【爬虫案例】用Python爬大麦网任意城市的近期演出活动!
一、爬取目标
大家好,我是@马哥python说 ,一枚10年程序猿。
今天分享一期python爬虫案例,爬取目标是大麦网近期演出活动:- 大麦搜索
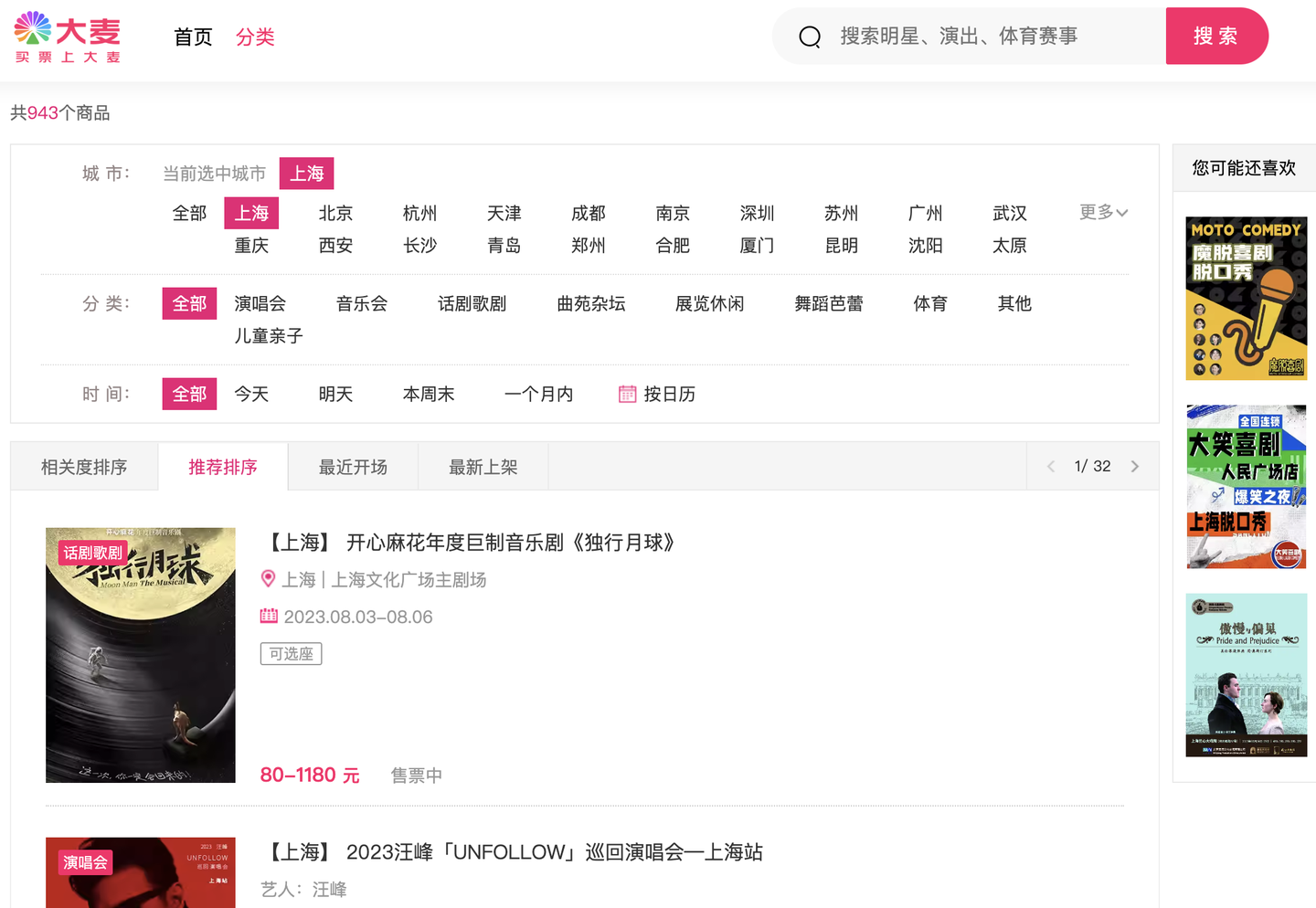
