Lite-Mono(CVPR2023)论文解读
Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth Estimation 是CVPR2023收录的论文,从它的标题能很清晰了解到它所在的领域或解决的问题是:自监督的单目深度估计;它的网络结构是轻量化的卷积和Transformer的混合结构。
解决的问题
大多数的研究都是往提高任务的准确率,这必然造成所设计的网络更注重准确率,使网络的体积或计算量大幅提高,这使在边缘终端上使用的可能性越来越小。本文针对自监督的单目深度估计,探讨在控制网络参数量的同时保持或提高准确性。
主要贡献
1. 在自监督的单目深度估计方面,降低网络的参数量和运算量,同时提升了准确率。提高在边缘终端上使用的可能性。
相关研究
1)监督的深度估计
[1] Depth map prediction from a single image using a multi-scale deep netwrk. (NeurIPS2014)
[2] Deeper depth prediction with fully convolutional residual networks. (3DV2016)
[3] Deep ordinal regression network for monocular depth estimation. (CVPR2018)
2)自监督的深度估计
[4] Unsupervised cnn for single view depth estimation: Geometry to the rescue. (ECCV2016)
[5] Unsupervised monocular depth estimation with left-right consistency. (CVPR2017)
[6] Unsupervised learning of depth and ego-motion from video. (CVPR2017)
[7] Digging into self-supervised monocular depth estimation. (ICCV2019)
3)这方面的网络架构
[8] Self-supervised monocular depth estimation with internal feature fusion. (2021)
[9] R-msfm: Recurrent multi-scale feature modulation for monocular depth estimating. (ICCV2021)
[10] Transformers in self-supervised monocular depth estimation with unknown camera intrinsics. (2022)
[11] Vision transformers for dense prediction. (ICCV2021)
[12] Monoformer: Towards generalization of self-supervised monocular depth estimation with transformers. (2022)
[13] Monovit: Self-supervised monocular depth estimation with a vision transformers. (3DV2022)
[14] Mpvit: Multi-path vision transformer for dense prediction. (CVPR2022)
解决方案和关键点
1)网络结构
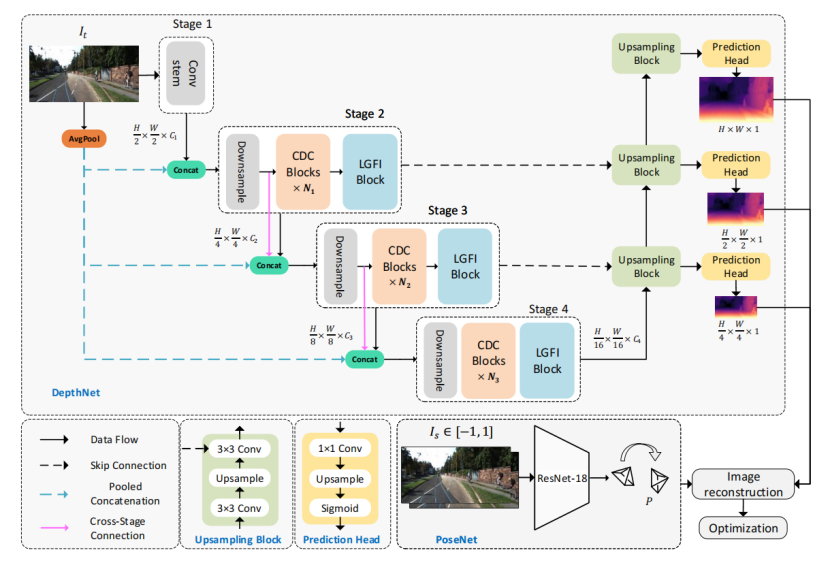
作者的工作主要在DepthNet上,PoseNet是一直沿用ResNet-18的方案(从 [7] 之后没有改变)。
DepthNet是4-Stage结构,每个Stage进行1/2分辨率的下采样(新的特征图是原来的1/4),这是比较常规的做法,另一种是5-Stage,考虑到是轻量化的工作,选择5-Stage的可能性更小(参数量和计算量)。在Encoder里另一个特别的做法是Stage-1与Decoder没有连接,与常见的类UNet结构有些区别,估计也是为了轻量化考虑。
Encoder一共4个创新点:
