Redis 6 学习笔记 1 —— NoSQL数据库介绍,Redis常用数据类型
NoSQL数据库介绍(了解)
技术的分类
1、解决功能性的问题:Java、Jsp、RDBMS、Tomcat、HTML、Linux、JDBC、SVN,
2、进一步地,解决系统功能扩展性的问题:Struts、Spring、SpringMVC、Hibernate、Mybatis.
3、最后,随着服务器压力加大,要解决系统性能的问题:NoSQL、Java线程、Hadoop、Nginx、MQ、ElasticSearch,.
NoSQL数据库概念、特点和场景
NoSQL(Not Only SQL),泛指非关系型的数据库。它不依赖业务逻辑方式存储,而以简单的key-value模式存储,因此大大增加了数据库的扩展能力。
常见的NoSQL数据库有Redis、MongoDB、Memcache、HBase、Cassandra(后两个是大数据技术用的)。
NoSQL数据库不遵循SQL标准(有着自己的一套操作),不支持事务的ACID基本特性(不代表不支持事务),有着远超于SQL的性能。
它打破了传统关系型数据库以业务逻辑为依据的存储模式而针对不同数据结构类型改为以性能为最优先的存储方式。
适用场景
1、对数据高并发的读写
2、海量数据的读写
3、系统高可扩展性
可扩展性补充说明:如果我用一台计算机解决了一些问题,当我买了第二台计算机,我只需要一半的时间就可以解决这些问题,或者说每分钟可以解决两倍数量的问题。两台计算机构成的系统如果有两倍性能或者吞吐,就是我说的可扩展性。我们希望可以通过增加机器的方式来实现扩展,但是现实中这很难实现,需要一些架构设计来将这个可扩展性无限推进下去。
不适用场景
1、需要事务支持。
不过Redis确实可以进行事务处理(但是它不支持事务回滚)。这时候就要回忆事务的原子性、一致性、隔离性、持久性是什么了。
REDIS 事务处理 -- Redis中国用户组(CRUG)
2、基于sql的结构化查询存储,处理复杂的关系,需要即席查询(即席查询是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表)。·
3、(用不着sql的和用了sql也不行的情况,请考虑用NoSql)
Redis介绍
特点:
1、数据都在内存中,支持持久化,主要用作备份恢复
2、除了支持简单的key-value模式,还支持多种数据结构的存储,比如list、set、hash、zset、string等
3、一般是作为缓存数据库辅助持久化的数据库。
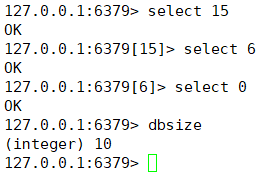
默认16个数据库,类似数组下标从0开始,初始默认使用0号库。

使用命令select<dbid>来切换数据库。如:select 8
统一密码管理,所有库同样密码。
dbsize 查看当前数据库的key的数量
flushdb 清空当前库
flushall 通杀全部库
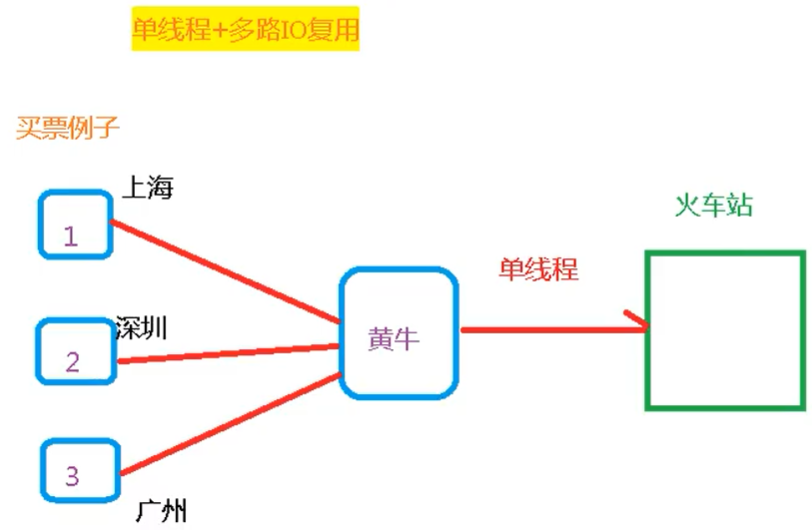
技术方面
Redis是单线程+多路IO复用技术
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。
得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。学过计组和操作系统并不难理解这些概念。
命令和数据类型
Redis命令中心(Redis commands) -- Redis中国用户组(CRUG)
常用数据类型:String、Set、Lists、Hash、Zset(也叫Sorted Set)
6.0版本三个新增的数据类型:HyperLogLog、Geospatial(Geo)、BitMap(相对来说是重点,是实现布隆过滤器的基础)
命令没什么好说的,只能是要知道上面各个组是指代什么,查文档熟能生巧。
各个数据类型的文档:
(1)五大数据类型概述:REDIS data-types -- Redis中文资料站 -- Redis中国用户组(CRUG)
(2)数据类型的详细说明(HyperLogLog和BitMap在后半部分,是英文):REDIS data-types-intro -- Redis中文资料站 -- Redis中国用户组(CRUG)
(3)Geospatial说明:这是专门用于地理空间位置的东西(纬度、经度、名称)
对各组命令的一些说明和注意点:
1、Keys是对键值对的键的操作
2、del 命令和unlink 命令类似,但是有区别。
删除是需要消耗时间的,可以先在逻辑上删除再保证业务进行的同时慢慢删掉,避免删除的并发太多导致操作阻塞或等待。

数据类型部分特点说明
1、incr命令可以操作string类型的键值对的值(数字)加一,这是原子操作,那么java的i+1是不是原子操作?