二、展示爬取结果
爬取结果截图:
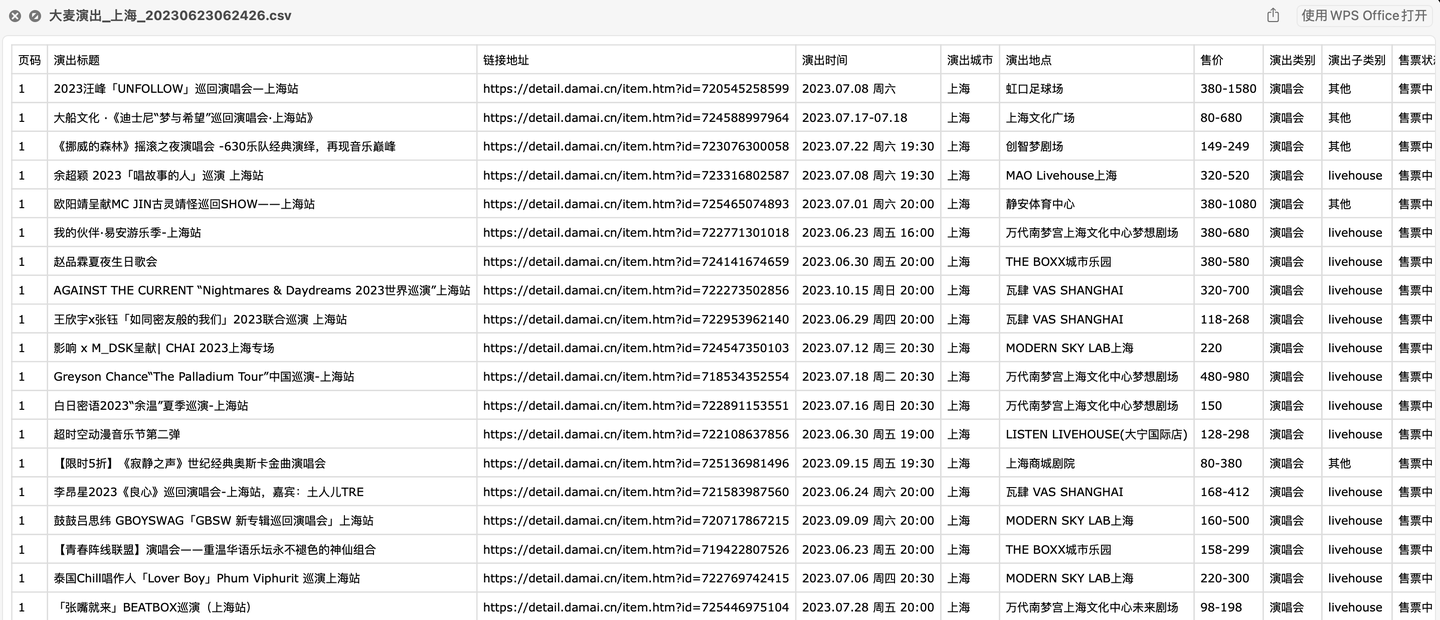
含10个字段:
页码,演出标题,链接地址,演出时间,演出城市,演出地点,售价,演出类别,演出子类别,售票状态。
演示视频:【Python爬虫演示】爬取大麦网任意城市的近期演出!
