JSON多层嵌套复杂结构数据扁平化处理转为行列数据
背景
公司的中台产品,需要对外部API接口返回的JSON数据进行采集入湖,有时候外部API接口返回的JSON数据层级嵌套比较深,举个栗子:
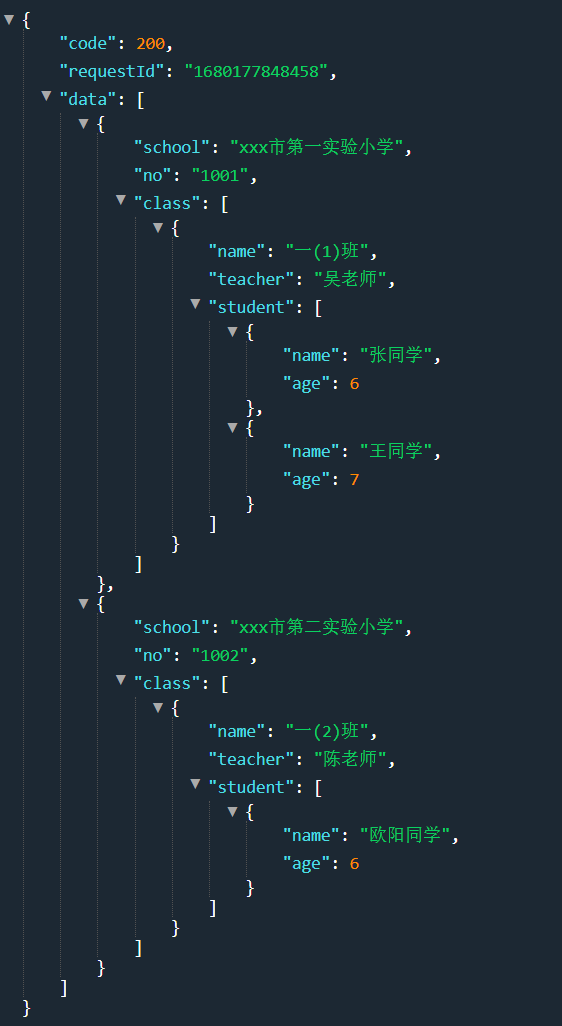
上述的JSON数据中,最外层为请求返回对象,data里面包含返回的业务数据,业务数据按照学校 / 班级 / 学生进行嵌套
在数据入湖时,需要按照最内层的学生视角将数据拆分为行列数据,最终的拆分结果如下:

由于对接的外部API接口返回的JSON数据结构不是统一的、固定的,所以需要通过一种算法对每一层对象、数组进行遍历和钻取,实现JSON数据的扁平化
网上找了一些JSON扁平化的中间件,例如:Json2Flat在扁平化处理过程不太完美,不支持跨层级的数组嵌套结构
所以决定自己实现扁平化处理
关键代码如下:
public class LinkedNode {
private LinkedNode parent;
private String parentName;
private Map<String, Object> data;
public LinkedNode(LinkedNode parent, String parentName, Map<String, Object> data) {
this.parent = parent;
this.parentName = parentName;
this.data = data;
}
}
public class JSONFlatProcessor {
private LinkedList<LinkedNode> nodes;
private LinkedList<String> column;
private List<Object[]> data;
public void find(LinkedNode parent, String parentName, Map<String, Object> data) {
LinkedNode node = new LinkedNode(parent, parentName, data);
if (!hasObjectOrArray(data)) {
nodes.add(node);
} else {
for (Map.Entry entry : data.entrySet()) {
if (entry.getValue() instanceof Map) {
find(node, String.valueOf(entry.getKey()), (Map<String, Object>) entry.getValue());
} else if (isObjectArray(entry.getValue())) {
find(node, String.valueOf(entry.getKey()), (List<Map<String, Object>>) entry.getValue());
}
}
}
}
public void find(LinkedNode parent, String parentName, List<Map<String, Object>> data) {
for (Map<String, Object> item : data) {
find(parent, parentName, item);
}
}
protected Boolean hasObjectOrArray(Map<String, Object> item) {
Object field;
for (Map.Entry entry : item.entrySet()) {
field = entry.getValue();
if (field instanceof Map || isObjectArray(field)) {
return Boolean.TRUE;
}
}
return Boolean.FALSE;
}
protected Boolean isObjectArray(Object object) {
return object instanceof List
&& !CollectionUtils.isEmpty((List) object)
&& ((List) object).get(0) instanceof Map;
}
public JSONFlatProcessor process(List<Map<String, Object>> data) {
nodes = new LinkedList<>();
find(null, null, data);
return this;
}
public JSONFlatProcessor process(Map<String, Object> data) {
nodes = new LinkedList<>();
find(null, null, data);
return this;
}
public LinkedList<LinkedNode> getNodes() {
return nodes;
}
public List<String> getColumn() {
if (CollectionUtils.isEmpty(nodes)) {
return Collections.emptyList();
}
column = new LinkedList<>();
collectColumn(nodes.getFirst());
return column;
}
protected void collectColumn(LinkedNode node) {
List<String> innerColumn = new ArrayList<>(node.getData().size());
String columnBuilder;
for (Map.Entry entry : node.getData().entrySet()) {
if (!(entry.getValue() instanceof Map || isObjectArray(entry.getValue()))) {
