基于DAYU的实时作业开发,分分钟搭建企业个性化推荐平台
摘要:搭建这个平台最费时耗力的事莫过于对批、流作业的编排,作业组织管理以及任务调度了。但是这一切,用DAYU的数据开发功能几个任务可通通搞定。
大多数电商类企业都会搭建自己的个性化推荐系统,利用自己拥有的用户数据、商品数据、用户行为数据以及各种维度计算得来的标签画像计算用户偏好,推荐最佳商品给用户,最大化地促进交易。
一个典型的推荐系统包括批处理计算、实时处理层、推荐应用3部分,是典型的Lamda架构。
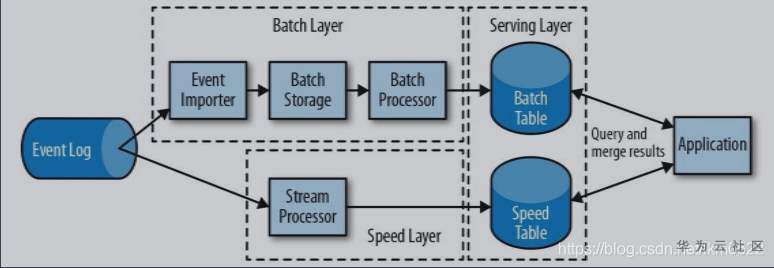
搭建这个平台最费时耗力的事莫过于对批、流作业的编排,作业组织管理以及任务调度了。但是这一切,用DAYU的数据开发功能几个任务可通通搞定。当然,你可能会说,不是有专门的个性化推荐云服务吗,直接用它不香吗?这里我们不比赛举杠铃,如果企业还不具备利用各种推荐算法的能力,那直接花点钱买推荐服务是最佳选择;但是你如果想最大化地、持续地优化推荐算法的效果,框架还是自己搭比较靠谱。这里给一个例子,展示如何利用DAYU快速完成一个简单的推荐系统。除了DAYU的数据开发,还需要搭配华为云的DLI、DIS、MRS-HBase。
首先介绍下DAYU开发的两种作业类型:
- 批作业
批作业只能被调度触发,任务执行一段时间必须结束,换句话说就是任务不能无限时间持续运行。作业是多个算子(一个也可以)组成的Pipeline,Pipeline作为一个整体被调度。 - 实时作业
实时作业这个名字其实不准确,实际上它可以是一个流、批混合的作业,也可以是个纯实时流处理作业,也可以是个单纯的批作业。作业是由多个算子组成的Pipeline,相对批作业,实时作业中每个算子可单独被配置调度策略,而且算子启动的任务可以永不下线,这样就可以调度那些always online的Flink、SparkStreaming流处理作业。在实时作业里,带箭头的连线仅代表业务上的关系,而非任务执行流程,更不是数据流。
这个推荐系统的后台就使用实时作业来实现,一个流、批混合的作业,直接给个全景图:
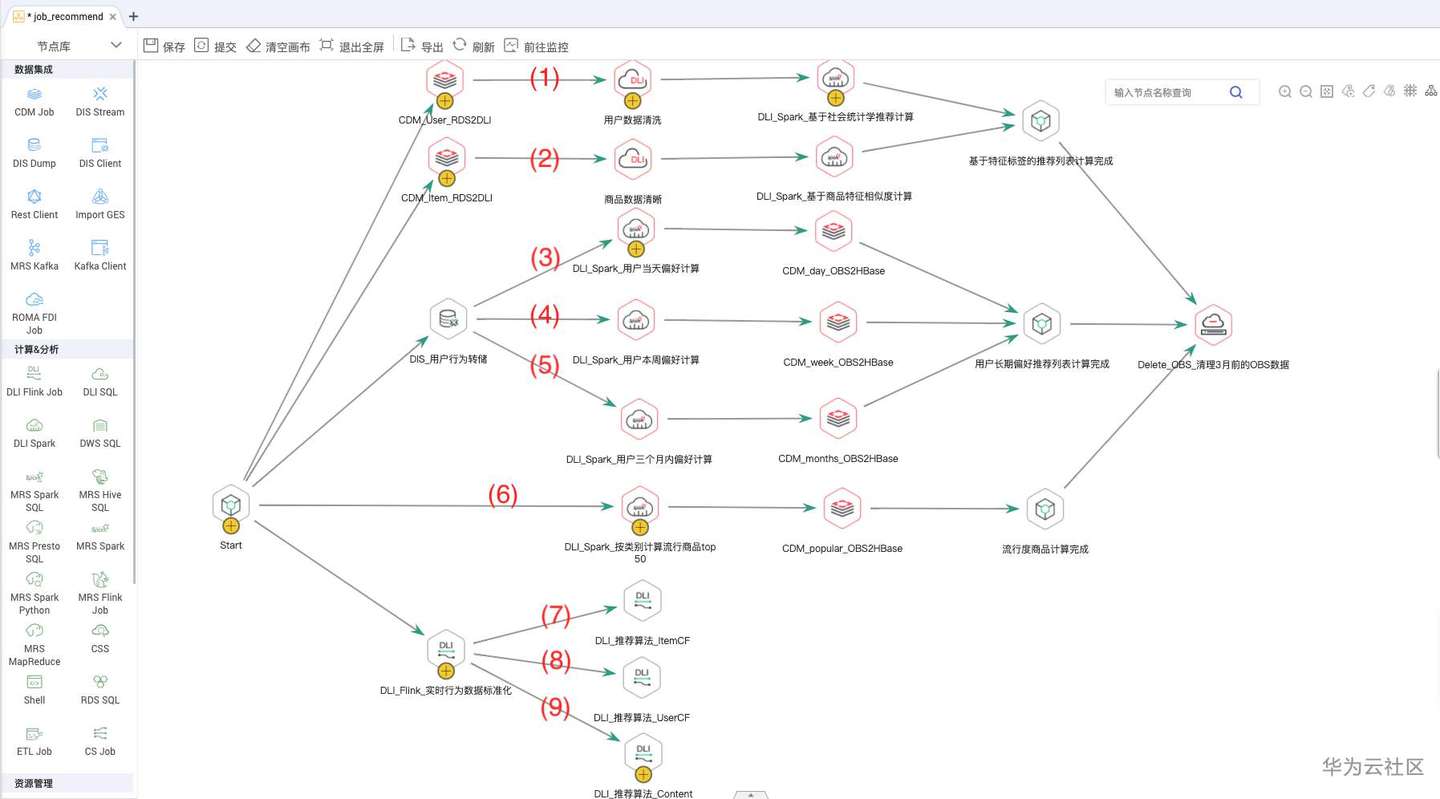
这里涵盖了一个简单推荐系统的主要计算流程。更多算法的任务流程这里没有完全展示出来,例如基于模型的算法、基于深入学习的推荐算法,也不包含各种推荐指标的计算过程,有兴趣的同学可以百度学习。