以上。
三、讲解代码
首先,导入需要用到的库:
import pandas as pd
import requests
import os
import datetime
from time import sleep
import random
定义一个请求头:
# 设置请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299',
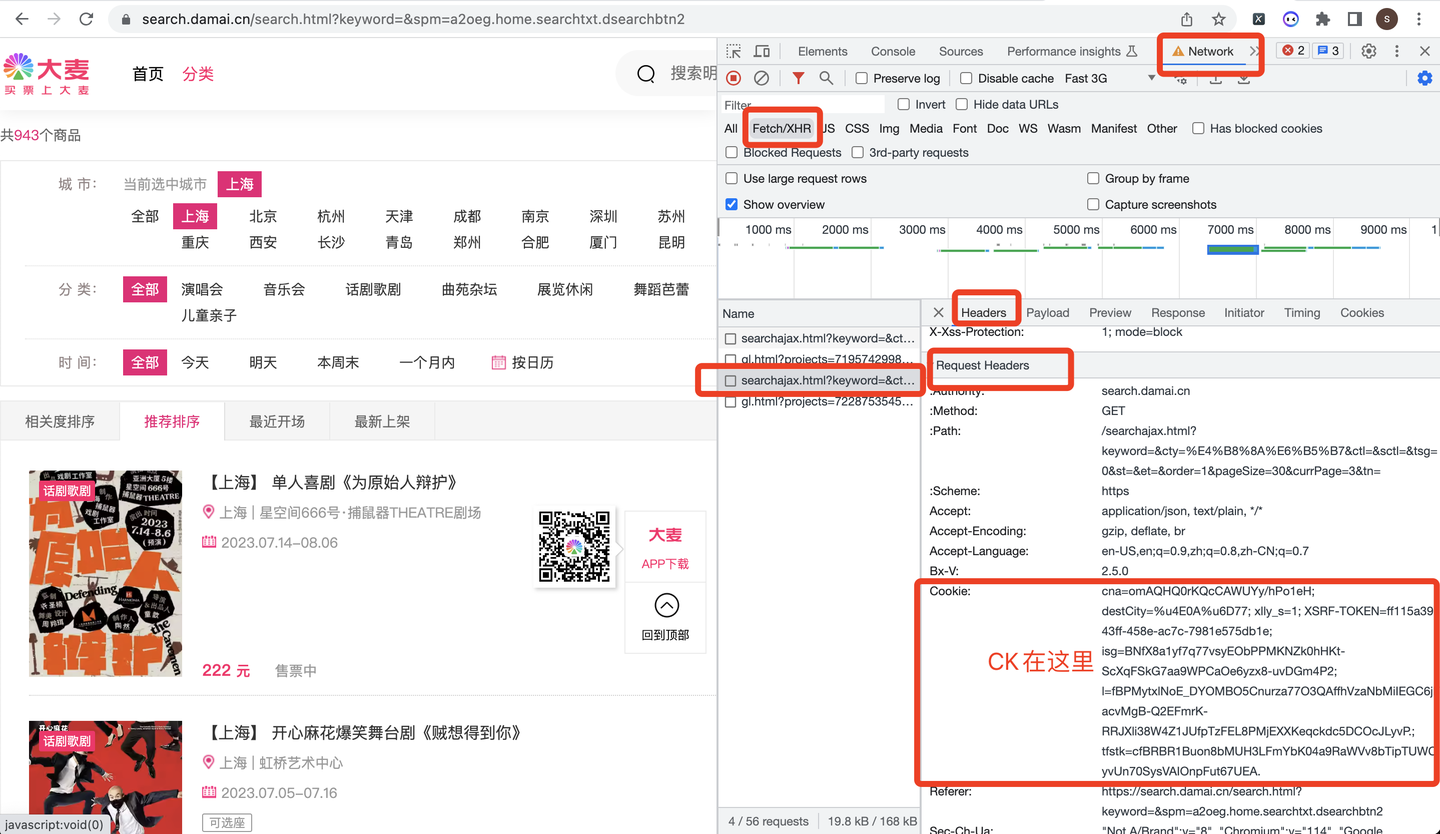
'Cookie': '换成自己的cookie',
'X-Xsrf-Token': '7d065ac9-b924-4c14-869a-ab599b571244',
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,zh;q=0.8,zh-CN;q=0.7',
'Bx-V': '2.5.0',
'Referer': 'https://search.damai.cn/search.htm?spm=a2oeg.home.category.ditem_0.591b23e1HxE6Vj&ctl=%E6%BC%94%E5%94%B1%E4%BC%9A&order=1&cty=%E6%88%90%E9%83%BD',
'Sec-Ch-Ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': "macOS",
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
}
其中,cookie的获取方式如下:
定义请求地址url:
# 请求地址
url = 'https://search.damai.cn/searchajax.html'
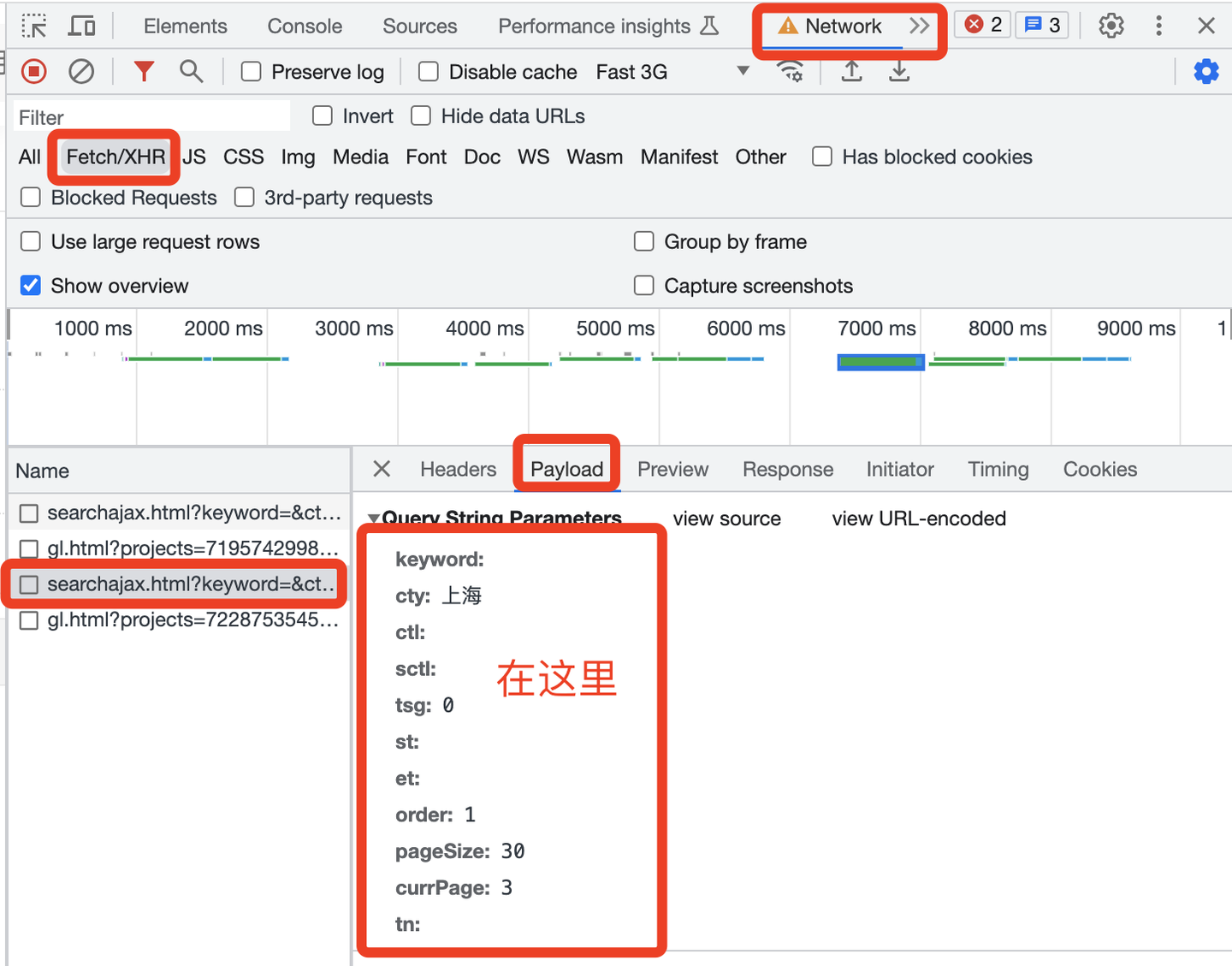
