PaddleOCR 服务化部署(基于PaddleHub Serving)
最近用到百度飞桨的 PaddleOCR,研究了一下PaddleOCR的服务化部署,简单记录一些部署过程和碰到的问题。
基础环境
- paddlepaddle 2.5.2
- python 3.7
- paddlehub 2.1.0
- PaddleOCR 2.6
- pip 20
#查看 python 版本
python --version
#查看pip版本
pip --version
#查看paddlepaddle版本
pip show paddlepaddle
部署过程中也尝试多次,不同版本遇到的问题不尽相同,这里选取其中一组进行部署说明
使用 docker部署paddlepaddle2.5.2容器
PaddleOCR依赖飞桨环境运行,所以需要先安装paddlepaddle环境,默认docker已经安装,执行脚本获取paddlepaddle2.5.2镜像并自动创建名称为ppocr的容器,网络顺畅的话很快就可以下载完成,下载完成后执行attach命令就可以进入容器继续操作。官方paddlepaddle2.5.2容器内python版本为3.7,pip版本为20,默认即可。
# 下载并创建容器
docker run -p 9997:9997 --name ppocr -itd -v $PWD:/paddle registry.baidubce.com/paddlepaddle/paddle:2.5.2 /bin/bash # 进入容器
docker attach ppocr
参数说明
参数 说明 -p 指定 docker 映射的端口 -name 指定容器的名称 docker部分常用管理命令#查看容器情况
docker ps -a #停止容器
docker stop ppocr #启动容器
docker start ppocr #查看所有镜像
docker images
以下操作都在容器内进行
安装paddlehub
- 进入容器后执行脚本安装paddlehub,版本为2.1.0
pip3 install paddlehub==2.1.0 --upgrade -i https://mirror.baidu.com/pypi/simple
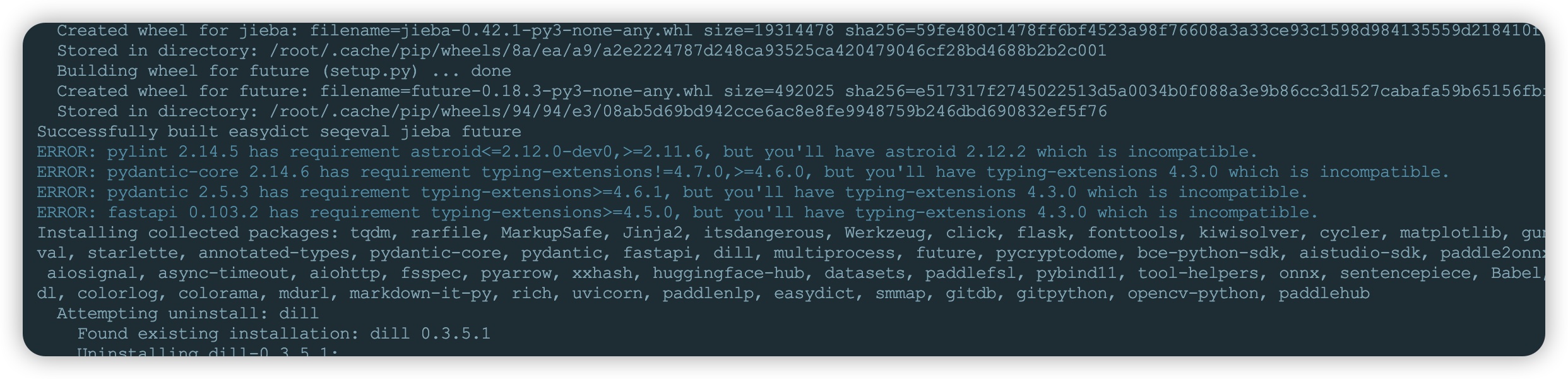
- 安装过程中会提示
typing-extensions版本过低,要求版本要大于4.6.1,卸载当前版本安装指定版本,安装完成后再次执行上述命令安装paddlehub,安装时间较长等待安装完成接口。
#卸载当前包
pip uninstall typing-extensions #安装4.6.1版本
pip3 install typing-extensions==4.6.1
安装PaddleOCR 2.6.0
PaddleOCR 使用 2.6.0版本
- 首先从gitee获取PaddleOCR代码,PaddleOCR在gitee仓库的最新版本为2.6.0,在 github仓库的最新版本为2.7.1,2.7.1依赖 python 版本需要>=3.8,此处需要注意.