整个任务中包括9组数据处理流程,6个批作业流程,3个实时作业:
批处理流程
从上到下,依次计算:
1)基于个用户特征、标签计算推荐列表
周期:每天一次
计算:每天通过CDM从RDS抽取用户数据到DLI,基于每个用户的基本信息,年龄、性别、职业、收入、地域等等各种属性信息,以及来自360度画像系统的标签信息,生成推荐列表,保存到HBase中。
2)基于商品的相似性特征,计算推荐列表
周期:每天一次
计算:每天通过CDM从RDS抽取新增商品信息到DLI,然后计算出来的基于商品相似特征的推荐列表,存入HBase中。
3)计算当天用户的偏好,生成日推荐列表
周期:每天一次
计算:通过DIS dump转储任务,把网站实时搜集的用户行为信息转储到OBS中,通过一批Spark算法(批量的用户协同、商品协同、基于内容相似性、LR等算法),基于一天的行为数据计算推荐列表。然后把列表推到HBase中。
4)计算本周用户的偏好,生成周推荐列表
周期:每天一次
计算:计算行为同上,区别是基于一周的行为数据计算推荐列表。
5)计算3个月内的偏好,生成长期偏好推荐列表
周期:每天一次
计算:计算行为同上,区别是基于3个月的行为数据计算推荐列表。
6)计算流行产品的列表
周期:每天或者数小时
计算:通过用户总体商品的点击、搜索、评分等行为,基于OBS上用户的行为数据,按类别计算热门商品Top50。这个列表也可作为补齐列表,当其他推荐列表还不足以填满网站的推荐位,可以用这个列表补齐。
实时流处理流程
1)实时计算用户偏好--Item-Based协同算法
计算:通过Flink任务对DIS用户行为通道的数据进行消费,先把用户行为日志转换为标准行为(Time,userid,ItemID,Score),再通过流式Item-Based协同算法计算推荐列表,更新到HBase中。
2)实时计算用户偏好--User-Based协同算法
计算:同上,区别是使用流式User-Based协同算法计算推荐列表,更新到HBase中。
3)实时计算用户偏好--Content-Based算法
计算:同上,区别是使用流式Content-Based协同算法计算推荐列表,更新到HBase中。
以上一顿操作,在HBase中会有一堆以UserID、Item为Key的推荐列表,形如:
用户推荐列表结果:
userid_001:item100, item899, item 433, item 666,....