定义请求参数params,从PayLoad中获取:
发送请求,并且用json格式解析数据:
# 发送请求
r = requests.get(url, headers=headers, params=params)
# 解析数据
json_data = r.json()
以"演出标题"字段为例:
for data in json_data['pageData']['resultData']:
# 演出标题
title = data['nameNoHtml']
title_list.append(title)
print('演出标题:', title)
其他字段同理,不再赘述。
最后是保存到csv文件:
df = pd.DataFrame(
{
'页码': page,
'演出标题': title_list,
'链接地址': href_list,
'演出时间': time_list,
'演出城市': city_list,
'演出地点': loc_list,
'售价': price_list,
'演出类别': category_list,
'演出子类别': subcategory_list,
'售票状态': status_list,
}
)
# 保存到csv文件
df.to_csv(result_file, encoding='utf_8_sig', mode='a+', index=False, header=header)
其中,encoding参数设置为utf_8_sig,目的是防止csv文件产生乱码,不便读取。
整个代码中,还含有:设置sleep随机等待、判断循环停止条件、防止多次写入表头、用户input输入过滤条件、往csv文件名添加时间戳等功能,篇幅有限,详细请见原始代码。
四、同步视频
代码演示视频:
【Python爬虫演示】爬取大麦网任意城市的近期演出!