1. CDC Block;
2. LGFI Block;
3. Pooled Concatenation;
4. Cross-Stage Connction.
2)Consecutive Dilated Convolutions (CDC)

CDC主要由三部分组成:3 x 3的空洞深度可分离卷积和两层全连接。作者提到与之前的空洞卷积通常在并联使用,而这里会串联使用,简单说,每个CDC Block的Dilation值可能配置不一样,这使CDC的感受野有所区别,增加抓取特征的多样性。使用深度可分离卷积(MobileNet v1)是轻量化手段之一,但同时也会弱化网络的表现能力。为了解决这个问题,depth-wise卷积通常连接着point-wise卷积,从作用上等效普通的卷积层。作者在这里没有使用point-wise,而是在通道(channel)上使用全连接,变相达到point-wise效果并且进行channel膨胀。再由最后一层全连接投影回原通道,从结构上有点深度可分离卷积接传统MLP的味道,但参数量更少。
3)Local-Global Features Interaction (LGFI)
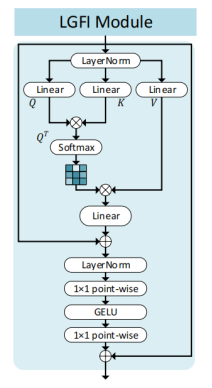
LGFI主要由两部分组成:自注意力模块和MLP。两部分都没有什么特别的地方,Transformer模块本身不会增加很多参数量,它的消耗主要在计算量上,所以作者在Stage-2 到 Stage-4,每个Stage只使用一个LGFI。把全局关联性作为一个补充,而不是主要。
4)Pooled Concatenation
在Stage-2 到 Stage-4的输入端增加3个原图下采样的特征,3个特征图分别是R,G,B,而下采样的方式是平均池化。由于从原图直接平均池化到目标分辨率会引起大量细节丢失,所以作者使用多次1/2平均池化的做法。相比较每个Stage的输入通道数,Pooled Concatenation所提供3个通道的影响比较有限,从消融实验中能看出来。
5)Cross-Stage Connection
在Stage-3和Stage-4的输入端,除了上一个Stage的输入之外,增加上一个Stage的“生图”。由于每个Stage的通道数是固定的,所以下一个Stage的输入通道数成倍增加,应该是从增加特征多样性上考虑。但从消融实验中能看出来,它的作用不是太大。
6)网络配置
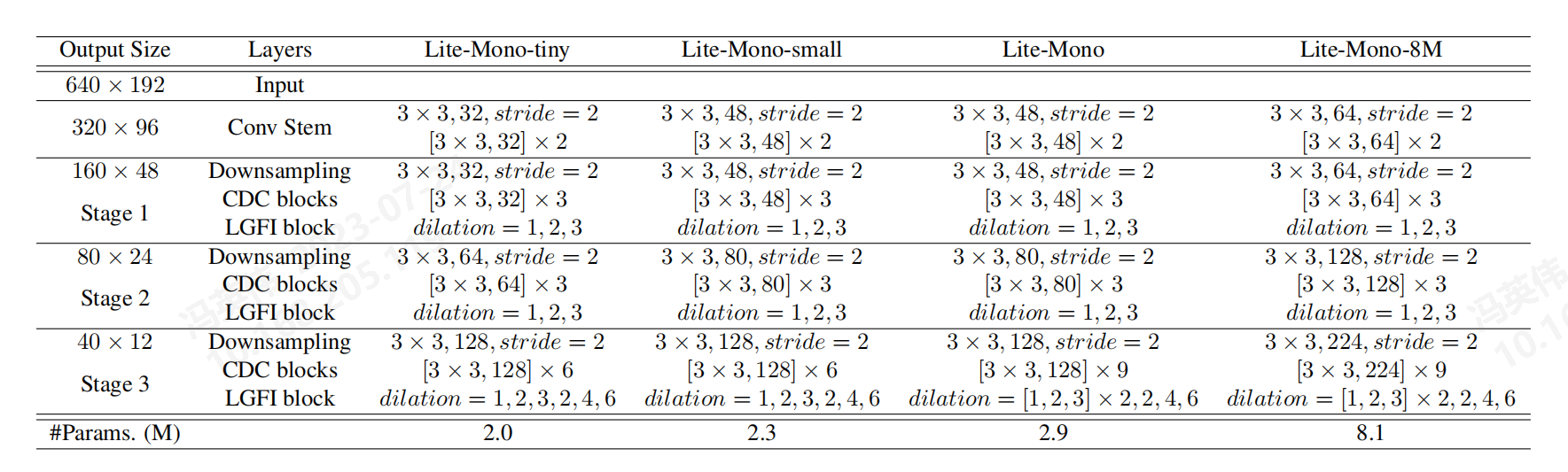
作者提供了4种不同的网络配置,最小只有2.0M参数量,比现在一般的网络都小得多,能为不同的边缘终端选择合适的配置。
总结
在实验部分可以看到本网络结构在参数量、计算量和准确率均比之前的网络有所提高,主要还是得益于CDC和LGFI。实验部分我没有谈到,如果需要的话,可以补充上去。
Transformer模块在视觉上的使用都得到广泛的认可,它主要还是计算量方面的损耗比较大,但在小尺寸特征图上的损耗没这么突出,所以在Stage-4里可以尝试使用更多的Transformer模块。
Lite-Mono(CVPR2023)论文解读的更多相关文章
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- NIPS2018最佳论文解读:Neural Ordinary Differential Equations
NIPS2018最佳论文解读:Neural Ordinary Differential Equations 雷锋网2019-01-10 23:32 雷锋网 AI 科技评论按,不久前,NeurI ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
- 【抓取】6-DOF GraspNet 论文解读
[抓取]6-DOF GraspNet 论文解读 [注]:本文地址:[抓取]6-DOF GraspNet 论文解读 若转载请于明显处标明出处. 前言 这篇关于生成抓取姿态的论文出自英伟达.我在读完该篇论 ...
