分布式部署,job服务要拥有他们两个所有的代码保证业务的连贯。
还有就是单体风险,分布式部署带来的一大好处就是避免单节点宕机带来的整个服务崩溃,也能重复利用多个机器的资源。对于一些大任务来说,单台服务的瓶颈还是很致命的,特别是任务运行不够透明。实际上我们虽然有一些类似于schedule_job_log表之类的可以观测,但是毕竟不够细致,也不能手动触发任务。
随着公司业务开展,原有的job体系已经逐渐不能满足实际的业务开发需求,我们需要寻找一种新的解决方案。随着我们的调研,我们选中了xxl-job作为我们新的job框架,至于xxl-job的使用及特性好处,这里就不展开讲了,相关的文章网上也有很多,下面讲讲我们是如何进行job迁移的。
二、实践
2.1xxl-job搭建和接入
先附上xxl-job的官网地址,以示尊敬。
https://www.xuxueli.com/xxl-job/
下面快速过一下搭建接入流程,官网讲的很详细。
1.admin搭建
第一步:下载相关源码
https://github.com/xuxueli/xxl-job
第二步:初始化相关数据库脚本
/xxl-job/doc/db/tables_xxl_job.sql
第三步:根据自己的需求配置编译并打包,部署到自己的服务器中
2.服务接入
第一步:引入相关依赖
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.4.0</version>
</dependency>第二步:增加配置文件配置
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=xxl-job-executor-sample
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30第三步:编写配置类
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}第四步:部署项目
至此,我们已经完成了xxl-job的服务端的部署和客户端的接入工作呢,接下来只要打上@XxlJob注解那我们就能成功使用xxl-job为我们提供的服务了,那这样的话本文的意义就不大了,因为网上接入使用xxl-job的教程太多了,本文不使用@XxlJob注解,而是采取了另一种最小入侵,开发无感的方式接入,下面,我们来具体看看到底是如何做的。
2.2xxl-job新的接入方式
分析:
考虑到我们公司目前处于业务高速迭代期,代码变更迅速且上线周期短,如果采取一个个加注解的形式则会产生大量的冲突,且我们的定时任务数量繁多且散落,不宜找全。一旦遗漏可能短时间难以发现,但是却会造成严重的系统不可知问题。除此之外,我们也要花费很多额外的沟通成本去和每个开发同步,实在是问题多多。这个时候,我们再探索是否能有一种基于目前项目基础,无侵入性,减少代码变更及沟通成本的方法,安全稳定的将我们原有的任务迁移过去呢?
分析我们目前的处境及我们想要完成的目标,核心就在于我们不想使用@XxlJob注解而已,如果不用这个注解,我们是否有替代的方案?为此,我们先研究一下xxl-job客户端是如何注册连接上服务端,@XxlJob在其中扮演了什么角色。
客户端启动流程:
在spring环境中,客户端将XxlJobSpringExecutor注入spring容器之中,他就是我们的任务执行器。这个bean实现了SmartInitializingSingleton接口,当 Spring 容器中的所有单例 Bean都完成了初始化后,容器会回调实现了 SmartInitializingSingleton 接口的 Bean 的 afterSingletonsInstantiated 方法。
@Override
public void afterSingletonsInstantiated() {
// init JobHandler Repository
/*initJobHandlerRepository(applicationContext);*/
// init JobHandler Repository (for method)
//初始化调度器资源管理器(从spring容器中找出@XxlJob注解的方法,装载到map里)
initJobHandlerMethodRepository(applicationContext);
// 刷新Glue工厂
GlueFactory.refreshInstance(1);
// super start
try {
//启动服务,接收服务器请求
super.start();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
其实他为我们做了三件事
1.初始化调度器资源管理器从(spring容器中找出XxlJob注解的方法,装载到map里)
2.刷新Glue工厂
3.启动服务,接收服务器请求
我们着重看一下initJobHandlerMethodRepository(applicationContext)方法,看看XxlJob注解其中扮演了什么样的角色。
private void initJobHandlerMethodRepository(ApplicationContext applicationContext) {
if (applicationContext == null) {
return;
}
// init job handler from method
String[] beanDefinitionNames = applicationContext.getBeanNamesForType(Object.class, false, true);
for (String beanDefinitionName : beanDefinitionNames) {
// get bean
Object bean = null;
Lazy onBean = applicationContext.findAnnotationOnBean(beanDefinitionName, Lazy.class);
if (onBean!=null){
logger.debug("xxl-job annotation scan, skip @Lazy Bean:{}", beanDefinitionName);
continue;
}else {
bean = applicationContext.getBean(beanDefinitionName);
}
// filter method
//这就是装载了被XxlJob注解标记的方法和对应注解的map
Map<Method, XxlJob> annotatedMethods = null; // referred to :org.springframework.context.event.EventListenerMethodProcessor.processBean
try {
annotatedMethods = MethodIntrospector.selectMethods(bean.getClass(),
new MethodIntrospector.MetadataLookup<XxlJob>() {
@Override
public XxlJob inspect(Method method) {
return AnnotatedElementUtils.findMergedAnnotation(method, XxlJob.class);
}
});
} catch (Throwable ex) {
logger.error("xxl-job method-jobhandler resolve error for bean[" + beanDefinitionName + "].", ex);
}
if (annotatedMethods==null || annotatedMethods.isEmpty()) {
continue;
}
// generate and regist method job handler
for (Map.Entry<Method, XxlJob> methodXxlJobEntry : annotatedMethods.entrySet()) {
Method executeMethod = methodXxlJobEntry.getKey();
XxlJob xxlJob = methodXxlJobEntry.getValue();
// 注册方法
registJobHandler(xxlJob, bean, executeMethod);
}
}
}这个方法就是扫描spring容器,找出所有加上了@xxlJob注解的方法,然后将这个合并后的注解、相关bean、对应的方法注册进去,我们再跟进去看一下具体的注册方法,进一步揭露@xxlJob注解的秘密。
private static ConcurrentMap<String, IJobHandler> jobHandlerRepository = new ConcurrentHashMap<String, IJobHandler>();
protected void registJobHandler(XxlJob xxlJob, Object bean, Method executeMethod){
if (xxlJob == null) {
return;
}
//这个就是jobhandler的名字
String name = xxlJob.value();