五、附完整源码
完整源码获取:【爬虫案例】用Python爬大麦网任意城市演出活动
我是@马哥python说 ,持续分享python源码干货中!
【爬虫案例】用Python爬大麦网任意城市的近期演出活动!的更多相关文章
- 我不就是吃点肉,应该没事吧——爬取一座城市里的烤肉店数据(附完整Python爬虫代码)
写在前面的一点屁话: 对于肉食主义者,吃肉简直幸福感爆棚!特别是烤肉,看着一块块肉慢慢变熟,听着烤盘上"滋滋"的声响,这种期待感是任何其他食物都无法带来的.如果说甜点是" ...
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python 网络爬虫(一)爬取天涯论坛评论
我是一个大二的学生,也是刚接触python,接触了爬虫感觉爬虫很有趣就爬了爬天涯论坛,中途碰到了很多问题,就想把这些问题分享出来, 都是些简单的问题,希望大佬们以宽容的眼光来看一个小菜鸟
- python爬虫+词云图,爬取网易云音乐评论
又到了清明时节,用python爬取了网易云音乐<清明雨上>的评论,统计词频和绘制词云图,记录过程中遇到一些问题 爬取网易云音乐的评论 一开始是按照常规思路,分析网页ajax的传参情况.看到 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
随机推荐
- Windows系统使用ODBC驱动访问KingaseES数据库及常见问题解决
Windows系统使用KingbaseES ODBC驱动访问KingaseES数据库及常见问题解决. 一.获取KingbaseES数据库ODBC驱动: 在官网下载KingbaseES数据库安装包,选择 ...
- Java面试题【4】
28)Java 栈和堆的区别 1 栈:为编译器自动分配和释放,如函数参数.局部变量.临时变量等等 2 堆:为成员分配和释放,由程序员自己申请.自己释放.否则发生内存泄露.典型为使用new申请的堆内容. ...
- Python字典遍历
1 def dict_test(): 2 #初始化字典 3 dict= {"a1":"1","a2":"2"," ...
- 基于文件语义实现S3接口语义的注意事项
本文标题中提到的文件语义,指的是POSIX规范. S3指的是AWS提供的对象存储服务以及相关接口.为方便描述,下文中以对象语义替代S3接口语义. 文件语义和对象语义存在比较多的差异. 对象语义不支持文 ...
- 4天带你上手HarmonyOS ArkUI开发——《HarmonyOS ArkUI入门训练营之健康生活实战》
<HarmonyOS ArkUI入门训练营之健康饮食应用>是面向入门开发者打造的实战课程系列.特邀华为终端BG高级开发工程师作为本次训练营讲师,以健康饮食为例,开展技术教学及实战案例分享 ...
- HarmonyOS多媒体框架介绍
原文:https://mp.weixin.qq.com/s/_2LHv7s7X4IJMCPU8hcCeg,点击链接查看更多技术内容. 随着科技进步,我们的生活发生了翻天覆地的变化.过去几年音视频技 ...
- xml转voc数据集(含分享数据集)
数据集的链接:行人检测数据集voc数据集(100张) 原始图片和.xml数据目录结构如下: . └── data ├── 003002_0.jpg ├── 003002_0.xml ├── 00300 ...
- python3中os.renames()和os.rename()区别
renames源码:def renames(old, new): head, tail = path.split(new) # 作用是分割为两部分,head为路径,tail为文件名: if head ...
- Django3.0连接数据库注意点
需先在应用下的__Init__.py文件中配置 import pymysqlpymysql.version_info=(1, 3, 13, 'final', 0) # 3.0时需要pymysql.in ...
- flask售后评分系统
做软件行业的公司,一般都有专业的售前售后团队,还有客服团队,客服处理用户反馈的问题,会形成工单,然后工单会有一大堆工单流程,涉及工单的内部人员,可能会有赔付啥的,当然,这是有专业的售前.售后.客服团队 ...