李宏毅2022机器学习HW4 Speaker Identification下
Task
Sample Baseline模型介绍
class Classifier(nn.Module):
def __init__(self, d_model=80, n_spks=600, dropout=0.1):
super().__init__()
# Project the dimension of features from that of input into d_model.
self.prenet = nn.Linear(40, d_model)
# transformer
self.encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, dim_feedforward=256, nhead=2
)
self.encoder = self.encoder_layer
self.pred_layer = nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, n_spks),
)
def forward(self, mels):
"""
args:
mels: (batch size, length, 40)
return:
out: (batch size, n_spks)
"""
# out: (batch size, length, d_model)
out = self.prenet(mels)
# out: (length, batch size, d_model)
out = out.permute(1, 0, 2)
# The encoder layer expect features in the shape of (length, batch size, d_model).
out = self.encoder(out)
# out: (batch size, length, d_model)
out = out.transpose(0, 1)
# mean pooling
stats = out.mean(dim=1)
# out: (batch, n_spks)
out = self.pred_layer(stats)
return out
模型开始对特征进行了升维以增强表示能力,随后通过transformer的encoder对数据进一步编码(未使用decoder),到这一步就包含了原来没有包含的注意力信息,以英文Sequence为例,如果原来的Sequence中每个单词是独立编码的是没有任何关联的,那么经过这一步之后,每一个单词的编码都是由其他单词编码的叠加而成。最后通过pred_layer进行预测(当然在此之前进行了一个mean pooling,这个下面会讲)。
在模型的前向传播时,模型基本是安装前面定义的各层进行计算的,我们注意到在给encoder的输入时,维度的顺序为(length,batch_size, d_model),而不是(batch_size, length, d_model),实际上这是为了并行计算?
下图是batch_first时所对应的存储顺序
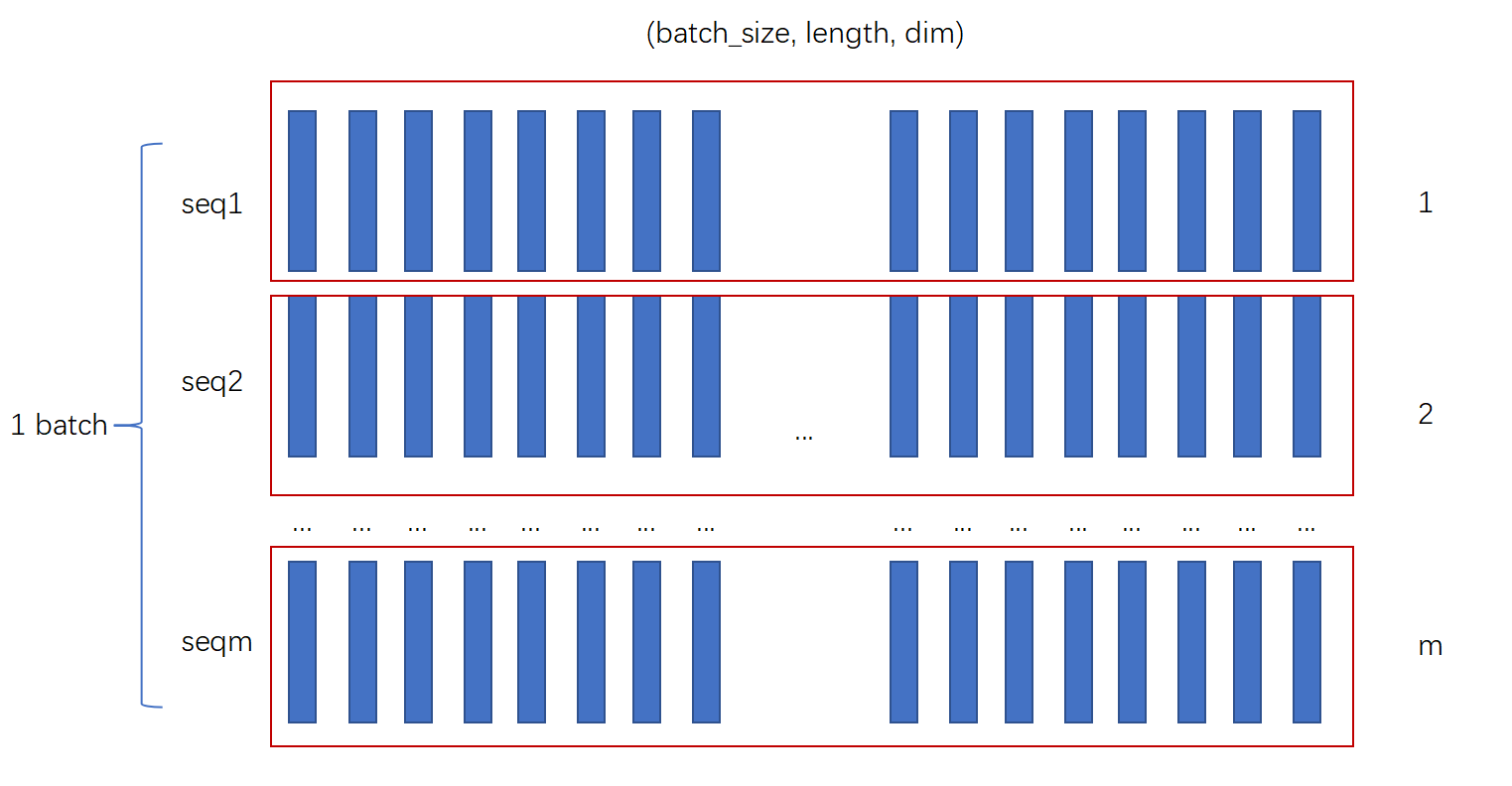
下图时length_first时所对应的存储顺序
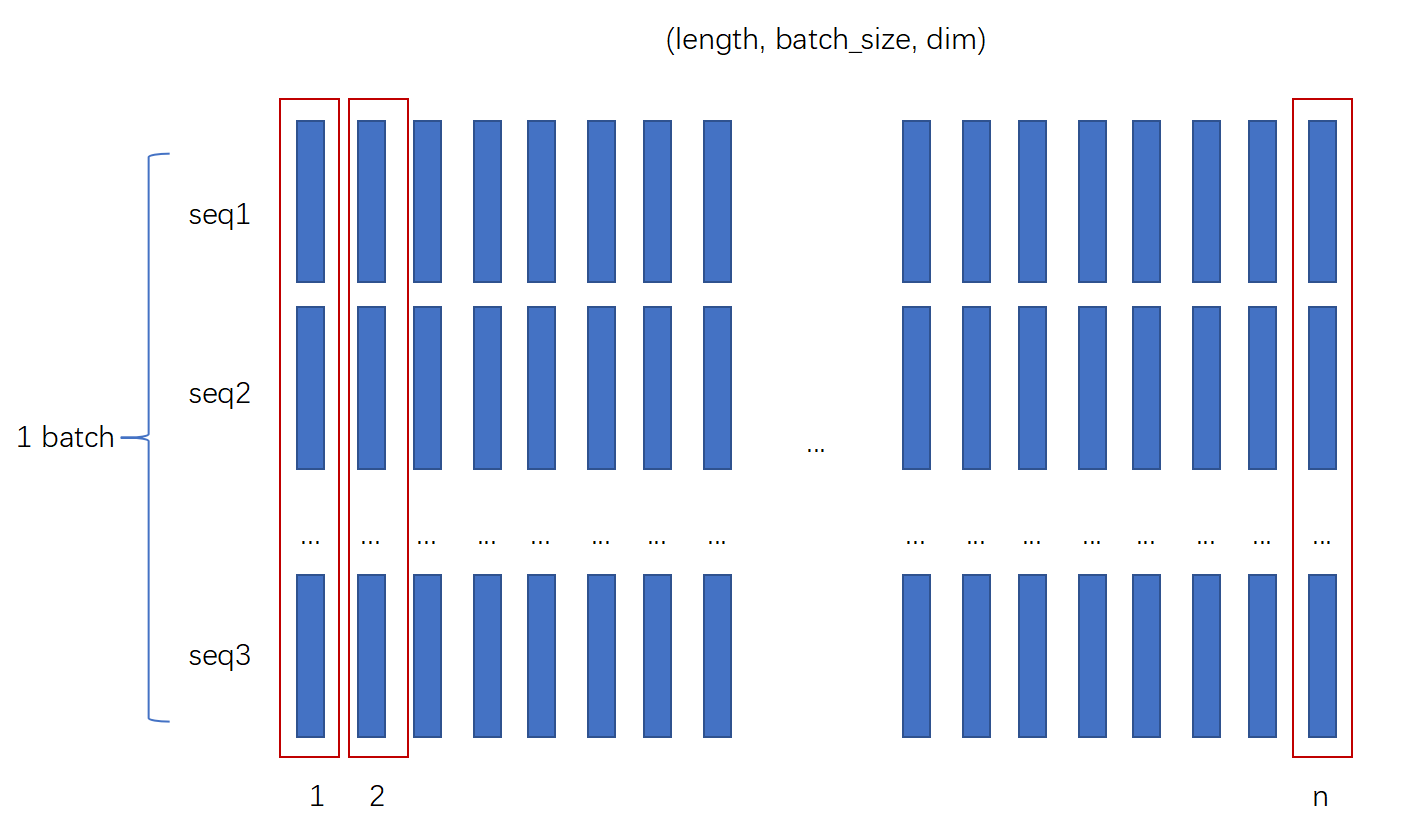
在其他时序模型中,由于需要按序输入,因此直接拿到一个sequence没啥用,不如直接得到一批batch中的所有sequence中的第一个语音序列或单词,但是在transformer中应该不需要这样吧?
