李宏毅2022机器学习HW4 Speaker Identification下
Task
Sample Baseline模型介绍
class Classifier(nn.Module):
def __init__(self, d_model=80, n_spks=600, dropout=0.1):
super().__init__()
# Project the dimension of features from that of input into d_model.
self.prenet = nn.Linear(40, d_model)
# transformer
self.encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, dim_feedforward=256, nhead=2
)
self.encoder = self.encoder_layer
self.pred_layer = nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, n_spks),
)
def forward(self, mels):
"""
args:
mels: (batch size, length, 40)
return:
out: (batch size, n_spks)
"""
# out: (batch size, length, d_model)
out = self.prenet(mels)
# out: (length, batch size, d_model)
out = out.permute(1, 0, 2)
# The encoder layer expect features in the shape of (length, batch size, d_model).
out = self.encoder(out)
# out: (batch size, length, d_model)
out = out.transpose(0, 1)
# mean pooling
stats = out.mean(dim=1)
# out: (batch, n_spks)
out = self.pred_layer(stats)
return out
模型开始对特征进行了升维以增强表示能力,随后通过transformer的encoder对数据进一步编码(未使用decoder),到这一步就包含了原来没有包含的注意力信息,以英文Sequence为例,如果原来的Sequence中每个单词是独立编码的是没有任何关联的,那么经过这一步之后,每一个单词的编码都是由其他单词编码的叠加而成。最后通过pred_layer进行预测(当然在此之前进行了一个mean pooling,这个下面会讲)。
在模型的前向传播时,模型基本是安装前面定义的各层进行计算的,我们注意到在给encoder的输入时,维度的顺序为(length,batch_size, d_model),而不是(batch_size, length, d_model),实际上这是为了并行计算?
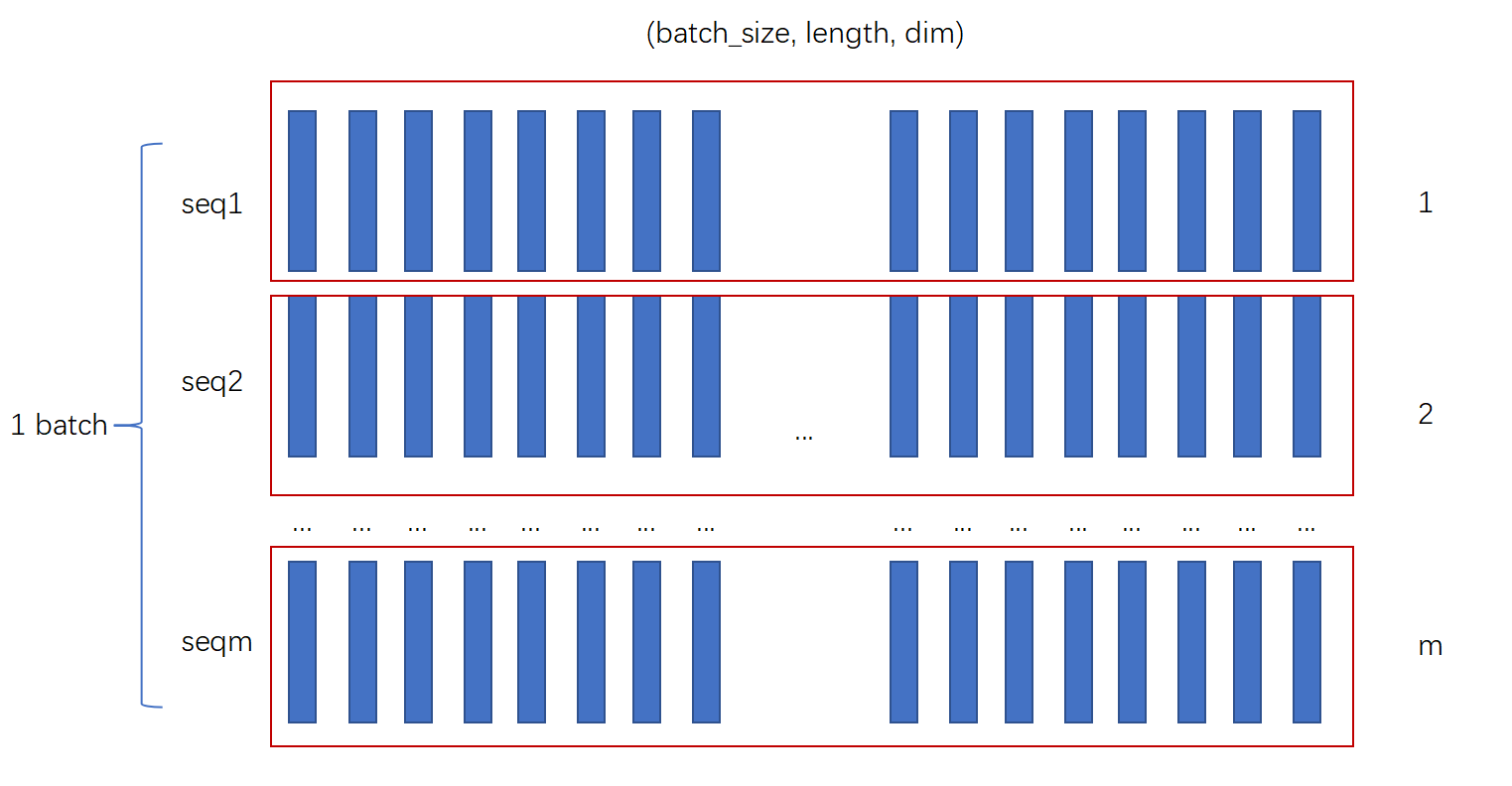
下图是batch_first时所对应的存储顺序
下图时length_first时所对应的存储顺序
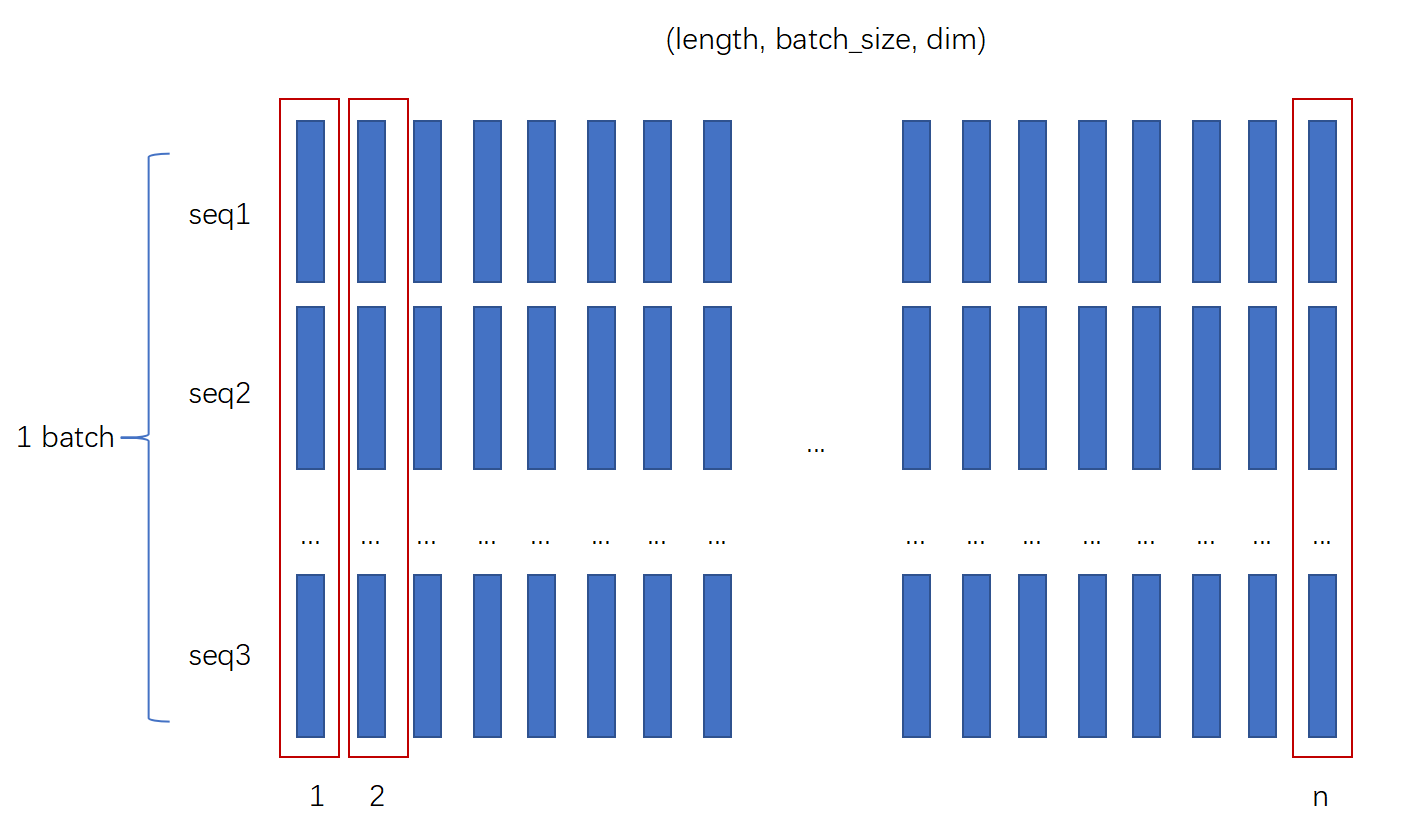
在其他时序模型中,由于需要按序输入,因此直接拿到一个sequence没啥用,不如直接得到一批batch中的所有sequence中的第一个语音序列或单词,但是在transformer中应该不需要这样吧?