columnBuilder = null == node.getParentName()? String.valueOf(entry.getKey()) : String.format("%s.%s", node.getParentName(), entry.getKey());
innerColumn.add(columnBuilder);
}
}
column.addAll(0, innerColumn);
if (null != node.getParent()) {
collectColumn(node.getParent());
}
}
public List<Object[]> getData() {
if (CollectionUtils.isEmpty(nodes)) {
return Collections.emptyList();
}
data = new ArrayList<>(nodes.size());
LinkedList<Object> container;
for (LinkedNode node : nodes) {
container = new LinkedList<>();
collectData(node, container);
data.add(container.toArray());
}
return data;
}
protected void collectData(LinkedNode node, LinkedList<Object> container) {
List<Object> innerData = new ArrayList<>(node.getData().size());
for (Map.Entry entry : node.getData().entrySet()) {
if (!(entry.getValue() instanceof Map || isObjectArray(entry.getValue()))) {
innerData.add(entry.getValue());
}
}
container.addAll(0, innerData);
if (null != node.getParent()) {
collectData(node.getParent(), container);
}
}
protected static class CollectionUtils {
public static boolean isEmpty(Collection<?> collection) {
return (collection == null || collection.isEmpty());
}
}
}
public class MainTests {
public static void main(String[] args) throws Exception {
String jsonStr = "{\"code\":200,\"requestId\":\"1680177848458\",\"data\":[{\"school\":\"xxx市第一实验小学\",\"no\":\"1001\",\"class\":[{\"name\":\"一(1)班\",\"teacher\":\"吴老师\",\"student\":[{\"name\":\"张同学\",\"age\":6},{\"name\":\"王同学\",\"age\":7}]}]},{\"school\":\"xxx市第二实验小学\",\"no\":\"1002\",\"class\":[{\"name\":\"一(2)班\",\"teacher\":\"陈老师\",\"student\":[{\"name\":\"欧阳同学\",\"age\":6}]}]}]}";
ObjectMapper jsonMapper = new ObjectMapper();
// List<Map<String, Object>> map = jsonMapper.readValue(jsonStr, List.class);
Map<String, Object> map = jsonMapper.readValue(jsonStr, Map.class);
JSONFlatProcessor processor = new JSONFlatProcessor().process(map);
System.out.println("数据条数: " + processor.getNodes().size());
System.out.println("字段名: " + processor.getColumn());
System.out.println("首行数据: " + new ObjectMapper().writeValueAsString(processor.getData().get(0)));
}
}
数据条数: 3
字段名: [code, requestId, data.school, data.no, class.name, class.teacher, student.name, student.age]
首行数据: [200,"1680177848458","xxx市第一实验小学","1001","一(1)班","吴老师","张同学",6]
JSON多层嵌套复杂结构数据扁平化处理转为行列数据的更多相关文章
- 【SpringBoot】 Java中如何封装Http请求,以及JSON多层嵌套解析
前言 本文中的内容其实严格来说不算springboot里面的特性,属于JAVA基础,只是我在项目中遇到了,特归纳总结一下. HTTP请求封装 目前JAVA对于HTTP封装主要有三种方式: 1. JAV ...
- Json多层嵌套,要怎么提取?
一直用Jmeter的Json Extactor,对于多层的Json嵌套,很好用,自己写代码的时候,总是遇到各种Exception 看了网上的资料,整理一下 1. 最简单的JSON提取,只有一层的时候 ...
- mybatis 注解写法 多层嵌套foreach,调用存储过程,批量插入数据
@Select("<script>" + "DECLARE @edi_Invoice_Details edi_Invoice_Details;" + ...