userid_002:item220, item334, item 720 item 666,....
userid_003:item728, item899, item 333, item 632,....
根据用户实时行为、历史行为不同周期,有若干组不同的推荐列表。
基于商品的推荐列表结果:
Item_0001: Item1000,Item333,time5213,...
Item_0002: Item1000,Item333,time5213,...
Item_0003: Item1000,Item333,time5213,...
另外,推荐系统平台还需要一个提供rest接口的服务,供web网站推荐位调用。当用户打开网页时,自动向该服务请求当前用户的推荐列表,服务访问HBase,获取前面作业计算出来的多个推荐列表,并按一定策略组合成一个推荐列表返回给网页,就此,完成了一个端到端的推荐业务流程。
一个完整的推荐系统要更复杂一些,这里并没有讨论推荐系统的专题内容。从例子可以看出DAYU具备强大的编排和调度能力,单单一个任务就可以涵盖非常复杂的场景。实时上,大型的推荐系统平台还是需要针对性的定制,因为涉及到一些管理上的流程需要应对、闭环。不过基于华为云体系下各种平台、应用,有了DAYU这个助手,数据相关的方方面面的事务处理,将变得既简洁又高效。
本文分享自华为云社区《基于DAYU的实时作业开发,分分钟搭建企业个性化推荐平台》,原文作者:Loading... 。
基于DAYU的实时作业开发,分分钟搭建企业个性化推荐平台的更多相关文章
- Scala开发环境搭建与资源推荐
Scala开发环境搭建与资源推荐 本文介绍了Scala的开发环境,包括SDK.IDE的设置.常用资源列表等.Scala是一门静态语言,很有可能就是Java的继承者. AD: 2014WOT全球软件技术 ...
- (转)微信公众平台开发之基于百度 BAE3.0 的开发环境搭建(采用 Baidu Eclipse)
原文传送门(http://blog.csdn.net/bingtianxuelong/article/details/17843111) 版本说明: V1: 2014-2-13 ...
- 基于kubuntu的C/C++开发环境搭建
基于kubuntu的环境搭建 系统: kubuntu 14.04 中文输入法: SICM ibus fcitx:sougou 中文输入法的安装比较复杂,由于各种的不兼容,可能会出现各种的问题: 终端配 ...
- ios即时通讯客户端开发之-mac上基于XMPP的聊天客户端开发环境搭建
1.搭建服务器 - 安装顺序 - (mysql->openfire->spark) 数据库:mysql 服务器管理工具: openfire 测试工具: spark mysql 安装 h ...
- Windows下基于ADS+J-Link 的ARM开发环境搭建
在一般ARM编程教学和实验环境里,一般采用 ADS加+并口转Jtag板+H-Jtag的开发环境.但是这种方法最大缺点是需要机器上有一个并口.现在无论PC还是笔记本都很难有并口,因此采用USB接口调试器 ...
