树模型-label boosting-GBDT
GBDT
GBDT是boosting系列算法的代表之一,其核心是 梯度+提升+决策树。
GBDT回归问题
通俗的理解:
先来个通俗理解:假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。最后将每次拟合的岁数加起来便是模型输出的结果。
决策树用的是cart树,准确来说是用的cart树中的回归树。之所以要用回归树,是因为gbdt其实去拟合的不仅仅是原数据的标签,还有每一个树经过学习之后留下的残差:所以gbdt不管是分类还是回归,都是拟合的残差值。GBDT的过程用文字描述是这样的:
假设我拿到一批数据,标签是连续值,我拿来做回归任务。
那么拿到数据之后,gbdt首先开始初始化它的第0颗树,一般而言吗,第0颗树不做什么特殊的操作,输出值就是标签的均值。
初始化好了之后,我们就可以计算每一个样本的第一批残差,严格来说这个值是损失函数对第0颗树求偏导的结果,我们用平方损失作为loss的话就是刚刚训练的那颗树减去标签的值,拿到残差后,,残差作为本次训练样本的新标签,开始建立第一课CART树:
- 遍历每个特征下所有可能的切分点,寻找最优的切分点之后将样本一分为2,大于这个切分点的样本丢到左子树,小于等于的放右子树,当然也可以反着来,这个看具体的工程实现。
- 这个时候,我们左右节点都有了样本,那么此刻左右节点还可以接着再分,接着开始按上面的套路接着在所有的特征上再找一遍最优切分点,又把数据一分为2。这个过程直到满足样本不可再分的情况下为止,具体来说,我们可以定义树的深度,每个叶子节点含有的最少样本数等等来限制树的生长过程,不限制的话,基本是就是一直分到只剩下一个样本落到叶子节点上为止。
- 现在我们已经到了叶子节点了,那么这个叶子节点的值就是其所包含的样本的标签的均值,或者是是餐叉的均值
- 现在第一颗树已经ok了,那么这颗树的输出值就是: 前面所有树的输出+本次树的输出*学习率,得到最终的输出值
- 好了之后,我们开始计划训练下一颗树,步骤就是通过再一次计算梯度得到残差,更新这批训练样本的标签,以同样的套路再训练一遍,又得到一颗树。
- 一直训练,假设我们需要100颗树,那就这样训练100次
- 最终,预测的时候,我们丢一条样本,进去,每颗树都能得到一个输出值,我们把这些输出值加起来作为最终的预测结果
GBDT的前夜--提升树
提升树算法也是用的残差去拟合下一颗树,它和gbdt的不同是:他真的是残差,而gbdt则是近似残差。那么它的算了步骤是这样的
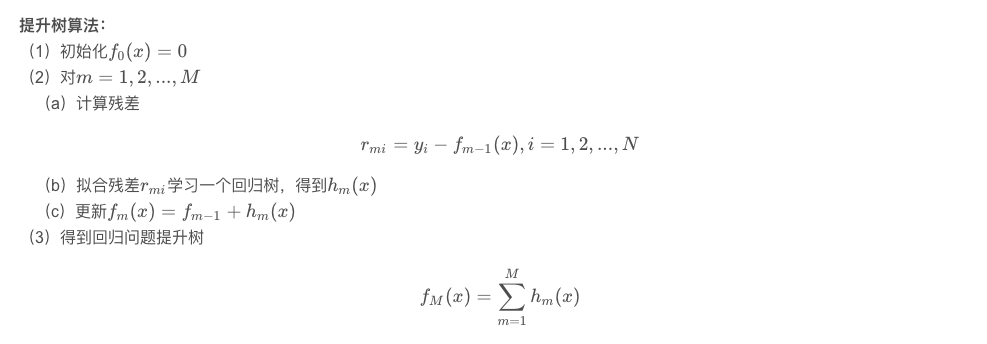
而且,与gbdt相比,其第0课树一般输出是0

GBDT残差近似
其实就是提升树的部分,把残差改成了损失函数的梯度,用来近似提升树的残差。所以,当使用平方损失的时候,这个梯度就是真正的残差,如果boosting算法每一步的弱分类器生成都是依据损失函数的梯度方向,则称之为梯度提升(Gradient boosting)

GBDT 分类问题
这里我们再看看GBDT分类算法,GBDT的分类算法从思想上和GBDT的回归算法没有区别,核心还是用残差去拟合树。但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。
为了解决这个问题,主要有两个方法,一个是用指数损失函数,此时GBDT退化为Adaboost算法。另一种方法是用类似于逻辑回归的对数似然损失函数的方法。也就是说,我们用的是类别的预测概率值和真实概率值的差来拟合损失。这里讨论用对数似然损失函数的GBDT分类。而对于对数似然损失函数,我们又有二元分类和多元分类的区别。