cd /home
git clone https://gitee.com/paddlepaddle/PaddleOCR.git
- 代码下载完成后进入PaddleOCR文件夹内执行脚本安装依赖包
cd /home/PaddleOCR
#安装依赖包
pip3 install -r requirements.txt -i https://mirror.baidu.com/pypi/simple
hubserving服务配置
hubserving服务部署目录下包括文本检测、文本方向分类,文本识别、文本检测+文本方向分类+文本识别3阶段串联,版面分析、表格识别和PP-Structure七种服务包,可以按需安装使用,使用前需要下载对应模型并进行配置,以下已文本检测+文本方向分类+文本识别3阶段串联服务(ocr_system)和表格识别(structure_table)为例进行说明。
文本检测+文本方向分类+文本识别3阶段串联服务(ocr_system)配置
- 相关模型下载
cd /home/PaddleOCR
mkdir inference && cd inference # 下载并解压 OCR 文本检测配置
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar && tar -xf ch_PP-OCRv3_det_infer.tar # 下载并解压 OCR 文本识别模型
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar && tar -xf ch_PP-OCRv3_rec_infer.tar # 下载并解压 OCR 文本方向分类模型
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_infer.tar
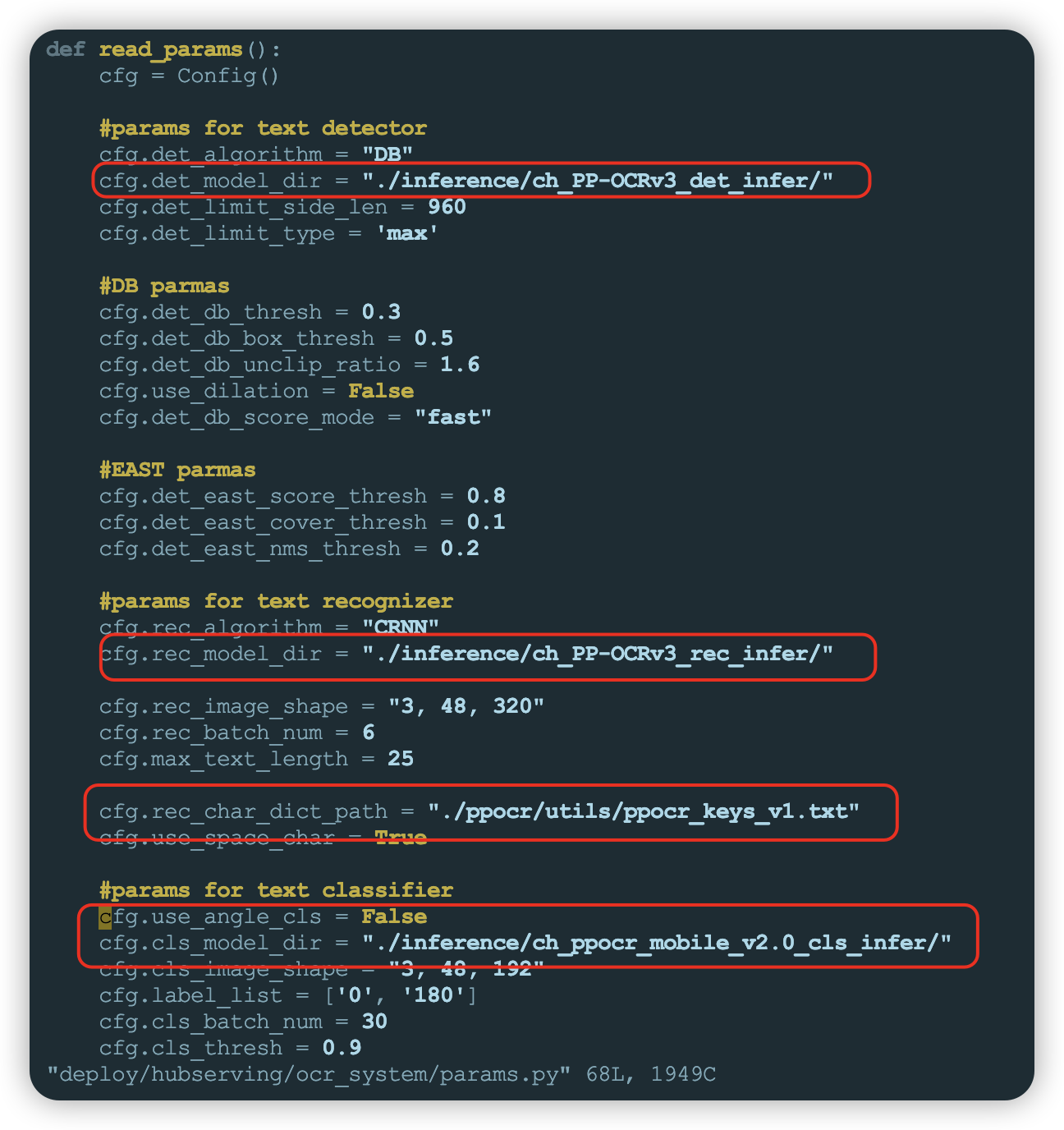
- 服务配置
文本检测+文本方向分类+文本识别3阶段串联服务(ocr_system)配置文件是deploy/hubserving/ocr_system/params.py,包含模型路径和相关参数,这里使用默认配置即可,如果更换模型需要对应修改配置文件。
- 相关模型下载
表格识别服务(structure_table)配置
- 下载中文表格识别模板
cd /home/PaddleOCR/inference
#下载基于SLANet的中文表格识别模型
wget https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/ch_ppstructure_mobile_v2.0_SLANet_infer.tar && tar xf ch_ppstructure_mobile_v2.0_SLANet_infer.tar
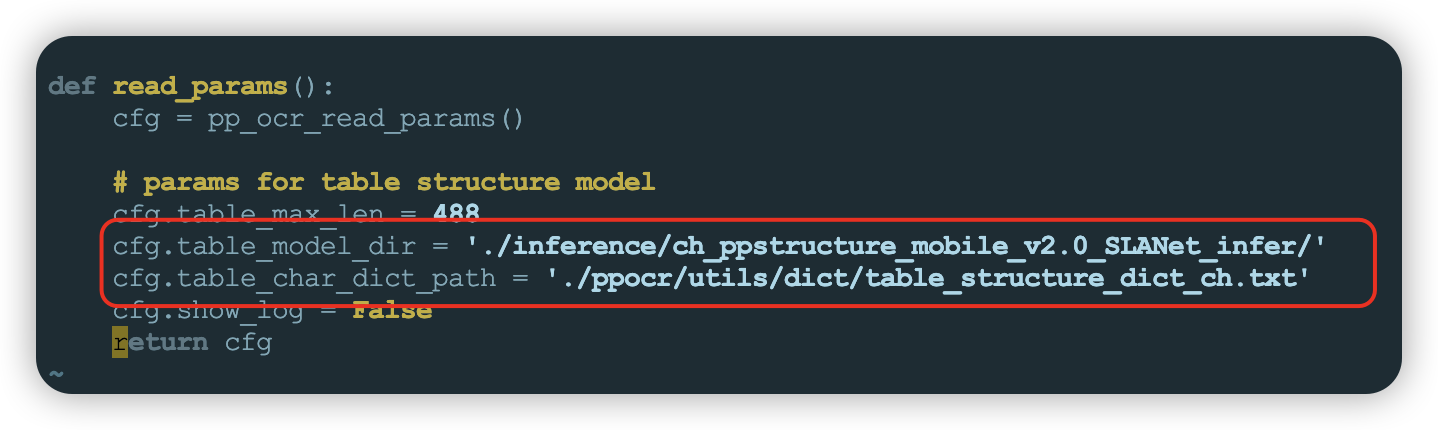
- 服务配置
structure_table默认配置为英文表格识别模型和英文字典,需要调整为中文识别模板和对应的中文字典文件,修改完成保存即可。#打开配置文件
vim /home/PaddleOCR/deploy/hubserving/structure_table/param.py