这个操作首先要把i+1的值存到一个寄存器,然后再将它赋予i,所以不是原子操作。准确来说反编译字节码文件后可以看到i++是4步,++i是3步,java里的i++是3步因为底层被优化了。
2、string的二进制安全就是,字符串不是根据某种特殊的标志来解析的,无论输入是什么,总能保证输出是处理的原始输入而不是根据某种特殊格式来处理。
REDIS字符串-二进制安全的含义_昭告天下的博客-CSDN博客_redis字符串二进制安全
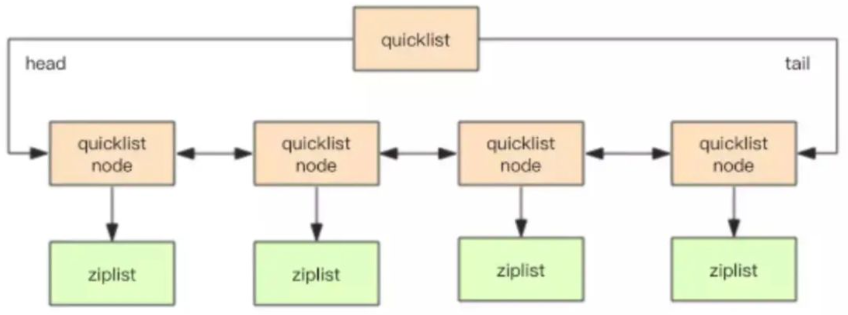
3、List的底层是一个双向链表,准确来说是quickList,它在两端的插入删除效率很高,但查询列表中间的元素是非常慢的。List相当于1个key对多个value,如果没有value了,key也就无了。
quickList就是一个标准的双向链表的配置,有head 有tail;
每一个节点是一个quicklistNode,包含prev和next指针(对比linkedList)
每一个quicklistNode 包含 一个ziplist,*zp 压缩链表里存储键值。
所以quicklist是对ziplist进行一次封装,使用小块的ziplist来既保证了少使用内存,也保证了性能。
Redis列表list 底层原理 - 知乎 (zhihu.com)
4、Redis的Set是string类型的无序集合,底层实际是一个value为null的hash表(就是说hash表中的key是Set中的值,value为null),
所以添加,删除以及测试元素是否存在 的操作时间复杂度都是O(1)。查找则是O(logn)。
Set集合的spop是随机从集合中吐出一个元素。
Redis中hash、set、zset的底层数据结构原理 - 腾讯云开发者社区-腾讯云 (tencent.com)
5、Redis hash可以类比Java中的Map<String, Object>,它的key也是不重复的。hash适合用来存储对象,并且底层是ziplist和hashtable的组合(field-value长度较短且个数较少时用ziplist,否则用hashtable,类比前面的List)

6、Zset和Set相比多了个自动排序的功能(相当于排行榜) ,也就是说成员唯一,分数可重复,添加,删除和更新元素的操作的时间复杂度是O(logn),访问集合的中间元素也非常的快,底层用了hash和跳跃表。hash作用是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