另外一个小细节是进行mean pooling
stats = out.mean(dim=1)
这一步是不必可少的,不然没法输入pred_layer,这里做mean的意思是把每个sequence的所有frame通过平均合并为一个frame,如下图所示
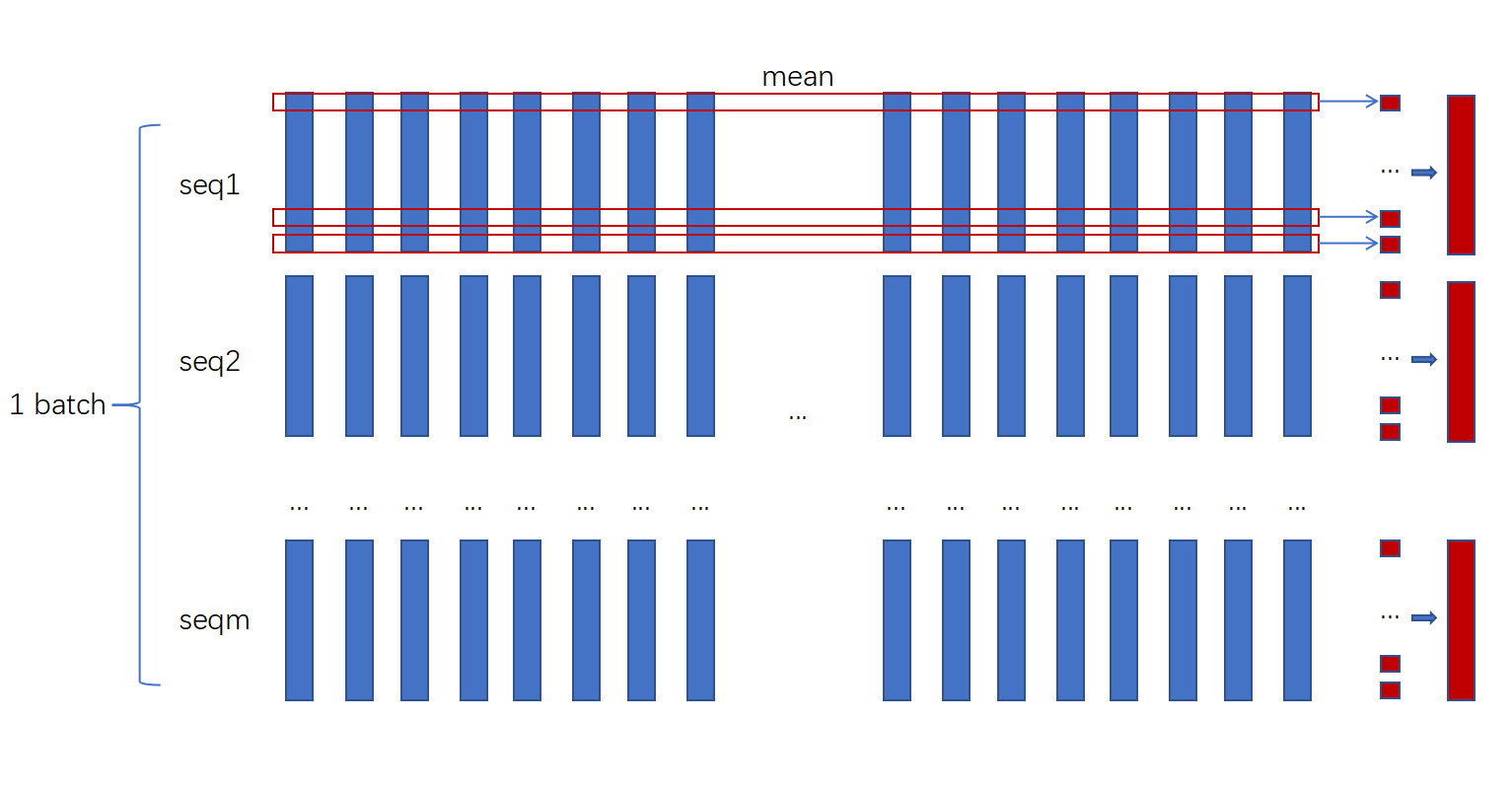
维度由batch_size\(\times\)length\(\times\)d_model变成了batch_size\(\times\)d_model
Medium Baseline
对于medium baseline,只需要调节视频中提示的地方进行修改即可,我的得分如下:

相关参数如下
d_model=120
4个encoder_layer的nhead=4
Strong Baseline
对于strong baseline,需要引入conformer架构,我的得分如下:

而conformer的引入需要注意以下几点:
引入(当然你也可以使用pip进行单独安装)
from torchaudio.models.conformer import Conformer
由于torchaudio中实现的conformer默认是batch_first,因此在代码中我们需要去掉下面两行
out = out.permute(1, 0, 2)
out = out.transpose(0, 1)
Boss Baseline
引入self-attention pooling和additive margin softmax后,准确率下降了。

李宏毅2022机器学习HW4 Speaker Identification下的更多相关文章
- 李宏毅老师机器学习课程笔记_ML Lecture 3-1: Gradient Descent
引言: 这个系列的笔记是台大李宏毅老师机器学习的课程笔记 视频链接(bilibili):李宏毅机器学习(2017) 另外已经有有心的同学做了速记并更新在github上:李宏毅机器学习笔记(LeeML- ...
