MyBatis一对多或多对多分页查询的结果条数不符合预期的问题解决
问题描述
通常我们我们在单表查询中我们可以采用limit进行分页查询,这样可以减少页面的显示量,加快页面想应速度。但是在MyBatis框架中,如果我们在一对多或多对多查询中直接使用limit关键字的话会产生查询结果数量不够的情况。
我们先给出一个关系模型:
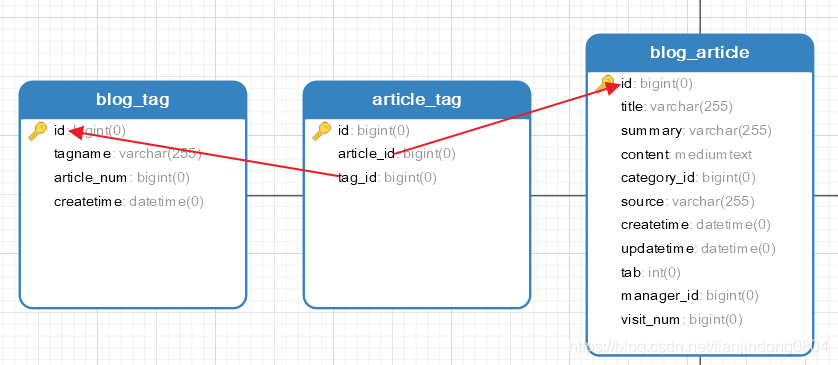
blog_tag(标签表)和blog_article(文章表)是多对多关系,article_tag是多对多关系中的联系表。
传统的分页查询
我们需要分页查询blog_article表,然后关联查询“文章的标签”表,执行SQL如下:
-- 只查询表中一小部分字段是为了演示方便,我们分页article表的8条数据
SELECT
a.id,
a.title,
t.tagname,
t.article_num
FROM
blog_article a
LEFT JOIN article_tag a_t ON a.id = a_t.article_id
LEFT JOIN blog_tag t ON a_t.tag_id = t.id
LIMIT 0,8
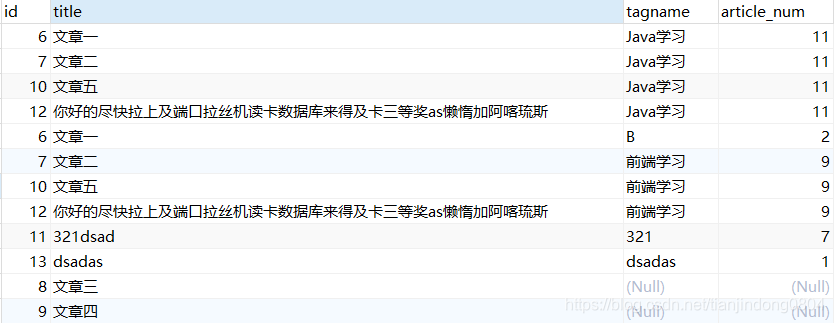
查询结果:

我们可以看到查询的结果中虽然有8条数据,但是不是我们想要的8条article数据,如果上述结果被MyBatis封装只会得到4个BlogArticle对象。这就开头提出的问题的产生原因。
解决方案
我们可以采用子查询分页的方式来解决这个问题。
SELECT
a.id,
a.title,
t.tagname,
t.article_num
FROM
(select id,title from blog_article limit 0,8) a
LEFT JOIN article_tag a_t ON a.id = a_t.article_id
LEFT JOIN blog_tag t ON a_t.tag_id = t.id
执行结果:
通过上述方案,我们才能得到8条BlogArticle对象。
MyBatis一对多或多对多分页查询的结果条数不符合预期的问题解决的更多相关文章
- MyBatis 一对多,多对一关联查询的时候Mapper的顺序
要先写association,然后写collection:这是由DTD决定的: <resultMap ...> <association ...> </associati ...
- Mybatis一对多或多对多只能查出一条数据解决策略
原文:https://blog.csdn.net/ren814/article/details/81742242 <resultMap id="menuModelMap" t ...
- mybatis报错:查询一对多或多对多时只返回一条数据的问题
问题: 使用映射文件实现查询一对多或多对多时只返回一条数据问题 解决方法: 导致这种情况出现的问题是因为两个表中的主键是一样所以出现了数据覆盖问题. 解决方式一:修改数据库表中的主键(这种方法比较麻烦 ...