//make and simplify the variables since they'll be called several times later
Class<?> clazz = bean.getClass();
String methodName = executeMethod.getName();
if (name.trim().length() == 0) {
throw new RuntimeException("xxl-job method-jobhandler name invalid, for[" + clazz + "#" + methodName + "] .");
}
if (loadJobHandler(name) != null) {
throw new RuntimeException("xxl-job jobhandler[" + name + "] naming conflicts.");
}
// execute method
/*if (!(method.getParameterTypes().length == 1 && method.getParameterTypes()[0].isAssignableFrom(String.class))) {
throw new RuntimeException("xxl-job method-jobhandler param-classtype invalid, for[" + bean.getClass() + "#" + method.getName() + "] , " +
"The correct method format like \" public ReturnT<String> execute(String param) \" .");
}
if (!method.getReturnType().isAssignableFrom(ReturnT.class)) {
throw new RuntimeException("xxl-job method-jobhandler return-classtype invalid, for[" + bean.getClass() + "#" + method.getName() + "] , " +
"The correct method format like \" public ReturnT<String> execute(String param) \" .");
}*/
//打开权限
executeMethod.setAccessible(true);
// init and destroy
Method initMethod = null;
Method destroyMethod = null;
if (xxlJob.init().trim().length() > 0) {
try {
initMethod = clazz.getDeclaredMethod(xxlJob.init());
initMethod.setAccessible(true);
} catch (NoSuchMethodException e) {
throw new RuntimeException("xxl-job method-jobhandler initMethod invalid, for[" + clazz + "#" + methodName + "] .");
}
}
if (xxlJob.destroy().trim().length() > 0) {
try {
destroyMethod = clazz.getDeclaredMethod(xxlJob.destroy());
destroyMethod.setAccessible(true);
} catch (NoSuchMethodException e) {
throw new RuntimeException("xxl-job method-jobhandler destroyMethod invalid, for[" + clazz + "#" + methodName + "] .");
}
}
// registry jobhandler
//继续注册JobHandler
registJobHandler(name, new MethodJobHandler(bean, executeMethod, initMethod, destroyMethod));
}
public static IJobHandler registJobHandler(String name, IJobHandler jobHandler){
logger.info(">>>>>>>>>>> xxl-job register jobhandler success, name:{}, jobHandler:{}", name, jobHandler);
return jobHandlerRepository.put(name, jobHandler);
}这段代码就是取出对应的注解标记的init方法destroy方法,如果存在,进一步注册为JobHandler,其实所谓的注册为JobHandler也就是帮他们包装为一个MethodJobHandler,然后将其放在key为jobhandler的名字,value为MethodJobHandler的的map中。
自此,@xxlJob注解的所有作用我们都已经找到了,无非就是通过他作为标记去spring中扫描到我们想要的bean和方法罢了。并附带上相应的信息,如果说我们这些信息都能提供呢?是不是我们就不再需要他了,还是以我们自己的方式实现注册了?再回顾一下我们已有的资料,我们的schedule_job表中已经有了bean和method的相关信息,至于JobHandler的名字,我们完全可以用bean和method去组合一个不重复的名字。这似乎可行。
但是,问题又来了。@xxlJob注解注解这个问题我们已经解决了。下一个问题是我们要在控制台上去吧所有的jobhandler添加上,并指定cron表达式,路由策略等。既然已经做到了这个程度,有没有能一劳永逸的方法能将这个步骤也都实现呢?上面也说了,我们的任务很多,会有添加遗漏的风险,而且一个个配置出错的可能性也很大,况且cron表达式我们明明表中也有,自己一个个配是不是太麻烦了,能不能从表里读呢?
那我们不妨研究一下xxl-job是如何给我们添加任务的?
xxl-job添加任务流程:
通过实验,发现xxl-job添加任务的接口是xxl-job-admin/jobinfo/add,那我们就看看这个接口做了什么好了。
@Override
public ReturnT<String> add(XxlJobInfo jobInfo) {
// valid base
XxlJobGroup group = xxlJobGroupDao.load(jobInfo.getJobGroup());
if (group == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("system_please_choose")+I18nUtil.getString("jobinfo_field_jobgroup")) );
}
if (jobInfo.getJobDesc()==null || jobInfo.getJobDesc().trim().length()==0) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("system_please_input")+I18nUtil.getString("jobinfo_field_jobdesc")) );
}
if (jobInfo.getAuthor()==null || jobInfo.getAuthor().trim().length()==0) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("system_please_input")+I18nUtil.getString("jobinfo_field_author")) );
}
// valid trigger
ScheduleTypeEnum scheduleTypeEnum = ScheduleTypeEnum.match(jobInfo.getScheduleType(), null);
if (scheduleTypeEnum == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("schedule_type")+I18nUtil.getString("system_unvalid")) );
}
if (scheduleTypeEnum == ScheduleTypeEnum.CRON) {
if (jobInfo.getScheduleConf()==null || !CronExpression.isValidExpression(jobInfo.getScheduleConf())) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "Cron"+I18nUtil.getString("system_unvalid"));
}
} else if (scheduleTypeEnum == ScheduleTypeEnum.FIX_RATE/* || scheduleTypeEnum == ScheduleTypeEnum.FIX_DELAY*/) {