另外一个小细节是进行mean pooling
stats = out.mean(dim=1)
这一步是不必可少的,不然没法输入pred_layer,这里做mean的意思是把每个sequence的所有frame通过平均合并为一个frame,如下图所示
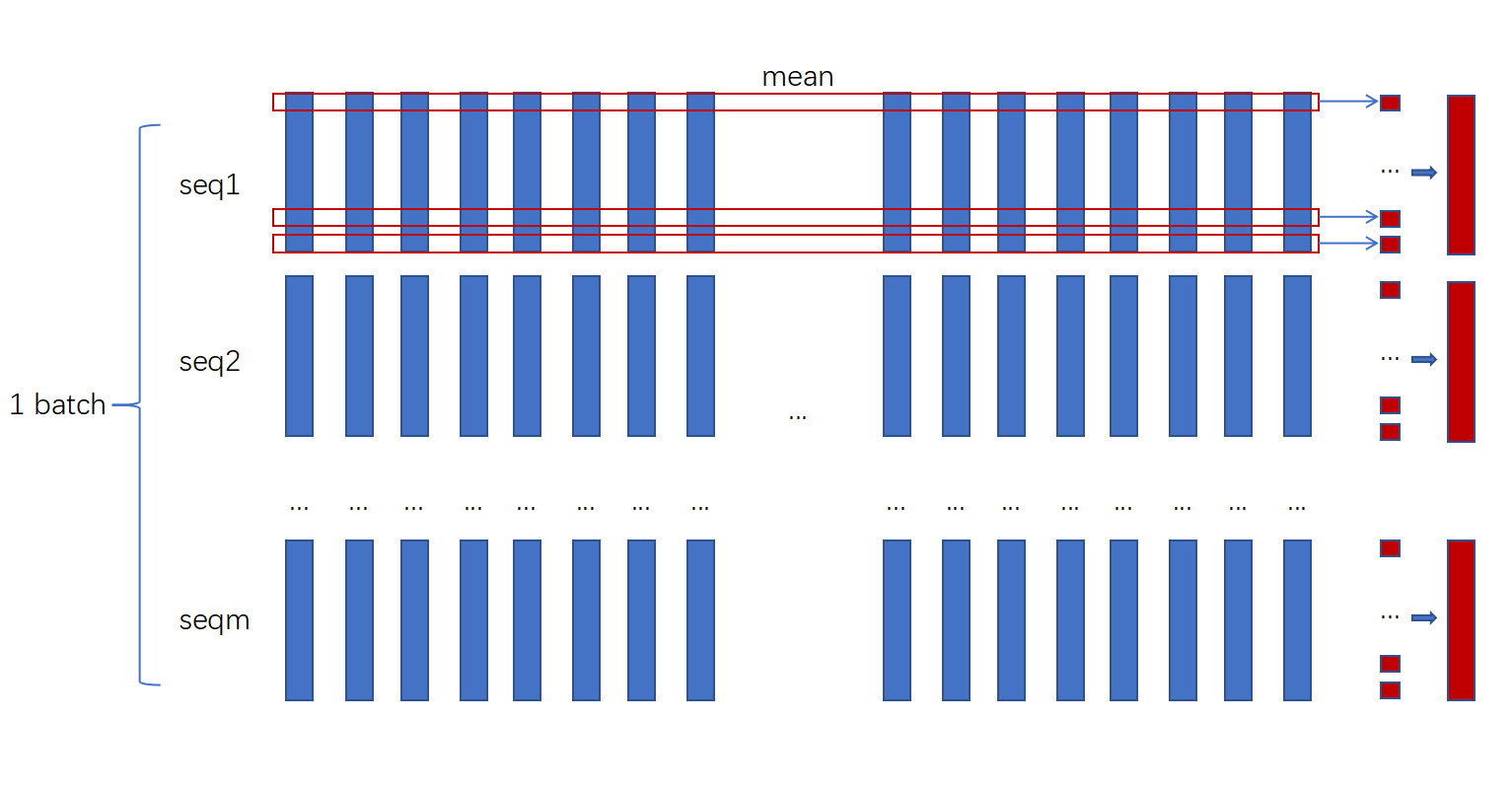
维度由batch_size\(\times\)length\(\times\)d_model变成了batch_size\(\times\)d_model
Medium Baseline
对于medium baseline,只需要调节视频中提示的地方进行修改即可,我的得分如下:

相关参数如下
d_model=120
4个encoder_layer的nhead=4
Strong Baseline
对于strong baseline,需要引入conformer架构,我的得分如下:

而conformer的引入需要注意以下几点:
引入(当然你也可以使用pip进行单独安装)
from torchaudio.models.conformer import Conformer
由于torchaudio中实现的conformer默认是batch_first,因此在代码中我们需要去掉下面两行
out = out.permute(1, 0, 2)
out = out.transpose(0, 1)
Boss Baseline
引入self-attention pooling和additive margin softmax后,准确率下降了。

李宏毅2022机器学习HW4 Speaker Identification下的更多相关文章
- 李宏毅老师机器学习课程笔记_ML Lecture 3-1: Gradient Descent
引言: 这个系列的笔记是台大李宏毅老师机器学习的课程笔记 视频链接(bilibili):李宏毅机器学习(2017) 另外已经有有心的同学做了速记并更新在github上:李宏毅机器学习笔记(LeeML- ...