#调整模型文件路径为./inference/ch_ppstructure_mobile_v2.0_SLANet_infer/
#调整字典文件路径为./ppocr/utils/dict/table_structure_dict_ch.txt
- 下载中文表格识别模板
hubserving服务安装
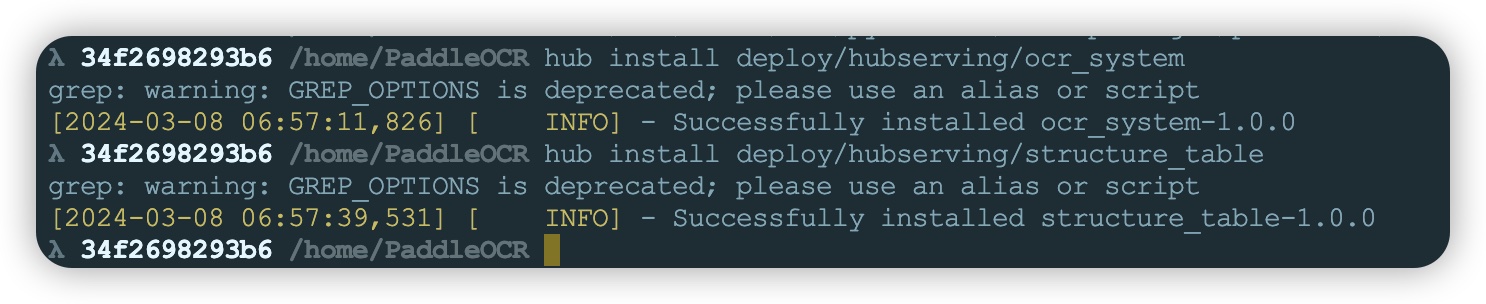
- 服务配置完成就可以安装服务了,后续如果服务相关配置存在变动需要重新执行以下命令安装服务
cd /home/PaddleOCR #安装ocr_system服务
hub install deploy/hubserving/ocr_system #安装structure_table服务
hub install deploy/hubserving/structure_table
安装完成
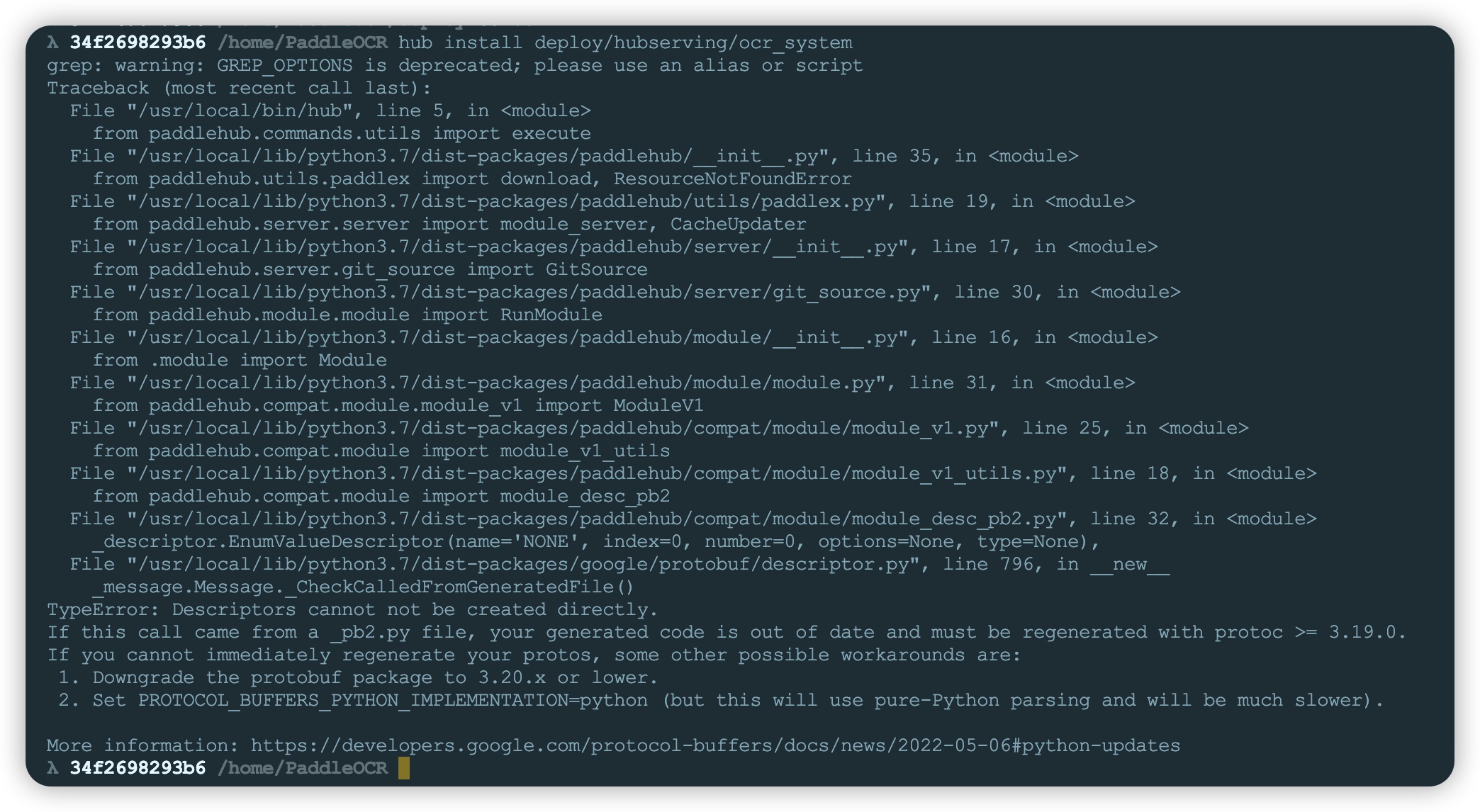
- 错误1:服务安装时会提示
protobuf版本过高,可以卸载当前版本安装指定版本3.20.2即可pip uninstall protobuf
pip install protobuf==3.20.2
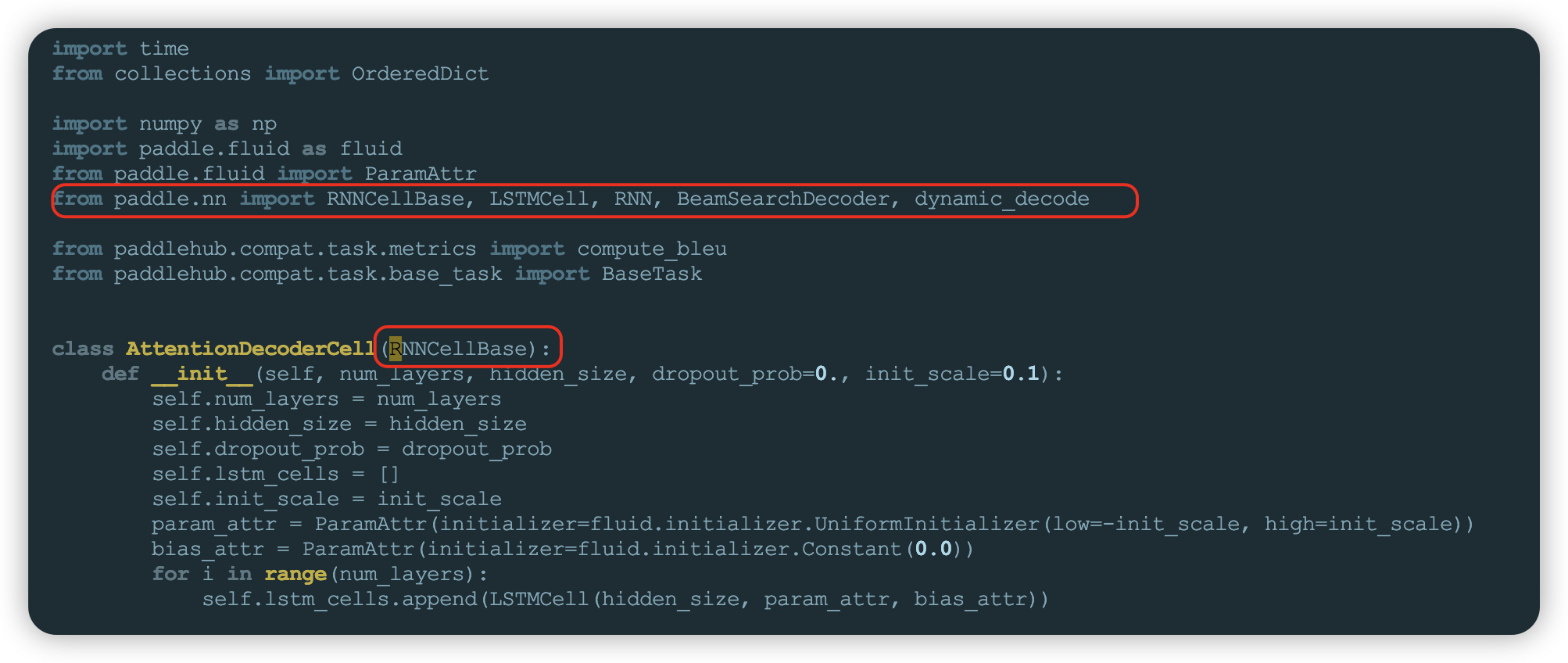
- 错误2:服务安装时还会提示
cannot import name 'RNNCell' from 'paddle.fluid.layers'