if (jobInfo.getScheduleConf() == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("schedule_type")) );
}
try {
int fixSecond = Integer.valueOf(jobInfo.getScheduleConf());
if (fixSecond < 1) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("schedule_type")+I18nUtil.getString("system_unvalid")) );
}
} catch (Exception e) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("schedule_type")+I18nUtil.getString("system_unvalid")) );
}
}
// valid job
if (GlueTypeEnum.match(jobInfo.getGlueType()) == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("jobinfo_field_gluetype")+I18nUtil.getString("system_unvalid")) );
}
if (GlueTypeEnum.BEAN==GlueTypeEnum.match(jobInfo.getGlueType()) && (jobInfo.getExecutorHandler()==null || jobInfo.getExecutorHandler().trim().length()==0) ) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("system_please_input")+"JobHandler") );
}
// 》fix "\r" in shell
if (GlueTypeEnum.GLUE_SHELL==GlueTypeEnum.match(jobInfo.getGlueType()) && jobInfo.getGlueSource()!=null) {
jobInfo.setGlueSource(jobInfo.getGlueSource().replaceAll("\r", ""));
}
// valid advanced
if (ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null) == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("jobinfo_field_executorRouteStrategy")+I18nUtil.getString("system_unvalid")) );
}
if (MisfireStrategyEnum.match(jobInfo.getMisfireStrategy(), null) == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("misfire_strategy")+I18nUtil.getString("system_unvalid")) );
}
if (ExecutorBlockStrategyEnum.match(jobInfo.getExecutorBlockStrategy(), null) == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("jobinfo_field_executorBlockStrategy")+I18nUtil.getString("system_unvalid")) );
}
// 》ChildJobId valid
if (jobInfo.getChildJobId()!=null && jobInfo.getChildJobId().trim().length()>0) {
String[] childJobIds = jobInfo.getChildJobId().split(",");
for (String childJobIdItem: childJobIds) {
if (childJobIdItem!=null && childJobIdItem.trim().length()>0 && isNumeric(childJobIdItem)) {
XxlJobInfo childJobInfo = xxlJobInfoDao.loadById(Integer.parseInt(childJobIdItem));
if (childJobInfo==null) {
return new ReturnT<String>(ReturnT.FAIL_CODE,
MessageFormat.format((I18nUtil.getString("jobinfo_field_childJobId")+"({0})"+I18nUtil.getString("system_not_found")), childJobIdItem));
}
} else {
return new ReturnT<String>(ReturnT.FAIL_CODE,
MessageFormat.format((I18nUtil.getString("jobinfo_field_childJobId")+"({0})"+I18nUtil.getString("system_unvalid")), childJobIdItem));
}
}
// join , avoid "xxx,,"
String temp = "";
for (String item:childJobIds) {
temp += item + ",";
}
temp = temp.substring(0, temp.length()-1);
jobInfo.setChildJobId(temp);
}
// add in db
jobInfo.setAddTime(new Date());
jobInfo.setUpdateTime(new Date());
jobInfo.setGlueUpdatetime(new Date());
xxlJobInfoDao.save(jobInfo);
if (jobInfo.getId() < 1) {
return new ReturnT<String>(ReturnT.FAIL_CODE, (I18nUtil.getString("jobinfo_field_add")+I18nUtil.getString("system_fail")) );
}
return new ReturnT<String>(String.valueOf(jobInfo.getId()));
}简单来说,他就是给我们插入了一条jobInfo信息而已,但是他需要我们已经有了XxlJobGroup,大部分情况这个我们都会用默认的,那我们就创建一个默认的分组好了。我们只要在xxljob控制后台提前创建好一个执行器就算OK了。然后我们只需要根据规则来生成jobInfo,那我们不就可以不用手动一个个创建了,好像该有的信息我们都可以从schedule_job表中获取,一些其他的值给个默认的就好了,我们来试试看。
首先我们把依赖、XxlJobConfig配置类、控制后台部署好,提前将一些xxljob自带的表导入我们的工程,主要是xxl_job_info和xxl_job_group,因为我们待会要操作这两张表,封装好dao和service即可。我们将一些前置工作都准备好,然后准备开始编写我们的核心代码。
模拟注册任务添加流程:
@Component("xxlTestJob")
@Slf4j
public class XxlTestJob implements SmartInitializingSingleton {
@Autowired
private ApplicationContext context;
@Autowired
private ScheduleJobMapper scheduleJobMapper;
@Autowired
private XxlJobInfoService jobInfoService;
@Autowired
private XxlJobGroupService jobGroupService;
@Autowired
private XXlJobHandlerRepository xlJobHandlerRepository;
public void init() throws Exception {
LambdaQueryWrapper<ScheduleJobEntity> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(ScheduleJobEntity::getStatus,2);
List<XxlJobInfo> jobInfos = scheduleJobMapper.selectList(wrapper).stream().map(this::convert).toList();
for (XxlJobInfo jobInfo : jobInfos) {