- 【JS简洁之道小技巧】第一期 扁平化数组
介绍两种方法,一是ES6的flat,简单粗暴.二是递归,也不麻烦. flat ES6自带了flat方法,用于使一个嵌套的数组扁平化,默认展开一个嵌套层.flat方法接收一个数字类型参数,参数值即嵌套层 ...
- ASP.NET提取多层嵌套json数据的方法
本文实例讲述了ASP.NET利用第三方类库Newtonsoft.Json提取多层嵌套json数据的方法,具体例子如下. 假设需要提取的json字符串如下: {"name":&quo ...
- .net(c#)提取多层嵌套的JSON
Newtonsoft.Json.Net20.dll 下载请访问http://files.cnblogs.com/hualei/Newtonsoft.Json.Net20.rar 在.net 2.0中提 ...
- [转]easyui tree 模仿ztree 使用扁平化加载json
原文地址:http://my.oschina.net/acitiviti/blog/349377 参考文章:http://www.jeasyuicn.com/demo/treeloadfilter.h ...
- c#多层嵌套Json
Newtonsoft.Json.Net20.dll 下载请访问http://files.cnblogs.com/hualei/Newtonsoft.Json.Net20.rar 在.net 2.0中提 ...
- 提取多层嵌套Json数据
在.net 2.0中提取这样的json {"name":"lily","age":23,"addr":{"ci ...
- 多层嵌套的json数据
很多时候我们见到的json数据都是多层嵌套的,就像下面这般: {"name":"桔子桑", "sex":"男", , & ...
随机推荐
- maven系列:基本命令(创建类、构建打包类、IDEA中操作)
目录 一.创建类命令 创建普通Maven项目 创建Web Maven项目 发布第三方Jar到本地库中 二.构建打包类命令 编译源代码 编译测试代码 编译测试代码 打包项目 清除打包的项目 清除历史打包 ...
- XV6中的锁:MIT6.s081/6.828 lectrue10:Locking 以及 Lab8 locks Part1 心得
这节课程的内容是锁(本节只讨论最基础的锁).其实锁本身就是一个很简单的概念,这里的简单包括 3 点: 概念简单,和实际生活中的锁可以类比,不像学习虚拟内存时,现实世界中几乎没有可以类比的对象,所以即使 ...
- 【项目源码】JavaWeb网上购书系统
JavaWeb网上购书系统 介绍 采用JSP.Servlet.MySQL.Tomcat8.0开发的网上购书系统. 软件架构 网上书城主要功能如下: (1) 前台(客户购买)部分: ① 用户管理:注册会 ...
- 开源.NetCore通用工具库Xmtool使用连载 - 图形验证码篇
[Github源码] <上一篇> 介绍了Xmtool工具库中的Web操作类库,今天我们继续为大家介绍其中的图形验证码类库. 图形验证码是为了抵御恶意攻击出现的一种设计:例如用户登录.修改密 ...
- LeetCode--1039
Smiling & Weeping ----我总是躲在梦与季节的身处, 听花与黑夜唱尽梦魇, 唱尽繁华,唱断所有记忆的来路. 题目链接:1039. 多边形三角剖分的最低得分 - 力扣(Leet ...
- 如何把网页打包成苹果原生APP并上架TF(TestFlight)
打包网页APP并上架到TestFlight流程 需要准备的材料: 1. GDB苹果网页打包软件1.6.0或者以上版本: https://www.cnblogs.com/reachteam/p/1229 ...
- Windows上Dart安装
过程 *1 去github上下载一个release包或者直接将flutter通过git clone下来 *2 将下载下来的flutter/bin添加到path中 *3 此时运行flutter或者flu ...
- 在线问诊 Python、FastAPI、Neo4j — 问题咨询
目录 查出节点 拼接节点属性 测试结果 问答演示 通过节点关系,找出对应的节点,获取节点属性值,并拼接成想要的结果. 接上节生成的CQL # 输入 question_class = {'args': ...
- 题解 hdu 1269 迷宫城堡
找点图论练习题写,发现hdu又寄了,那就发到blog里吧. 思路:tarjan缩点判断DAG中点数是否为1.若是,则该图为强连通图. //produced by miya555 //stupid mi ...
- 手撕Vue-界面驱动数据更新
经过上一篇文章,已经将数据驱动界面改变的过程实现了,本章节将实现界面驱动数据更新的过程. 界面驱动数据更新的过程,主要是通过 v-model 指令实现的, 只有 v-model 指令才能实现界面驱动数 ...