这是因为paddlepaddle2.5.0后没有fluid了,需要修改paddlehub安装包中的/usr/local/lib/python3.7/dist-packages/paddlehub/compat/task/text_generation_task.py文件,将文件中paddle.fluid.layers import RNNCell ...换成from paddle.nn import RNNCellBase,对应变量引入也需要修改,修改如下
hubserving服务启动
#以后台形式启动ocr_system structure_table 服务
nohup hub serving start -m ocr_system structure_table -p 9997 &
#查看启动日志
tail -f nohup.out
**参数说明**
| 参数 | 说明 |
| ------------ | ------------ |
| -m | 指定启动的服务名称,多个用空格隔开 |
| -p | 指定服务端口 |
启动成功

接口访问路径
ocr_system:http://127.0.0.1:9997/predict/ocr_systemstructure_table:http://127.0.0.1:9997/predict/structure_table
接口说明参数 说明 请求类型 post Content-Type application/json 参数格式
相关参考文档
官方PaddleHub Serving部署文档
PP-Structure 系列模型列表
PP-OCR系列模型列表
解决RNNCell问题参考文档
PaddleOCR 服务化部署(基于PaddleHub Serving)的更多相关文章
- 服务化部署框架Paddle Serving
服务化部署框架Paddle Serving 概述 常见的深度学习模型开发流程需要经过问题定义.数据准备.特征提取.建模.训练过程,以及最后一个环--将训练出来的模型部署应用到实际业务中.如图1所示,当 ...
- PaddleOCR(PaddleHub Serving)离线部署包制作
PaddleOCR(PaddleHub Serving)离线部署包制作 环境与版本: 系统 CPU架构 Anaconda3 PaddlePaddle PaccleOCR 银河麒麟Server V10 ...
- 基于TensorFlow Serving的深度学习在线预估
一.前言 随着深度学习在图像.语言.广告点击率预估等各个领域不断发展,很多团队开始探索深度学习技术在业务层面的实践与应用.而在广告CTR预估方面,新模型也是层出不穷: Wide and Deep[1] ...
- Glue4Net简单部署基于win服务的Socket程序
smark 专注于高并发网络和大型网站架规划设计,提供.NET平台下高吞吐的网络通讯应用技术咨询和支持 Glue4Net简单部署基于win服务的Socket程序 在写一些服务应用的时候经常把要它部署到 ...
- Centos6.5中Nginx部署基于IP的虚拟…
Centos6.5 中Nginx 部署基于IP 的虚拟主机 王尚2014.11.18 一.介绍虚拟主机 虚拟主机是使用特殊的软硬件技术,把一台真实的物理电脑主机 分割成多个逻辑存储单元,每个单元都没有 ...