String[] split = jobInfo.getExecutorHandler().split("->");
String beanName = split[0];
String methodName = split[1];
try {
Object handler = context.getBean(beanName);
Method method = handler.getClass().getMethod(methodName);
XxlJob xxlJob = AnnotationUtils.synthesizeAnnotation(
Collections.singletonMap("value", jobInfo.getExecutorHandler()), XxlJob.class, null);
registJobHandler(xxlJob, handler, method);
log.info("{}注册完成", jobInfo.getExecutorHandler());
} catch (NoSuchBeanDefinitionException e) {
log.info("没有这个bean{}", beanName);
continue;
} catch (NoSuchMethodException e){
log.info("bean{}方法{}", beanName,methodName);
}
XxlJobInfo existInfo = jobInfoService.lambdaQuery()
.eq(XxlJobInfo::getExecutorHandler, jobInfo.getExecutorHandler())
.one();
if (existInfo != null) {
existInfo.setScheduleConf(jobInfo.getScheduleConf());
existInfo.setTriggerStatus(jobInfo.getTriggerStatus());
existInfo.setExecutorParam(jobInfo.getExecutorParam());
jobInfoService.updateById(existInfo);
log.info("更新job完成->{}", existInfo);
} else {
jobInfoService.save(jobInfo);
log.info("添加job完成->{}", jobInfo);
}
}
}
private XxlJobInfo convert(ScheduleJobEntity scheduleJob) {
XxlJobInfo jobInfo = new XxlJobInfo();
XxlJobGroup xxlJobGroup = jobGroupService.list().get(0);
jobInfo.setJobGroup(xxlJobGroup.getId());
jobInfo.setJobDesc(StringUtil.isNotBlank(scheduleJob.getRemark()) ? scheduleJob.getRemark() : "暂无备注");
jobInfo.setAddTime(new Date());
jobInfo.setUpdateTime(new Date());
jobInfo.setAuthor("xxx");
jobInfo.setScheduleType("CRON");
jobInfo.setScheduleConf(scheduleJob.getCronExpression());
jobInfo.setMisfireStrategy("DO_NOTHING");
jobInfo.setExecutorHandler(scheduleJob.getBeanName() + "->" + scheduleJob.getMethodName());
jobInfo.setExecutorBlockStrategy("SERIAL_EXECUTION");
jobInfo.setExecutorTimeout(0);
jobInfo.setExecutorFailRetryCount(0);
jobInfo.setGlueType("BEAN");
jobInfo.setGlueRemark("GLUE代码初始化");
jobInfo.setGlueUpdatetime(new Date());
jobInfo.setExecutorRouteStrategy("FIRST");
// if ("notJob".equals(scheduleJob.getCronExpression())
// || StringUtils.isBlank(scheduleJob.getCronExpression())
// || scheduleJob.getStatus() == 1) {
// jobInfo.setTriggerStatus(1);
// } else {
//
// }
//TODO 拦截逻辑在上层完成,这里全部放行
jobInfo.setTriggerStatus(1);
return jobInfo;
}
protected void registJobHandler(XxlJob xxlJob, Object bean, Method executeMethod) {
if (xxlJob == null) {
return;
}
String name = xxlJob.value();
//make and simplify the variables since they'll be called several times later
Class<?> clazz = bean.getClass();
String methodName = executeMethod.getName();
if (name.trim().length() == 0) {
throw new RuntimeException("xxl-job method-jobhandler name invalid, for[" + clazz + "#" + methodName + "] .");
}
if (XxlJobExecutor.loadJobHandler(name) != null) {
throw new RuntimeException("xxl-job jobhandler[" + name + "] naming conflicts.");
}
// execute method
/*if (!(method.getParameterTypes().length == 1 && method.getParameterTypes()[0].isAssignableFrom(String.class))) {
throw new RuntimeException("xxl-job method-jobhandler param-classtype invalid, for[" + bean.getClass() + "#" + method.getName() + "] , " +
"The correct method format like \" public ReturnT<String> execute(String param) \" .");
}
if (!method.getReturnType().isAssignableFrom(ReturnT.class)) {
throw new RuntimeException("xxl-job method-jobhandler return-classtype invalid, for[" + bean.getClass() + "#" + method.getName() + "] , " +
"The correct method format like \" public ReturnT<String> execute(String param) \" .");
}*/
executeMethod.setAccessible(true);
// init and destroy
Method initMethod = null;
Method destroyMethod = null;
if (xxlJob.init().trim().length() > 0) {
try {
initMethod = clazz.getDeclaredMethod(xxlJob.init());
initMethod.setAccessible(true);
} catch (NoSuchMethodException e) {
throw new RuntimeException("xxl-job method-jobhandler initMethod invalid, for[" + clazz + "#" + methodName + "] .");
}
}
if (xxlJob.destroy().trim().length() > 0) {
try {
destroyMethod = clazz.getDeclaredMethod(xxlJob.destroy());
destroyMethod.setAccessible(true);
} catch (NoSuchMethodException e) {