二分类
回归问题上,我们用的损失可能是平方损失,那么在二分类问题上,我们用的损失就是非常经典的逻辑回归的损失,也就是而分类交叉熵损失(BCE loss),也叫对数似然损失。在预测类别的时候,每棵树我们都能拿到一个叶子节点,叶子节点上存着的和gbdt回归一样,是属于该叶子节点的样本的残差的均值,也就是label的均值,为什么分类也是label的均值?因为分类也是用的回归树,回归树划分叶子节点的损失是平方损失。
同样的,这些树在做预测的时候,也是加法模型,但是最终的预测结果,需要做一件事,激活:显然,我们可以用lr的激活方式也就是sigmoid做激活,拿来搞定二分类问题
损失函数
损失函数拿来做梯度计算,拿到下一批样本的残差即是label,二分类损失函数为:
\]
激活用sigmoid函数
整个过程描述为:


多分类
与二分类的套路一样,不过需要注意的是,多分类时候,有多少个类,一般一轮都会建多少颗树。
损失函数的话,多分类最长使用的损失函数就是交叉熵了:
\]
激活函数用的softmax
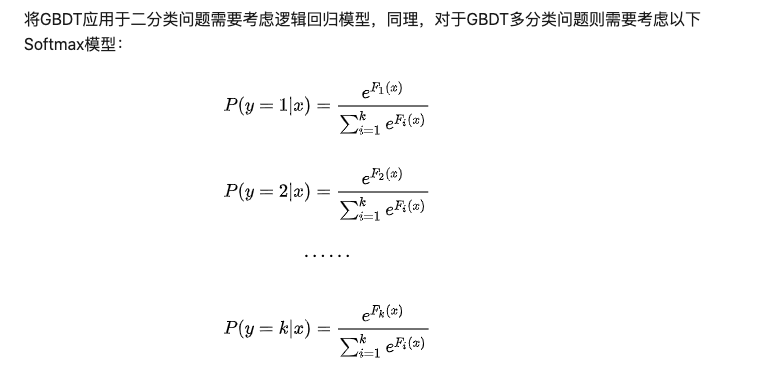
那么整个过程有:

GBDT总结
GBDT主要的优点有:
- 可以灵活处理各种类型的数据,包括连续值和离散值。
- 在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的。
- 使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
GBDT的主要缺点有:
- 由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
GBDT的一些思考
- gbdt数据需要考虑归一化吗?
理论上来说是不需要的,因为特征做不做归一化,都不会影响到结点是否分裂或者不分裂。分不分只与此刻label的分布造成的分裂点的收益有关
参考链接
gbdt是如何进行多分类的
gbdt多分类
gbdt二分类
gbdt step by step
树模型-label boosting-GBDT的更多相关文章
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting
本杂记摘录自文章<开发 | 为什么说集成学习模型是金融风控新的杀手锏?> 基本内容与分类见上述思维导图. . . 一.机器学习元算法 随机森林:决策树+bagging=随机森林 梯度提升树 ...
- 浅谈树模型与集成学习-从决策树到GBDT
引言 神经网络模型,特别是深度神经网络模型,自AlexNet在Imagenet Challenge 2012上的一鸣惊人,无疑是Machine Learning Research上最靓的仔,各种进 ...
- 集成学习(ensemble method)--基于树模型
bagging方法(自举汇聚法 bootstrap aggregating) boosting分类:最流行的是AdaBoost(adaptive boosting) 随机森林(random fores ...
- 特征选择:方差选择法、卡方检验、互信息法、递归特征消除、L1范数、树模型
转载:https://www.cnblogs.com/jasonfreak/p/5448385.html 特征选择主要从两个方面入手: 特征是否发散:特征发散说明特征的方差大,能够根据取值的差异化度量 ...