- 使用Docker Compose部署基于Sentinel的高可用Redis集群
使用Docker Compose部署基于Sentinel的高可用Redis集群 https://yq.aliyun.com/articles/57953 Docker系列之(五):使用Docker C ...
- 部署基于Gitlab+Docker+Rancher+Harbor的前端项目这一篇就够了
部署基于Gitlab+Docker+Rancher+Harbor的前端项目这一篇就够了 安大虎 momenta 中台开发工程师 6 人赞同了该文章 就目前的形势看,一家公司的运维体系不承载在 Do ...
- 部署基于.netcore5.0的ABP框架后台Api服务端,以及使用Nginx部署Vue+Element前端应用
前面介绍了很多关于ABP框架的后台Web API 服务端,以及基于Vue+Element前端应用,本篇针对两者的联合部署,以及对部署中遇到的问题进行处理.ABP框架的后端是基于.net core5.0 ...
- 部署基于国际版Azure的SharePoint三层架构服务器场
前言 微软Azure国际版已经很普及了,这里没有用国内版(世纪互联),用的是国际版,当然是由于公司性质的缘故.这里一步步图文的方式,分享给大家创建Azure国际版的SharePoint三层架构的过程, ...
- 在CentOS上部署基于dnx/coreclr的ASP.NET 5应用程序
在Ubuntu上写好了一个简单的ASP.NET 5应用程序,尝试将这个程序部署在没有mono环境的CentOS服务器上. 部署步骤如下: 1)安装libuv(KestrelHttpServer需要它) ...
随机推荐
- 安装 Nginx 修改默认端口
用远程工具连接我们上次购买的机器,这里我要介绍一个知识点,博主使用的工具是 MobaXterm,这个工具有一个多操作的功能,在下图的位置可以开启多操作,然后连接你的服务器机子即可: 首先我们将机子里面 ...
- 【Mysql】复合主键的索引
复合主键在where中使用查询的时候到底走不走索引呢?例如下表: create table index_test ( a int not null, b int not null, c int not ...
- LyScript 通过PEB结构解析堆基址
LyScript中默认并没有提供获取进程堆基址的函数,不过却提供了获取PEB/TEB的函数,以PEB获取为例,可以调用dbg.get_peb_address(local_pid)用户传入当前进程的PI ...
- 顺颂秋冬<一>
起名字真难. 原来想给这个合集起个积极的名字,记录鄙人浅薄的认知和内心的荒芜. 以及所遇见的温暖. 想来想去,不过是 浮生旧茶 西楼残月之类的 难堪大用. 后来想起来一句, 即,顺颂时祺,秋绥冬禧, ...
- Docker从认识到实践再到底层原理(八)|Docker网络
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助. 高质量博客汇总 然后就是博主最近最花时间的一 ...
- ABP vNext系列文章和视频
<Mastering ABP Framework>图书目录 第一部分 企业级软件开发和ABP框架 ABP框架入门 ABP应用开发(Step by Step)-上篇 ABP应用开发(Step ...
- Java应用系统监控方法简介
1. tsar 阿里巴巴开源的实时系统监控工具.其内部的sunfire有部分指标就是基于该工具每分钟采集一次来获取的. github 监控项及数据来源一览 摘自tsar/info.md 监控项 来源 ...
- Java-将文本(字符串)转化成二进制字符
今天在测试MySQL的Blob相关类型时,这种一般存放的是二进制文本,所以就想插入二进制文本. package com.aaa.dao; public class aaa { public stati ...
- 机器学习基础03DAY
特征降维 降维 PCA(Principal component analysis),主成分分析.特点是保存数据集中对方差影响最大的那些特征,PCA极其容易受到数据中特征范围影响,所以在运用PCA前一定 ...
- JS leetcode 两个数组的交集I II 合集题解分析
壹 ❀ 引 前些日子,在与博客园用户MrSmileZhu闲聊中,我问到了他先前在字节跳动面试中遇到了哪些算法题(又戳到了他的伤心处),因为当时面试的高度紧张,原题描述已经无法重现了,但大概与数组合并. ...