- Python 机器学习实战 —— 监督学习(下)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 2: Where does the error come from?
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 1: ML Lecture 1: Regression - Demo
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 1: 回归案例研究
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 0-2: Why we need to learn machine learning?
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 0-1: Introduction of Machine Learning
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 机器学习之神经网络模型-下(Neural Networks: Representation)
3. Model Representation I 1 神经网络是在模仿大脑中的神经元或者神经网络时发明的.因此,要解释如何表示模型假设,我们不妨先来看单个神经元在大脑中是什么样的. 我们的大脑中充满 ...
- Andrew Ng机器学习课程笔记--week5(下)
Neural Networks: Learning 内容较多,故分成上下两篇文章. 一.内容概要 Cost Function and Backpropagation Cost Function Bac ...
- 机器学习模型从windows下 spring上传到预发布会导致模型不可加载
1.通过上传到redis,程序通过redis拉取模型,解决问题. 2.问题原因初步思考为windows下模型文件上传到 linux导致,待继续跟进查找.
随机推荐
- 【分享代码片段】terraform中,如何从刚刚创建的 deployment 中获得所有容器的名字和 ip
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 不好意思,刚刚才开始用 terraform,或许是更好的办 ...
- 使用三方jar中的@RestControllerAdvice不起作用
背景 公司封装了自己的基础核心包core-base,里边包含了Validation的异常捕获处理类:同时开发项目有全局异常捕获处理类,经测试发现,core-base里边的不起作用 可能原因: 未扫描外 ...
- 从嘉手札<2024-1-17>
昨天我以为 人生是一场体验 是一辆不会回头的列车 我们遇到了风景 感悟了风景 放下了风景 构成了自己 今天我以为 静水流深.光而不耀 可多思必多疑 思维是一种极为复杂的东西 我曾经觉得知行合一是对自我 ...
- SpringCloud之Ribbon负载均衡
上述案例中,我们启动了一个msg-service,然后通过DiscoveryClient来获取服务实例信息,然后获取ip和端口来访问. 但是实际环境中,我们往往会开启很多个user-service的集 ...
- 一文搞懂 Vue3 defineModel 双向绑定:告别繁琐代码!
前言 随着vue3.4版本的发布,defineModel也正式转正了.它可以简化父子组件之间的双向绑定,是目前官方推荐的双向绑定实现方式. vue3.4以前如何实现双向绑定 大家应该都知道v-mode ...
- Exadata健康检查工具EXAchk
本文根据MOS文章:Oracle Exadata Database Machine EXAchk (Doc ID 1070954.1)整理关键步骤. 注:通常都会要求使用当前最新可用的EXAchk版本 ...
- [Java]HashMap与ConcurrentHashMap的一些总结
HashMap与ConcurrentHashMap的一些总结 HashMap底层数据结构 JDK7:数组+链表 JDK8:数组+链表+红黑树 JDK8中的HashMap什么时候将链表转为红黑树? 当发 ...
- Linux命令-文件、磁盘管理
Linux命令-文件.磁盘管理 1.文件管理 查看文件信息:ls ls是英文单词list的简写,其功能为列出目录的内容,是用户最常用的命令之一,它类似于DOS下的dir命令. Linux文件或者目 ...
- JS 这一次彻底理解选择排序
壹 ❀ 引 我在 JS 这一次彻底理解冒泡排序 一文中介绍了十大经典排序中的冒泡排序,所谓冒泡排序就是不断比较相邻的两个元素,让较小的往前浮,较大的往后沉,直到所有元素找到自己对应的位置.那么现在我们 ...
- NC24911 数独挑战
题目链接 题目 题目描述 数独是一种填数字游戏,英文名叫 Sudoku,起源于瑞士,上世纪 70 年代由美国一家数学逻辑游戏杂志首先发表,名为 Number Place,后在日本流行,1984 年将 ...