- Python 机器学习实战 —— 监督学习(下)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 2: Where does the error come from?
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 1: ML Lecture 1: Regression - Demo
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 1: 回归案例研究
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 0-2: Why we need to learn machine learning?
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 0-1: Introduction of Machine Learning
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 机器学习之神经网络模型-下(Neural Networks: Representation)
3. Model Representation I 1 神经网络是在模仿大脑中的神经元或者神经网络时发明的.因此,要解释如何表示模型假设,我们不妨先来看单个神经元在大脑中是什么样的. 我们的大脑中充满 ...
- Andrew Ng机器学习课程笔记--week5(下)
Neural Networks: Learning 内容较多,故分成上下两篇文章. 一.内容概要 Cost Function and Backpropagation Cost Function Bac ...
- 机器学习模型从windows下 spring上传到预发布会导致模型不可加载
1.通过上传到redis,程序通过redis拉取模型,解决问题. 2.问题原因初步思考为windows下模型文件上传到 linux导致,待继续跟进查找.
随机推荐
- ORM-gorm
ORM-gorm 官方文档 http://gorm.book.jasperxu.com/ https://learnku.com/docs/gorm/v2 gorm文档 gorm文档2
- Prompt实战优化
1.概述 在深度学习领域,Prompt(提示语)被广泛应用于自然语言处理任务中,如文本生成.机器翻译和问答系统等.Prompt的设计对模型的性能和生成结果有着重要的影响,因此在实际应用中合理而有效地利 ...
- 【五】gym搭建自己的环境之寻宝游戏,详细定义自己myenv.py文件以及算法实现
相关文章: 相关文章: [一]gym环境安装以及安装遇到的错误解决 [二]gym初次入门一学就会-简明教程 [三]gym简单画图 [四]gym搭建自己的环境,全网最详细版本,3分钟你就学会了! [五] ...
- C# 笔记之基本语法
C#是一种现代的.通用的编程语言,由微软公司开发和推广.它于2000年发布,是一种结构化.面向对象和组件化的语言,旨在为Windows操作系统和Microsoft .NET框架提供强大的支持.可用于开 ...
- 【进阶篇】Java 实际开发中积累的几个小技巧(一)
目录 前言 一.枚举类的注解 二.RESTful 接口 三.类属性转换 四.Stream 流 五.判空和断言 5.1判空部分 5.2断言部分 文章小结 前言 笔者目前从事一线 Java 开发今年是第 ...
- 如何快速提高英飞凌单片机编译器 TASKING TriCore Eclipse IDE 编译速度
1.前言 使用英飞凌单片机编译器 TASKING TriCore Eclipse IDE 开发编译时,想必感受最深刻的就是编译速度,那是非常慢了,如果是部分修改的源文件编译还好,不用等太久,而如果选择 ...
- 案例:OGG目标端进程ABENDED处理
源端环境:RHEL 6.5 + Oracle 11.2.0.4 RAC + OGG 19.1.0.0.4 目标端环境:RHEL 7.6 + Oracle 19.3 + OGG 19.1.0.0.4 故 ...
- Kafka-启动时报错: ERROR Fatal error during KafkaServer startup. Prepare to shutdown
一.问题描述 在启动kafka时报错: ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server. ...
- 2023牛客暑期多校训练营3 ABDHJ
比赛链接 A 题解 知识点:数学. 当 \(x = 0\) 时,当且仅当 \(y = 0\) 可行. 当 \(x \neq 0\) 时,一定可行,答案为 \(|x-y|\) . 时间复杂度 \(O(1 ...
- Centos8 单机配置 Zookeeper3.6.3 集群
安装 Zookeeper 3.6.3 前提 已经安装好 JDK8+. 如果使用JDK8, 版本需要在211以上. 下载, 解压 使用root用户 wget https://downloads.apac ...