throw new RuntimeException("xxl-job method-jobhandler destroyMethod invalid, for[" + clazz + "#" + methodName + "] .");
}
}
// registry jobhandler
XxlJobExecutor.registJobHandler(name, new MethodJobHandler(bean, executeMethod, initMethod, destroyMethod));
xlJobHandlerRepository.put(AopProxyUtils.ultimateTargetClass(bean).getName(),executeMethod.getName());
log.info("xlJobHandlerRepository beanClsName :{},method :{}",AopProxyUtils.ultimateTargetClass(bean).getName(),executeMethod.getName());
}
@Override
public void afterSingletonsInstantiated() {
try {
init();
log.info("xxl定时任务初始化注册完成");
} catch (Exception e) {
log.error("初始化异常", e);
}
}
}当我们job服务启动后,他会自动扫描schedule_job表,将符合条件的bean和method都注册进去,并根据相关参数自动填充xxl_job_info,我们任何操作都不需要做,只需要等待服务启动完成后查看控制台进行测试验证即可,看一下控制台。
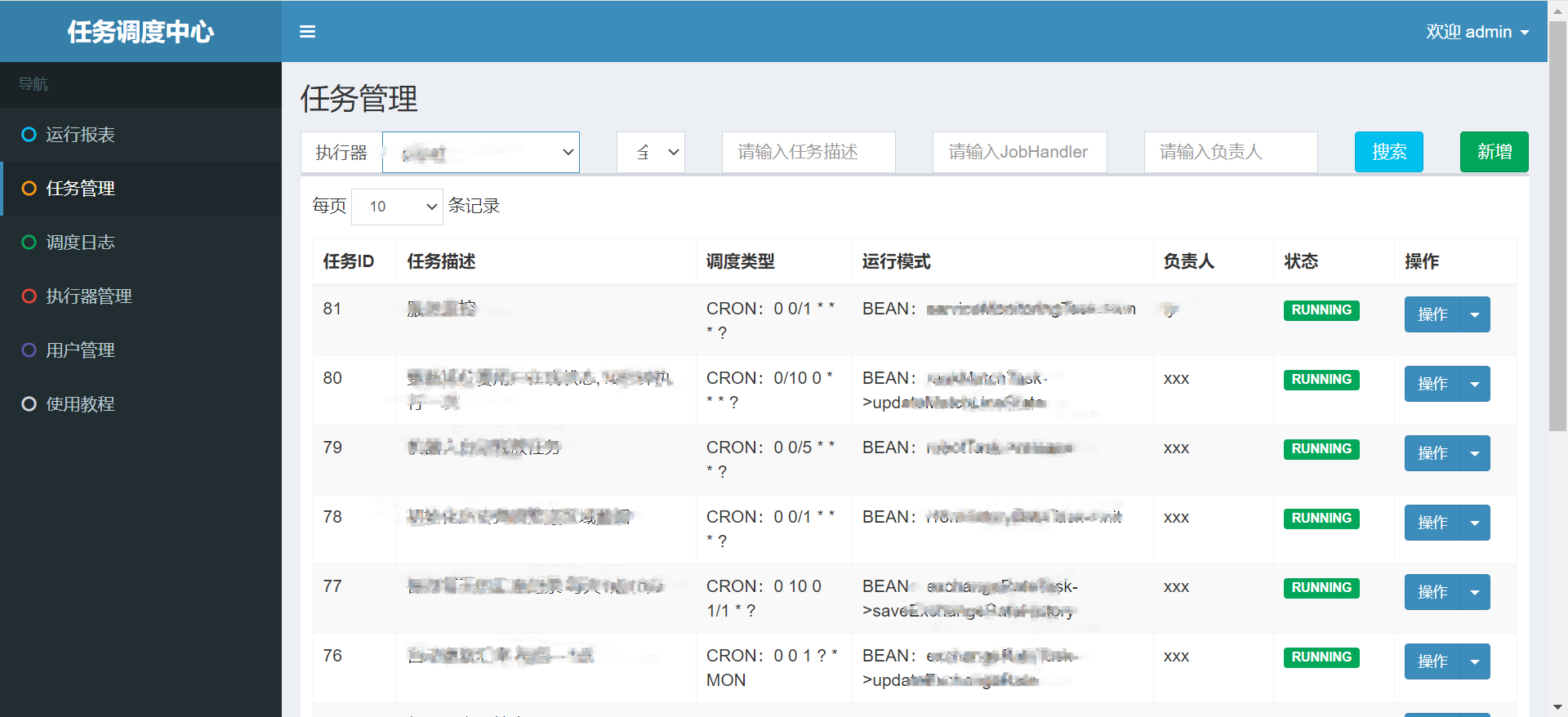
再看一下服务后台日志,任务也在正常跑,OK都完美运行。
三、新的挑战
3.1日志追踪
在我们的springboot项目中,通常都会一个全局追踪ID叫做traceId,用来标识一个完整的业务链路。但是我们如今的job调用是通过xxl-job发起的,这会导致原有的traceId缺失,我们需要将traceId补充进去。
很自然,我们想到了用aop来实现这一需求,在我们每个任务执行执行之前放入traceId,在任务执行完毕后将其移除。还记得我们上面讲到的任务注册吗,有这样一行代码,为我们接下来的aop打下了基础。
// registry jobhandler
XxlJobExecutor.registJobHandler(name, new MethodJobHandler(bean, executeMethod, initMethod, destroyMethod));
//将注册的任务放入任务仓库
xlJobHandlerRepository.put(AopProxyUtils.ultimateTargetClass(bean).getName(),executeMethod.getName());
log.info("xlJobHandlerRepository beanClsName :{},method :{}",AopProxyUtils.ultimateTargetClass(bean).getName(),executeMethod.getName());
再看一下xlJobHandlerRepository是什么?很简单,就是一个容器。
@Component
public class XXlJobHandlerRepository {
private static final Map<String, Set<String>> repository = new ConcurrentHashMap();
public Boolean hasJob(String key,String method) {
Set<String> methods = repository.get(key);
return (!CollectionUtils.isEmpty(methods) && methods.contains(method));
}
public synchronized void put(String key,String method) {
Set<String> methods = repository.get(key);
if (CollectionUtils.isEmpty(methods)){
methods = new HashSet<>();
}
methods.add(method);
repository.put(key, methods);
}
}接下来,我们写一个切面,判断是否符合要求,如果符合要求的话,我们手动放入traceId。
@Aspect
@Component
@Slf4j
public class XxlLogAspect {
@Autowired
private XXlJobHandlerRepository xlJobHandlerRepository;
//我们的定时任务包
@Pointcut("within(com.xxx.data.quartz.*)")
public void pointcut() {
}
@Around("pointcut()")
public Object doAround(ProceedingJoinPoint point) throws Throwable {
Signature signature = point.getSignature();
Object target = point.getTarget();
String clName = target.getClass().getName();
Boolean hasJob = xlJobHandlerRepository.hasJob(clName, signature.getName());
log.info("come aspect clname: " + clName);
if (hasJob) {
log.info("Job " + clName + " has job " + signature.getName());
MDC.put("traceId", UUID.randomUUID().toString());
}
Object proceed = point.proceed();
if (hasJob){
MDC.remove("traceId");
}
return proceed;
}
}再次观察日志,发现traceId已经放进去了。6e5cd7b2-f260-421d-b393-95059342a57a
2024-03-12 14:10:04.099 INFO [my-job,6e5cd7b2-f260-421d-b393-95059342a57a,] 1749 --- [xxl-job, JobThread-463-1710224250065] c.l.p.d.s.impl.user.ZnsUserServiceImpl :xxx log test 3.2日志集成
xxl-job后台为我们提供了页面查询任务执行日志的地方,他需要我们使用XxlJobHelper.log()实现,可是我们目前都有任务日志都是用@Slf4j的log实现,需要在每一个log代码下追加XxlJobHelper.log()。
log.info("xxx------执行xxx计划,处理开始");
XxlJobHelper.log("xxx------执行xxx计划,处理开始");这么做效率低且枯燥,难看且容易锤产生代码冲突,我们有没有别的方式去实现呢,我们不就是想要拿到上面log里的数据然后用xxljob的方式再打一遍嘛。那下面我们就写一个日志的Appender吧。(Appender 是一种用于定义日志消息输出的组件或接口。它定义了将日志消息发送到不同目标(例如控制台、文件、数据库等)的方式和规则)。
@Component
public class XXlLogbackAppender extends UnsynchronizedAppenderBase<ILoggingEvent> {
@Override
protected void append(ILoggingEvent iLoggingEvent) {
String formattedMessage = iLoggingEvent.getFormattedMessage();
XxlJobHelper.log(MDC.get("traceId")+" "+formattedMessage);
IThrowableProxy IthrowableProxy = iLoggingEvent.getThrowableProxy();
Throwable throwable = null;
if (IthrowableProxy instanceof ThrowableProxy throwableProxy) {
throwable = throwableProxy.getThrowable();
}
if (Objects.nonNull(throwable)) {
XxlJobHelper.log(throwable);
}
}接着我们再调整一下日志配置
...
<appender name="XXL" class="com.linzi.pitpat.job.config.XXlLogbackAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
</appender>
...
<root level="INFO">
...