- 《Stereo R-CNN based 3D Object Detection for Autonomous Driving》论文解读
论文链接:https://arxiv.org/pdf/1902.09738v2.pdf 这两个月忙着做实验 博客都有些荒废了,写篇用于3D检测的论文解读吧,有理解错误的地方,烦请有心人指正). 博客原 ...
- 注意力论文解读(1) | Non-local Neural Network | CVPR2018 | 已复现
文章转自微信公众号:[机器学习炼丹术] 参考目录: 目录 0 概述 1 主要内容 1.1 Non local的优势 1.2 pytorch复现 1.3 代码解读 1.4 论文解读 2 总结 论文名称: ...
随机推荐
- 笔记八:linux系统编程之IO
笔记:linux系统编程之IO 应用层 内核层 硬件层 应用层:数据结构 .java.android.C.C++,C#: l inux高级编程:涉及内核为应用层提供接口函数: 内核五大 ...
- iOS APP启动广告实现方式 与 APP唤端调用
APP启动广告功能实现要从2个方面思考 一是UI方案,怎样处理广告页与主页之间的切换方式. 二是广告页展示时机,是使用后台实时广告数据还是使用本地缓存广告数据.后台数据方式获取广告最新但是用户要等待后 ...
- Redis主从和哨兵搭建
今天主要分享Redis主从架构和哨兵的搭建. 主从集群搭建 总共三个节点,一个主节点和两个从节点.都安装在一台机器上模拟主从集群,信息如下: IP PORT 角色 192.168.246.140 70 ...
- 【CSS】使元素在父元素中居中显示的几种方法
在页面元素布局时经常会有把元素居中的需求,大多都是用弹性盒或者定位,下面来说一下使用方法 一.使用边距进行固定位置 这种方法需要把父元素和子元素的宽度固定,然后利用二者宽高之差添加边距移动元素的位置 ...
- 批x网,登录加密(通过元素绑定的监听事件来找到加密函数)
网站 base64加密 aHR0cHM6Ly93d3cucGlnYWkub3JnLw== 逆向分析 https://blog.csdn.net/a_123_4/article/details/1208 ...
- selenium web控件的交互进阶
Action ActionChains: 执行PC端的鼠标点击,双击,右键,拖曳等事件 TouchActions: 模拟PC和移动端的点击,滑动,拖曳,多点触控等多种手势操作 动作链接 ActionC ...
- 2022-07-27:小红拿到了一个长度为N的数组arr,她准备只进行一次修改, 可以将数组中任意一个数arr[i],修改为不大于P的正数(修改后的数必须和原数不同), 并使得所有数之和为X的倍数。
2022-07-27:小红拿到了一个长度为N的数组arr,她准备只进行一次修改, 可以将数组中任意一个数arr[i],修改为不大于P的正数(修改后的数必须和原数不同), 并使得所有数之和为X的倍数. ...
- Selenium - 浏览器配置(4) - 打开无痕浏览器
Selenium - 浏览器配置 无痕浏览器 开启谷歌浏览器的无痕浏览模式: from selenium import webdriver # 引入浏览器配置 chrome_options = web ...
- macOS下由yarn与npm差异引发的Electron镜像地址读取问题
记录macOS下由yarn与npm差异引发的Electron镜像地址读取问题 写在前面:该问题仅仅出现在Linux和macOS上,Windows上不存在该问题! 初始背景 最近笔者重新拾起了Elect ...
- rest framework 学习 序列化
序列化功能:对请求数据进行验证和对Queryset进行序列化 Queryset进行序列化: 1 序列化之Serializer 1 class UserInfoSerializ ...