- SSAS中事实表中的数据如果因为一对多或多对多关系复制了多份,在维度上聚合的时候还是只算一份
SSAS事实表中的数据,有时候会因为一对多或多对多关系发生复制变成多份,如下图所示: 图1 我们可以从上面图片中看到,在这个例子中,有三个事实表Fact_People_Money(此表用字段Money ...
- Mybatis一对多/多对多查询时只查出了一条数据
问题描述: 如果三表(包括了关系表)级联查询,主表和明细表的主键都是id的话,明细表的多条数据只能查询出来第一条/最后一条数据. 三个表,权限表(Permission),权限组表(Permission ...
- springboot结合mybatis使用pageHelper插件进行分页查询
1.pom相关依赖引入 <dependencies> <dependency> <groupId>org.springframework.boot</grou ...
- Mybatis的ResultMap与limit分页查询
ResultMap主要解决的是:属性名和字段不一致 如果在pojo中设置的是一个名字,在数据库上又是另一个名字,那么查询出来的结果或者其他操作的结果就为null. //在pojo中 private S ...
- mybatis一对多根据条件查询的查条数
一对多写了mapper映射之后 根据条件查条数 可以根据主表的唯一id进行分组 在拿到它的count select count(0) over(aa.id),,id,name,age from tab ...
- C# 返回分页查询的总页数
/// <summary> /// 返回分页查询操作的的总页数 /// </summary> /// <param name="count">总 ...
- 表单生成器(Form Builder)之mongodb表单数据查询——返回分页数据和总条数
上一篇笔记将开始定义的存储结构处理了一下,将FormItems数组中的表单项都拿到mongodb document的最外层,和以前的关系型数据类似,之不过好多列都是动态的,不固定,不过这并没有什么影响 ...
随机推荐
- 教你构建一个优秀的SD Prompt
构建一个优秀的Prompt 在使用Stable Diffusion AI时,构建一个有效的提示(Prompt)是至关重要的第一步.这个过程涉及到创造性的尝试和对AI行为的理解.这里我会对如何构建一个好 ...
- 本周三晚19:00Hello HarmonyOS应用篇第7课—分布式应用开发
6月15日19:00 Hello HarmonyOS系列应用篇迎来的本系列直播课的最后一课,将会有怎样的精彩呈现呢? 万物互联的时代已经来临,如果你想运用过往的技术,开发一个有"跨设备操 ...
- sql 语句系列(记录时间差)[八百章之第十八章]
计算当前记录和下一条记录之间的日期差 关键点在于如何获得下一条日期. mysql 和 sql server select x.*,DATEDIFF(day,x.HIREDATE,x.next_hd) ...
- 面向切面编程AOP[四](java AnnotationAwareAspectJAutoProxyCreator与ioc的联系)
前言 拿出上一篇的内容: AnnotationAwareAspectJAutoProxyCreator extends AspectJAwareAdvisorAutoProxyCreator Aspe ...
- 重走py 之路 ——普通操作与函数(三)
前言 本节主要介绍函数,但是函数是由操作组成的.那么就分为两部,一部分为操作一部分为函数. 正文 py世界中的操作. 操作 if: 在学习任何一门语言中,关系if,要关系另外一件事,那就是if是否只能 ...
- cv2在图像上画不同比例的锚框
''' cv2在图像上画不同比例的锚框 ''' import cv2 import math # 画宽高比1:1的锚框 def display_11_anchor(img,anchor_11_left ...
- Flask搭建APP统一管理平台
主页效果: 1.从数据库中获取所有APP的信息,每个卡片上展示APP名称.bundle id.版本构建历史记录,系统类型等构建信息 2.支持查询筛选,模糊查询 3.点击历史记录跳转APP历史记录详情页 ...
- etcd 集群安装
1.环境准备 下载安装包:https://github.com/etcd-io/etcd/releases/ 这里下载的安装包为:etcd-v3.5.9-linux-amd64.tar.gz,即我们当 ...
- 第3章 python 爬虫抓包与数据解析
第 3章 Python 爬虫抓包与数据解析 3.1 抓包进阶 目前,我们已经会使用 Chrome 浏览器自带的开发者工具来抓取访问网页的数据包,但是这种抓包方法有局限性,比如只能监听一个浏览器选项卡, ...
- 如何在 Anolis 8上部署 Nydus 镜像加速方案?
简介: 手把手教你在 Anolis OS 上部署 Nydus! 在上一篇文章中详细介绍Anolis OS 是首个原生支持镜像加速 Linux 内核,Nydus 镜像加速服务重新优化了现有的 OCIv1 ...