<appender-ref ref="XXL"/>
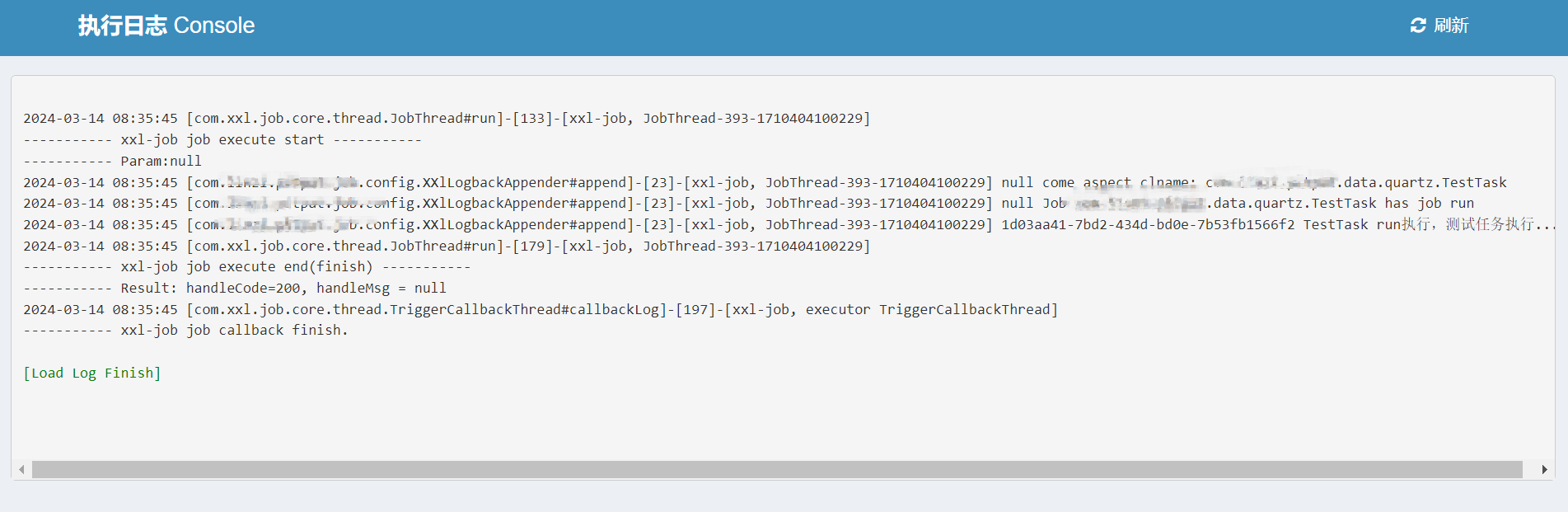
</root>至此,大功告成,我们看一下xxljob的控制后台。发现日志已经成功打印出来了
3.3多线程下日志问题
1.问题引出
在多线程环境下,xxljob无法正确显示出日志。我们可以试着挖掘一下原因原因,首先我们看下xxljob的是如何给我们打日志的,看一下XxlJobHelper.log()的源码。
/**
* append exception stack
*
* @param e
*/
public static boolean log(Throwable e) {
StringWriter stringWriter = new StringWriter();
e.printStackTrace(new PrintWriter(stringWriter));
String appendLog = stringWriter.toString();
StackTraceElement callInfo = new Throwable().getStackTrace()[1];
return logDetail(callInfo, appendLog);
}核心代码是logDetail,我们看一下logDetail的内容
/**
* append log
*
* @param callInfo
* @param appendLog
*/
private static boolean logDetail(StackTraceElement callInfo, String appendLog) {
XxlJobContext xxlJobContext = XxlJobContext.getXxlJobContext();
if (xxlJobContext == null) {
return false;
}
/*// "yyyy-MM-dd HH:mm:ss [ClassName]-[MethodName]-[LineNumber]-[ThreadName] log";
StackTraceElement[] stackTraceElements = new Throwable().getStackTrace();
StackTraceElement callInfo = stackTraceElements[1];*/
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(DateUtil.formatDateTime(new Date())).append(" ")
.append("["+ callInfo.getClassName() + "#" + callInfo.getMethodName() +"]").append("-")
.append("["+ callInfo.getLineNumber() +"]").append("-")
.append("["+ Thread.currentThread().getName() +"]").append(" ")
.append(appendLog!=null?appendLog:"");
String formatAppendLog = stringBuffer.toString();
// appendlog
//要输出的日志文件名
String logFileName = xxlJobContext.getJobLogFileName();
if (logFileName!=null && logFileName.trim().length()>0) {
XxlJobFileAppender.appendLog(logFileName, formatAppendLog);
return true;
} else {
logger.info(">>>>>>>>>>> {}", formatAppendLog);
return false;
}
}我们可以发现,我们日志输出的文件是通过xxlJobContext.getJobLogFileName()方法获取的,我们继续往下看这个方法怎么获取文件名。
package com.xxl.job.core.context;
/**
* xxl-job context
*
* @author xuxueli 2020-05-21
* [Dear hj]
*/
public class XxlJobContext {
public static final int HANDLE_CODE_SUCCESS = 200;
public static final int HANDLE_CODE_FAIL = 500;
public static final int HANDLE_CODE_TIMEOUT = 502;
// ---------------------- base info ----------------------
/**
* job id
*/
private final long jobId;
/**
* job param
*/
private final String jobParam;
// ---------------------- for log ----------------------
/**
* job log filename
*/
private final String jobLogFileName;
// ---------------------- for shard ----------------------
/**
* shard index
*/
private final int shardIndex;
/**
* shard total
*/
private final int shardTotal;
// ---------------------- for handle ----------------------
/**
* handleCode:The result status of job execution
*
* 200 : success
* 500 : fail
* 502 : timeout
*
*/
private int handleCode;
/**
* handleMsg:The simple log msg of job execution
*/
private String handleMsg;
public XxlJobContext(long jobId, String jobParam, String jobLogFileName, int shardIndex, int shardTotal) {
this.jobId = jobId;
this.jobParam = jobParam;
this.jobLogFileName = jobLogFileName;
this.shardIndex = shardIndex;
this.shardTotal = shardTotal;
this.handleCode = HANDLE_CODE_SUCCESS; // default success
}
public long getJobId() {
return jobId;
}
public String getJobParam() {
return jobParam;
}
public String getJobLogFileName() {
return jobLogFileName;
}
public int getShardIndex() {
return shardIndex;
}
public int getShardTotal() {
return shardTotal;
}
public void setHandleCode(int handleCode) {
this.handleCode = handleCode;
}
public int getHandleCode() {
return handleCode;
}
public void setHandleMsg(String handleMsg) {
this.handleMsg = handleMsg;
}
public String getHandleMsg() {
return handleMsg;
}
// ---------------------- tool ----------------------
private static InheritableThreadLocal<XxlJobContext> contextHolder = new InheritableThreadLocal<XxlJobContext>(); // support for child thread of job handler)
public static void setXxlJobContext(XxlJobContext xxlJobContext){
contextHolder.set(xxlJobContext);
}
public static XxlJobContext getXxlJobContext(){
return contextHolder.get();
}
}可以看到,xxlJobContext就是一个上下文类,存储了xxlJob环境上一些必要信息。
...
private static InheritableThreadLocal<XxlJobContext> contextHolder = new InheritableThreadLocal<XxlJobContext>(); // support for child thread of job handler)
...
public static void setXxlJobContext(XxlJobContext xxlJobContext){
contextHolder.set(xxlJobContext);
}
.../*
* handler thread
* @author xuxueli 2016-1-16 19:52:47
*/
public class JobThread extends Thread{
...