- Qt 学习之路 2(51):布尔表达式树模型
Qt 学习之路 2(51):布尔表达式树模型 豆子 2013年5月15日 Qt 学习之路 2 17条评论 本章将会是自定义模型的最后一部分.原本打算结束这部分内容,不过实在不忍心放弃这个示例.来自于 ...
- 树模型常见面试题(以XGBoost为主)
参考资料: 珍藏版 | 20道XGBoost面试题 推荐系统面试题之机器学习(一) -----树模型 1. 简单介绍一下XGBoost2. XGBoost与GBDT有什么不同3. XGBoost为什么 ...
- 机器学习——手把手教你用Python实现回归树模型
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天这篇是机器学习专题的第24篇文章,我们来聊聊回归树模型. 所谓的回归树模型其实就是用树形模型来解决回归问题,树模型当中最经典的自然还是决 ...
- sklearn中树模型可视化的方法
在机器学习的过程中,我们常常会用到树模型的方式来解决我们的问题.在工业界,我们不仅要针对某个问题利用机器学习的方法来解决问题,而且还需要能力解释其中的原理或原因.今天主要在这里记录一下树模型是怎么做可 ...
- 使用 Jackson 树模型(tree model) API 处理 JSON
http://blog.csdn.net/gao1440156051/article/details/54091702 http://blog.csdn.net/u010003835/article/ ...
- 分类-回归树模型(CART)在R语言中的实现
分类-回归树模型(CART)在R语言中的实现 CART模型 ,即Classification And Regression Trees.它和一般回归分析类似,是用来对变量进行解释和预测的工具,也是数据 ...
随机推荐
- 代码随想录算法训练营第七天| LeetCode 454.四数相加II 15. 三数之和 18. 四数之和
454.四数相加II 卡哥建议:本题是使用map巧妙解决的问题,好好体会一下 哈希法如何提高程序执行效率,降低时间复杂度,当然使用哈希法会提高空间复杂度,但一般来说我们都是舍空间换时间, 工业开发也是 ...
- 从源码看webpack3打包流程
在javascript刚刚流行时,前端项目通常比较简单,不需要考虑项目的开发效率.性能和扩展性等. 随着前端项目越来越复杂,需要更正式的软件开发实践,比如单元测试(unit testing).代码检查 ...
- 安卓app设置背景音乐循环播放另有强制不能调节音量软件无法退出(仅供个人学习)
步进式调节:(直接调到那个音量): setStreamVolume (int streamType, int index, int flags) int streamType 需要调整的音量类型 ( ...
- 使用pymysql库,将tushare股票信息保存入本地MySQL数据库
使用pymysql库,将tushare股票信息保存入本地MySQL数据库 1.前言 由于tushare存在积分权限限制,高频读取tushare数据容易挤占服务器带宽,因此对于常用的tushare数据, ...
- 逆向通达信Level-2 续三 (KTL python控制台动态调试)
python控制台逆向分析. python 跟 js 自如切换 逆向通达信Level-2 续十一 (无帐号登陆itrend研究版) 逆向通达信Level-2 续十 (trace脱壳) 逆向通达信Lev ...
- Ubuntu 14.04 Intel 处理器 硬编解码配置(Intel® Media Server Studio)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- Ubuntu 14.04 升级到Gnome3.12z的折腾之旅(警示后来者)+推荐Extensions.-------(二)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文发布于 2014-12-22 15:33:35 ...
- Lambda Web Browser使用教程
Lambda web browser是一个功能强大的UE内置浏览器插件, 允许用户在编辑器模式和运行时启动一个浏览器窗口, 对于一些采用传统BS架构的项目而言, 控制页面都放在前段, 若想要将控制页面 ...
- (1)Python基础的一些教学资料和视频
Python相关的一些书籍 链接: https://pan.baidu.com/s/1uVT_xQRShxsw2gRhjJhikA 密码: 5fgi Python的相关进阶课程 链接: https:/ ...
- FreeRTOS教程9 软件定时器
1.准备材料 正点原子stm32f407探索者开发板V2.4 STM32CubeMX软件(Version 6.10.0) Keil µVision5 IDE(MDK-Arm) 野火DAP仿真器 XCO ...