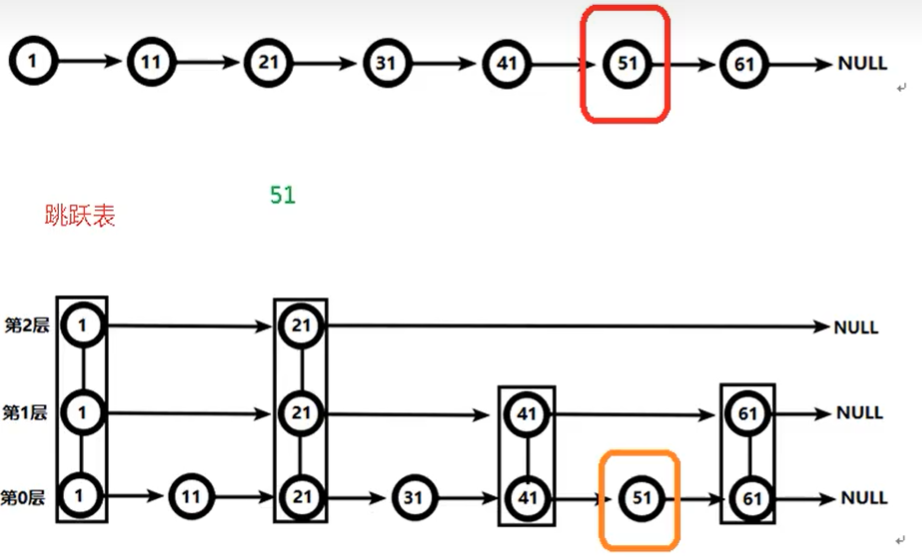
Redis数据结构——跳跃表 - Mr于 - 博客园 (cnblogs.com)
7、BitMap本身不是一种数据类型,实际上它本质就是字符串。通过特殊的命令,你可以将 String 值当作一系列 bits 处理:可以设置和清除单独的 bits,数出所有设为 1 的 bits 的数量,找到最前的被设为 1 或 0 的 bit,等等。可以把Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。
位操作分为两组:常量时间单位操作,如将位设置为1或0,或获取其值;以及对位组的操作,例如在给定的位范围内计算设置位的数量(例如,人口计数)。
位图的最大优势之一是,在存储信息时,它们通常可以极大地节省空间(因为一个String值最大长度是512MB,也就是可以操作2^32个不同的位)。例如,在一个由增量用户id表示不同用户的系统中,仅使用512 MB内存就可以记住40亿用户的单个比特信息(例如,知道用户是否想要接收时事通讯,是否访问过某个网站)。
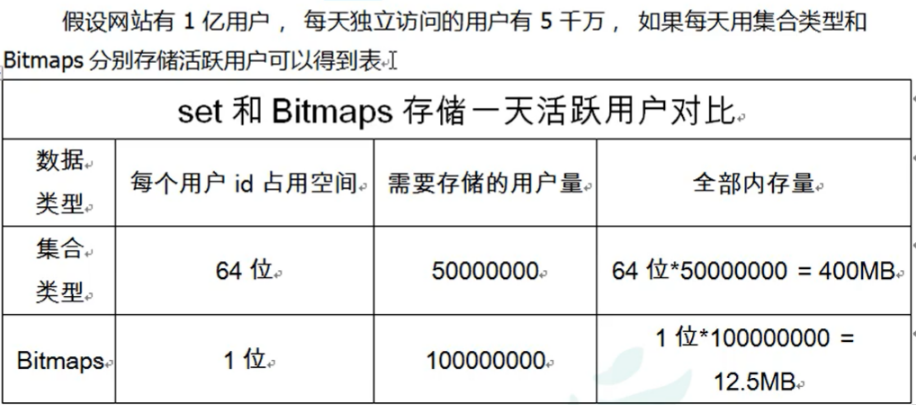
很多应用的用户id以一个指定数字(例如第一个用户id是10000)开头,直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费,通常的做法是每次做setbit操作时将用户id减去这个指定数字。

bitcount可以指定范围,结合下面看就知道了。此外bitop算是对它的一个补充,可以对两个以上的字符串进行AND、OR、NOT(这个除外)、XOR的操作,但时间复杂度是O(logn)。具体见文档。


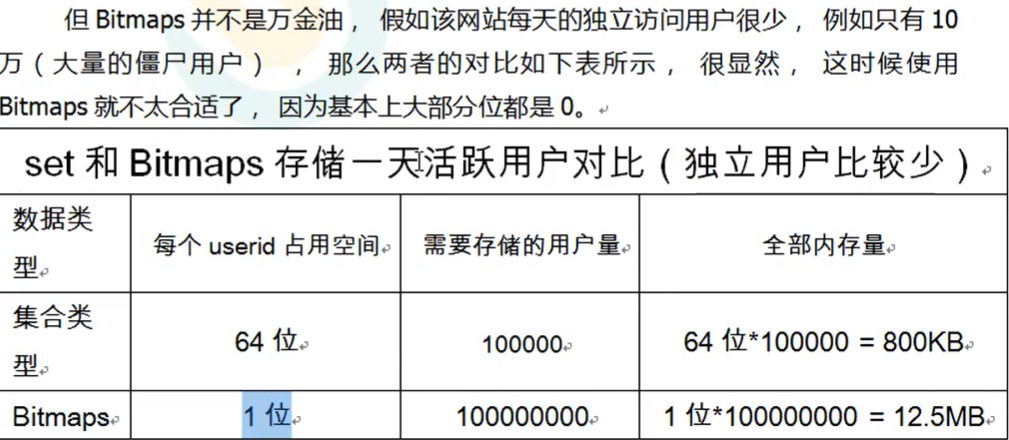
在第一次初始化Bitmaps时,假如偏移量非常大,那么整个初始化过程执行将会比较慢,可能会造成Redis的阻塞。
8、HyperLogLog主要用于统计相关的功能需求。比如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。但是像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和求和的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。而基数估计就是在误差可接受范围内,快速计算基数。