@Override
public void run() {
...
try {
// log filename, like "logPath/yyyy-MM-dd/9999.log"
String logFileName = XxlJobFileAppender.makeLogFileName(new Date(triggerParam.getLogDateTime()), triggerParam.getLogId());
XxlJobContext xxlJobContext = new XxlJobContext(
triggerParam.getJobId(),
triggerParam.getExecutorParams(),
logFileName,
triggerParam.getBroadcastIndex(),
triggerParam.getBroadcastTotal());
// xxlJobContext在这里被创建,并绑定到线程上
XxlJobContext.setXxlJobContext(xxlJobContext);
...
}
} catch (Throwable e) {
} finally {
}
}
}
}
}
到这里,我们的xxljob日志输出到哪里是不是非常清晰了,是依赖logFileName,而logFileName又是存储在xxlJobContext上,这个xxlJobContext绑定在InheritableThreadLocal上。简单介绍一下这个threadlocal跟普通threadlocal区别,普通的 ThreadLocal 只在当前线程中起作用,子线程无法继承父线程的线程本地变量。而 InheritableThreadLocal 则允许子线程继承父线程的线程本地变量。当子线程创建时,它会从父线程中继承父线程的 InheritableThreadLocal 变量的副本,使得子线程也可以独立地访问和修改该变量副本。
所以,当我们的业务是在主线程中开辟子线程时,我们的logFileName是不会丢失的,日志也能正常打印,但是一旦我们使用线程池方式去执行我们的日志,那么日志打印就会出问题,因为InheritableThreadLocal处理不了线程池情况,那么我们怎么去解决这一问题呢,我们可以尝试使用阿里的ttl。
TransmittableThreadLocal 是一个线程本地变量(ThreadLocal)的变体,它扩展了 InheritableThreadLocal 并提供了更强大的线程上下文传递能力。
在多线程环境中,当创建子线程时,父线程的上下文信息(如线程本地变量)通常无法自动传递给子线程。而 TransmittableThreadLocal 解决了这个问题,它允许在父子线程之间自动传递线程本地变量的值。
与 InheritableThreadLocal 不同,TransmittableThreadLocal 提供了更复杂的上下文传递语义。它不仅支持父线程到子线程的上下文传递,还支持线程池等场景下的线程复用,确保正确的上下文传递。
TransmittableThreadLocal 的使用方式与 ThreadLocal 和 InheritableThreadLocal 类似,可以通过 set()、get() 方法来设置和获取线程本地变量的值。
他的具体实现原理不是本文重点,就不展开介绍,大概原理是通过拦截线程的创建和执行过程来实现线程上下文的传递,其实就是包装一层线程池。
2.改造手段
第一步:首先我们修改xxljo的源码,引入阿里的ttl包,将其重新编译,上传到我们的私服。
找到XxlJobContext位置,做如下修改
//private static InheritableThreadLocal<XxlJobContext> contextHolder = new InheritableThreadLocal<XxlJobContext>(); // support for child thread of job handler)
private static TransmittableThreadLocal<XxlJobContext> contextHolder = new TransmittableThreadLocal<XxlJobContext>(); // support for child thread of job handler)
第二步:接着删除本地jar包,刷新maven仓库。
第三步:编写线程装饰器,包装需要在xxljob环境下打印日志的线程池。
public class TransmittableDecorator implements TaskDecorator {
@Override
public Runnable decorate(Runnable runnable) {
Runnable decoratedRunnable = TtlRunnable.get(runnable); // 在任务执行前获取TTL(ThreadLocal)的值
return () -> {
decoratedRunnable.run(); // 执行原始任务
};
}
}
@Bean("taskExecutor")
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setThreadNamePrefix("taskExecutor-");
executor.setCorePoolSize(Runtime.getRuntime().availableProcessors() * 2 + 1);
executor.setMaxPoolSize(Runtime.getRuntime().availableProcessors() * 4 +1);
executor.setKeepAliveSeconds(60);
executor.setQueueCapacity(10000);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.setTaskDecorator(new TransmittableDecorator());
executor.initialize();
return executor;
}第四步:重新启动服务,观察结果
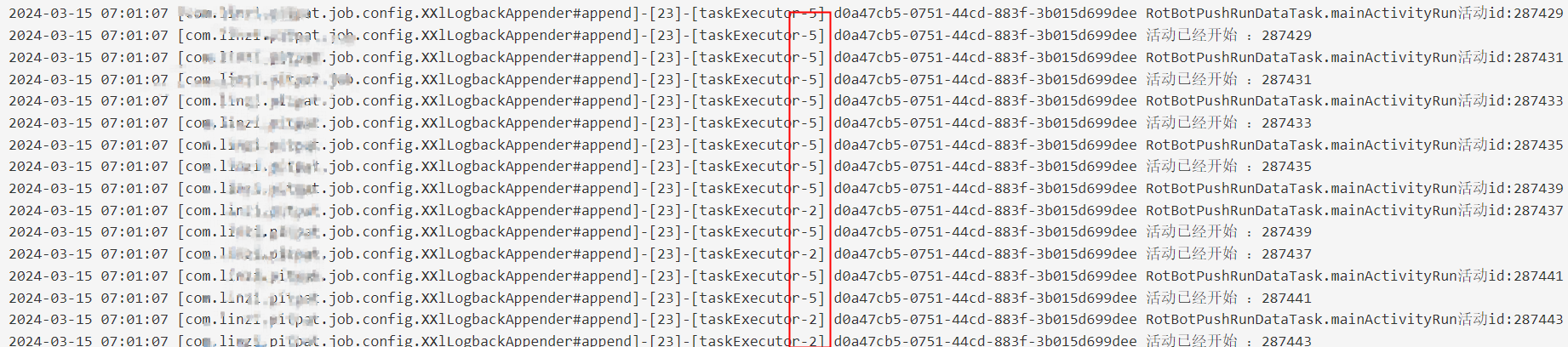
自此,我们的job服务迁移告一段落。其实,在这期间还有许多问题,但是重要的是我们最终完成了我们的目标,并在其中获得了成长,这是难能可贵的。
单体JOB向分布式JOB迁移案例的更多相关文章
- 分布式缓存Hazelcast案例一
分布式缓存Hazelcast案例一 Hazelcast IMDG Architecture 今天先到这儿,希望对您技术领导力, 企业管理,物联网, 系统架构设计与评估,团队管理, 项目管理, 产品管 ...
