【论文阅读】Learning Deep Features for Discriminative Localization
这个是周博磊16年的文章。文章通过实验证明,即使没有位置标注,CNN仍是可以得到一些位置信息,(文章中的显著性图)
CNN提取的feature含有位置信息,尽管我们在训练的时候并没有标记位置信息;
这些位置信息,可以转移到其他的认知任务当中
文章的实验主要就是证明了,在CNN分类中,不同区域对于最终结果的影响大小是不同的,包含分类信息的部分是可以被定为得到的。(粗略的)
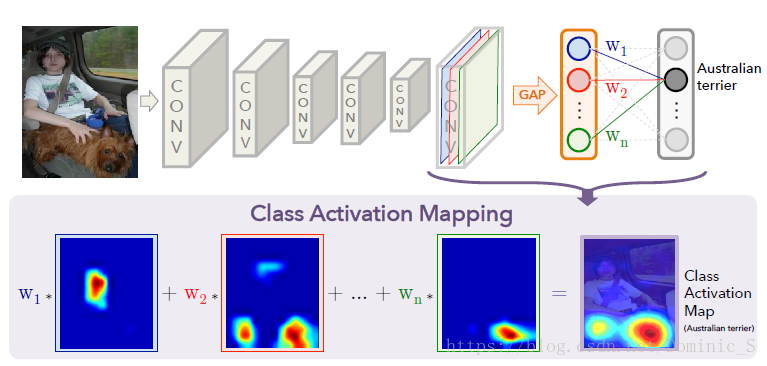
Class Activation Mapping
在传统的CNN分类任务中,最后的通常为全连接层,而FC全连接层是无法得到显著性图的。在论文中使用了GAP(global average pooling)来代替FC。
假设 \(f_{k}(x,y)\) 表示第 \(k\) 个特征图上 \((x,y)\) 位置的值,通过GAP,可以得到结果 \(F_k = \sum_{x,y}{f_k(x,y)}\) 。 那么对于某个类别 \(c\) ,softmax的输入值为
\]
最后类别\(c\)的值为
\]
怎么通过GAP,来生成CAM
通过上面的公式,我们可以将 \(s_{c}\) 展开,如下所示:
\]
定义属于某个类别c的CAM为
\]
从上式可以看出,\(M_{c}(x,y)\) 表示的是不同的激活unit(特征图)对识别某个类别c的权重和。具体如下图所示。 最后将生成的 \(M_{c}(x,y)\) 放大到原图的大小,就可以得到对应于某个类别c的CAM了。
最后,把 \(M_{c}(x,y)\) Upsample到指定大小即可
【论文阅读】Learning Deep Features for Discriminative Localization的更多相关文章
- 【Discriminative Localization】Learning Deep Features for Discriminative Localization 论文解析(转)
文章翻译: 翻译 以下文章来源: 链接
- [人脸活体检测] 论文: Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision
Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision 论文简介 与人脸生理相关的rppG信号被研究者 ...
- 【论文阅读】Deep Clustering for Unsupervised Learning of Visual Features
文章:Deep Clustering for Unsupervised Learning of Visual Features 作者:Mathilde Caron, Piotr Bojanowski, ...
- 【论文阅读】Deep Mutual Learning
文章:Deep Mutual Learning 出自CVPR2017(18年最佳学生论文) 文章链接:https://arxiv.org/abs/1706.00384 代码链接:https://git ...
- 【CV论文阅读】Deep Linear Discriminative Analysis, ICLR, 2016
DeepLDA 并不是把LDA模型整合到了Deep Network,而是利用LDA来指导模型的训练.从实验结果来看,使用DeepLDA模型最后投影的特征也是很discriminative 的,但是很遗 ...
- 论文阅读:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning 2018-11-14 13:30:36 Paper: https://arxiv.org/abs/ ...
- 【论文阅读】Deep Mixture of Diverse Experts for Large-Scale Visual Recognition
导读: 本文为论文<Deep Mixture of Diverse Experts for Large-Scale Visual Recognition>的阅读总结.目的是做大规模图像分类 ...
- 【论文阅读】Deep Adversarial Subspace Clustering
导读: 本文为CVPR2018论文<Deep Adversarial Subspace Clustering>的阅读总结.目的是做聚类,方法是DASC=DSC(Deep Subspace ...
- 论文阅读 DynGEM: Deep Embedding Method for Dynamic Graphs
2 DynGEM: Deep Embedding Method for Dynamic Graphs link:https://arxiv.org/abs/1805.11273v1 Abstract ...
- 三维目标检测论文阅读:Deep Continuous Fusion for Multi-Sensor 3D Object Detection
题目:Deep Continuous Fusion for Multi-Sensor 3D Object Detection 来自:Uber: Ming Liang Note: 没有代码,主要看思想吧 ...
随机推荐
- 团队如何选择合适的Git分支策略?
现代软件开发过程中要实现高效的团队协作,需要使用代码分支管理工具实现代码的共享.追溯.回滚及维护等功能.目前流行的代码管理工具,包括CVS,SVN,Git,Mercurial等. 相比CVS和SVN的 ...
- Plot函数用法详解——R语言
plot是R中的基本画图工具,直接plot(x),x为一个数据集,就能画出图,soeasy!但是细节往往制胜的关键,所以就详细来看看plot的所有可设置参数及参数设置方法.R语言的基础绘图系统主要由基 ...
- 用 Go 剑指 Offer 21. 调整数组顺序使奇数位于偶数前面
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数在数组的前半部分,所有偶数在数组的后半部分. 示例: 输入:nums = [1,2,3,4]输出:[1,3,2,4] 注:[3,1, ...
- C# System.ObjectDisposedException: Cannot access a disposed object, A common cause of thiserror is disposing a context that was resolved from dependency injection and then later trying touse...
项目中使用了依赖注入,这个错误在我项目中的原因:在async修饰的异步方法中,调用执行数据库操作的方法时,没有使用await关键字调用,因为没有等待该调用,所以在调用完成之前将继续执行该方法.因此,已 ...
- 用CMD或者bat修改host文件
第一行代码标识 取消host的只读属性 第二行写入 attrib -R C:\WINDOWS\system32\drivers\etc\hosts @echo 127.0.0.1 baidu.com ...
- Redis的缓存穿透+解决方案
1.缓存穿透现象介绍 缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库. 常见的解决方案有两种: 缓存空对象 优点:实现简单,维护方便 ...
- es6的Symbol数据类型
ES6引入了一种新的原始数据类型Symbol,表示独一无二的值.它是JavaScript语言的第七种数据类型,前六种是:Undefined.Null.布尔值(Boolean).字符串(String). ...
- 突破tls/ja3新轮子
我之前的文章介绍了SSL指纹识别 https://mp.weixin.qq.com/s/BvotXrFXwYvGWpqHKoj3uQ 很多人来问我BYPass的方法 主流的BYPASS方法有两大类: ...
- 前端模拟“多线程”提交Http请求
首先说,javascript没有多线程这样一个说法,我说的只是类似那种效果.其次,不建议使用这种方式解决问题,多线程应该交给后台去做. 但是,如果非要这样用,有什么方法呢? 我在工作中就遇到了这样的问 ...
- vue中点击其他任意位置关闭弹框
mounted() { //点击任意位置关闭区域弹窗 document.addEventListener('click', (e) => { //获取弹窗对象 const userCon = d ...