解决基数问题有很多种方案:
(1)数据存储在MySQL表中,使用distinct count 计算不重复个数
(2)使用Redis提供的hash、set、bitmaps等数据结构来处理。
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。
能否降低一定的精度来平衡存储空间?Redis推出了HyperLogLog,它是用来做基数统计的。其优点是在输入元素的数量或者体积非常大时,计算基数所需的空间总是固定的、很小的。
在Redis里面,每个HyperLogLog键只需花费12KB内存,就可以计算接近2^64个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。
9、Geospatial
Redis3.2中增加了对GE0类型的支持。GE0,Geographic,地理信息的缩写。
该类型就是元素的2维坐标,在地图上就是经纬度。Redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
补充:其它类型的NoSQL数据库(了解)
行式存储数据库(大数据时代)
行式数据库
列式数据库
HBase、Cassandra都属于这类。
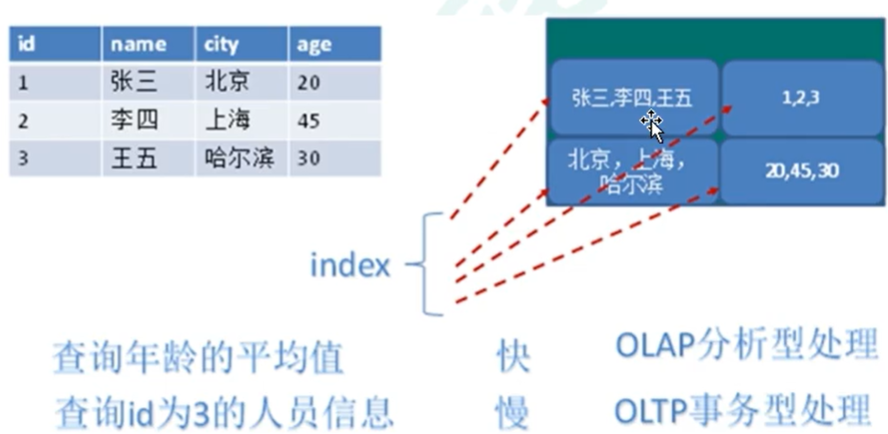
图关系型数据库
Neo4j是图关系型数据库,主要应用是社会关系、公共交通网络、地图及网络拓扑
参考博客
论文里常出现的可扩展性(Scalability)是什么意思呢?_dream_uping的博客-CSDN博客_可扩展性
Redis 6 学习笔记 1 —— NoSQL数据库介绍,Redis常用数据类型的更多相关文章
- MongoDb 学习笔记(一) --- MongoDb 数据库介绍、安装、使用
1.数据库和文件的主要区别 . 数据库有数据库表.行和列的概念,让我们存储操作数据更方便 . 数据库提供了非常方便的接口,可以让 nodejs.php java .net 很方便的实现增加修改删除功能 ...
- Redis:学习笔记-01
Redis:学习笔记-01 该部分内容,参考了 bilibili 上讲解 Redis 中,观看数最多的课程 Redis最新超详细版教程通俗易懂,来自 UP主 遇见狂神说 1. Redis入门 2.1 ...