- mysql数据库存储过程数据迁移案例与比较
cursor 与 insert ...select 对比: cursor:安全,不会造成死锁,可以在服务运行阶段跑,比较稳定. insert...select :速度快,但是可能造成死锁,相比curs ...
- EXP/IMP迁移案例,IMP遭遇导入表的表空间归属问题
生产环境: 源数据库:Windows Server + Oracle 11.2.0.1 目标数据库:SunOS + Oracle 11.2.0.3 1.确认迁移需求:源数据库cssf 用户所有表和数据 ...
- Oracle 11gR2 Database和Active Data Guard迁移案例
客户一套核心系统由一台Oracle Database 11.2.0.3.4单机和一台Active Data Guard组成,分别运行在两台PC服务器上,Oracle Linux 5.8 x86_64b ...
- Laravel学习笔记(五)数据库 数据库迁移案例2——创建数据结构,数据表,修改数据结构
默认假设 所有的列在定义的时候都有默认的假设,你可以根据需要重写. Laravel假定每个表都有一个数值型的主键(通常命名为”id”),确保新加入的每一行都是唯一的.Laravel只有在每个表都有数值 ...
- Laravel学习笔记(四)数据库 数据库迁移案例
创建迁移 首先,让我们创建一个MySql数据库“Laravel_db”.接下来打开app/config目录下的database.php文件.请确保default键值是mysql: return arr ...
- spring cloud分布式配置中心案例
这里仍然以Windows.jdk和idea为开发环境,按照下面的步骤打包-运行-访问就能看到效果:启动注册中心:java -jar F:\jars-config\register-0.0.1-SNAP ...
- 【从单体架构到分布式架构】(三)请求增多,单点变集群(2):Nginx
上一个章节,我们学习了负载均衡的理论知识,那么是不是把应用部署多套,前面挂一个负载均衡的软件或硬件就可以应对高并发了?其实还有很多问题需要考虑.比如: 1. 当一台服务器挂掉,请求如何转发到其他正常的 ...
- 15套java架构师、集群、高可用、高可扩展、高性能、高并发、性能优化、Spring boot、Redis、ActiveMQ、Nginx、Mycat、Netty、Jvm大型分布式项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩展. ...
- 15套java互联网架构师、高并发、集群、负载均衡、高可用、数据库设计、缓存、性能优化、大型分布式 项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩 展 ...
随机推荐
- Delphi2010中TResourceStream流使用
Resource可以是任意文件(图像.声音.office都可以),直接打包到编译的exe文件中,调用也非常方便 打开一个新的或已有的delphi工程 1.先在 Project->resource ...
- .NET 云原生架构师训练营(模块二 基础巩固 Scrum 简介)--学习笔记
2.7.2 Scrum 简介 SCRUM 是什么 SCRUM 精髓 SCRUM 框架 角色 SCRUM 是什么 SCRUM 是迄今为止最著名的敏捷方法,主要用于开发.交付和持续支持复杂产品的一个框架, ...
- .NET Core开发实战(第17课:为选项数据添加验证:避免错误配置的应用接收用户流量)--学习笔记
17 | 为选项数据添加验证:避免错误配置的应用接收用户流量 三种验证方法 1.直接注册验证函数 2.实现 IValidateOptions 3.使用 Microsoft.Extensions.Opt ...
- NC235745 拆路
题目链接 题目 题目描述 有 \(n\) 个城镇,城镇之间有 \(m\) 条道路相连,道路可以看成无向边.每一个城镇都有自己的一个繁荣度 \(v_i\) ,一个城镇 \(u\) 受到的影响 \(p\) ...
- 一文总结 C++ 常量表达式、constexpr 和 const
TLDR 修饰变量的时候,可以把 constexpr 对象当作加强版的 const 对象:const 对象表明值不会改变,但不一定能够在编译期取得结果:constexpr 对象不仅值不会改变,而且保证 ...
- sensitive word 敏感词(脏词) 如何忽略无意义的字符?达到更好的过滤效果?
忽略字符 说明 我们的敏感词一般都是比较连续的,比如 傻帽 那就有大聪明发现,可以在中间加一些字符,比如[傻!@#$帽]跳过检测,但是骂人等攻击力不减. 那么,如何应对这些类似的场景呢? 我们可以指定 ...
- 端口碰撞Port Knocking和单数据包授权SPA
端口碰撞技术 Port knocking 从网络安全的角度,服务器开启的端口越多就越不安全,因此系统安全加固服务中最常用的方式,就是先关闭无用端口,再对提供服务的端口做访问控制.而作为远程管理与维护的 ...
- elasticstack-7.5.0部署实战
1.Elastic Stack 数据搜索.分析和可视化工具 中文网: https://elkguide.elasticsearch.cn/beats/metric.html Elasticsearch ...
- Fiddler捕获Java发送的HttpURLConnection请求
1.说明 平常使用Fiddler抓包工具查看浏览器的请求和响应信息很方便, 但有时候我们也需要拦截java代码执行的http请求. 以便更好的调试程序.具体方法如下: 2.编写Java代码 // 配置 ...
- win32 - 对于32位的应用程序,LoadResource为什么不需要释放资源
原话: [此功能已过时,仅支持与16位Windows向后兼容.对于32位Windows应用程序,不必释放使用LoadResource加载的资源.如果在32或64位Windows系统上使用,此函数将返回 ...