- NOSQL数据库之 REDIS
NOSQL数据库之 REDIS 一.NOSQL 1.简介 NoSQL ,(Not Only SQL),泛指非关系型数据库. 特点: NoSQL 通常是以key-value形式存储, 不支持SQL语句, ...
- Redis in Action : Redis 实战学习笔记
1 1 1 Redis in Action : Redis 实战学习笔记 1 http://redis.io/ https://github.com/antirez/redis https://ww ...
- Redis:学习笔记-04
Redis:学习笔记-04 该部分内容,参考了 bilibili 上讲解 Redis 中,观看数最多的课程 Redis最新超详细版教程通俗易懂,来自 UP主 遇见狂神说 10. Redis主从复制 1 ...
- Redis:学习笔记-03
Redis:学习笔记-03 该部分内容,参考了 bilibili 上讲解 Redis 中,观看数最多的课程 Redis最新超详细版教程通俗易懂,来自 UP主 遇见狂神说 7. Redis配置文件 启动 ...
- Redis:学习笔记-02
Redis:学习笔记-02 该部分内容,参考了 bilibili 上讲解 Redis 中,观看数最多的课程 Redis最新超详细版教程通俗易懂,来自 UP主 遇见狂神说 4. 事物 Redis 事务本 ...
- SQLMAP学习笔记2 Mysql数据库注入
SQLMAP学习笔记2 Mysql数据库注入 注入流程 (如果网站需要登录,就要用到cookie信息,通过F12开发者工具获取cookie信息) sqlmap -u "URL" - ...
- Python操作nosql数据库之redis
一.NoSQL的操作 NoSQL,泛指非关系型的数据库.随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不 ...
- redis是当前流行的nosql数据库
redis是当前流行的nosql数据库,很多网站都用它来做缓存,今天我们来安装并配置下redis 二.安装并配置redis 1.安装redis sudo apt-get install redis-s ...
随机推荐
- Java在算法竞赛中的一些技巧
转载请注明出处(- ̄▽ ̄)- 谈到算法竞赛中使用Java,那么有一个绕不开的点就是如何快速地输入输出.通常来说,Scanner类固然可以帮助我们顺利地完成各种输入要求,而syso(System.o ...
- HCL实验:4.同一vlan位于不同交换机上的通信
拓扑图 SW1配置 SW2配置 SW3配置 VLAN 1 PC1 PING PC5 VLAN 2 PC 2 PING PC 6 VLAN 3 PC4 PING PC8 怀疑是模拟器的问题---- 不知 ...
- Excel 进度图表制作
Excel 改变图标的形状 最终效果 过程有点杂乱,不再重新整理,基本照着下面的设就完事了. 未完成的想用柱型,和已完成的相结合 右击,更改表类型 选择簇状柱形图.次标轴 注意主.次坐标 进度改为折线 ...
- hdfs小文件合并
HDFS small file merge 1.hive Settings There are 3 settings that should be configured before archivin ...
- 我真的想知道,AI框架跟计算图什么关系?PyTorch如何表达计算图?
目前主流的深度学习框架都选择使用计算图来抽象神经网络计算表达,通过通用的数据结构(张量)来理解.表达和执行神经网络模型,通过计算图可以把 AI 系统化的问题形象地表示出来. 本节将会以AI概念落地的时 ...
- Redis 备忘录
redis是什么 Redis 是一个高性能的key-value数据库 常用操作 下载 官网:https://redis.io/ Linux版:https://redis.io/download Win ...
- SSH远程主机执行命令:s2c
#!/bin/bash ip=$1 ip_num=$(echo $ip | awk -F\. '{print NF}') if [ $ip_num -eq 2 ]; then ip=192.168.$ ...
- Typescript:基础语法学习(尚硅谷 李立超)
官方文档:https://www.tslang.cn/docs/handbook/typescript-in-5-minutes.html 搭建开发环境 npm i -g typescript安装完成 ...
- Postgresql: 常用配置
允许远程链接postgresql 要允许 PostgreSQL 数据库允许远程连接,需要进行以下配置步骤: 打开 PostgreSQL 的主配置文件 postgresql.conf.通常,该文件位于以 ...
- Mybatis开发中的常用Maven配置
Mybatis导入Maven配置 <!-- MyBatis导入 --> <dependency> <groupId>org.mybatis</groupId& ...