- Windows下基于eclipse的Spark应用开发环境搭建
原创文章,转载请注明: 转载自www.cnblogs.com/tovin/p/3822985.html 一.软件下载 maven下载安装 :http://10.100.209.243/share/so ...
- 微信公众平台开发之基于百度 BAE3.0 的开发环境搭建(MyEclipse + SVN)
等待加载完成后,在"Personal Sites" 栏目中会显示你加载的SVN的相关内容,展开"SVN"分别选择"Core SVNKit Librar ...
- 微信公众平台开发之基于百度 BAE3.0 的开发环境搭建(采用 Baidu Eclipse)
3.通过 SVN 检入工程 在 bae 上的应用添加部署成功后,如图 7 点击“点击查看”按钮,会打开一个新页面,页面上会打印 “hello world” ,这是因为我们的应用包含有示 ...
- 基于vue的实时视频流开发
背景:多个实时视频的介入 技术:hls.js的流媒体,支持格式已m3u8为主 解决了什么:多个实时视频长时间播放会有卡顿的情况 具体代码实现: import Hls from 'hls.js' pla ...
- 基于全志H3芯片的ARM开发环境搭建
基于全志H3芯片的ARM开发环境搭建 最近买了个友善之臂的NanoPi M1板子,又在网上申请了个NanoPi NEO板子,这两个都是基于全志H3芯片的Crotex-A7四核ARM开发板,两个板子可以 ...
随机推荐
- 利用信号量SemaphoreSlim实现PaddleOCR的线程安全访问
Wlkr.Core.ThreadUtils 项目背景 早在PaddleOCR 2.2版本时期,认识了周杰大佬的PaddleSharp项目,试用其中PaddleOCR时,发现它在改为web api调用时 ...
- Speex详解(2019年09月25日更新)
Speex详解 整理者:赤勇玄心行天道 QQ号:280604597 微信号:qq280604597 QQ群:511046632 博客:www.cnblogs.com/gaoyaguo 大家有什么不明白 ...
- 使用aop(肉夹馍)为BlazorServer实现统一异常处理
背景 用户做一个操作往往对应一个方法的执行,而方法内部会调用别的方法,内部可能又会调用别的方法,从而形成一个调用链.我们一般是在最顶层的方法去加try,而不是调用链的每一层都去加try. 在web开发 ...
- Hyper-V 下的 Debian 双网卡配置
Debian 双网卡配置 因为 Hyper-v 不能在 Hyper-v Manger 里设置网卡的静态 IP, 而每次开机自启之后又要连接 Debian 虚拟机,所以使用了双网卡. 双网卡分为内网网卡 ...
- vue打包部署遇到的问题
网站上线中遇到的问题(跨域,404,空白页解决方案) 因为本人是后端开发工程师,对前端开发不了解,踩了很多坑,所以将踩过的坑分享出来,以供参考 网站地址:这里 这段时间将项目部署到服务器中引发了几个问 ...
- redis主从同步及redis哨兵机制
1.主从和哨兵的作用: 角色 作用 主从 1.(提供)数据副本:多一份数据副本,保证redis高可用 2. 扩展(读)性能:如容量.QPS等 哨兵 1.监控: 监控redis主库及从库运行状态: 2 ...
- P5404 [CTS2019] 重复 题解
题目链接 观察题目,我们发现直接计算是困难的,先构造单个合法的 \(T\) 分析其性质. 为了构造出 \(T\),先考虑构造时 \(T\) 时什么时候会出现不合法的情况,此时 \(T\) 会有一段和 ...
- OpenCL任务调度基础介绍
当前,科学计算需求急剧增加,基于CPU-GPU异构系统的异构计算在科学计算领域得到了广泛应用,OpenCL由于其跨平台特性在异构计算领域渐为流行,其调度困难的问题也随之暴露,传统的OpenCL任务调度 ...
- [Flink] Flink(CDC/SQL)Job在启动时,报“ConnectException: Error reading MySQL variables: Access denied for user 'xxxx '@'xxxx' (using password: YES)”(1个空格引发的"乌龙")
1 问题描述 1.1 基本信息 所属环境:CN-PT 问题时间:2023-11-21 所属程序: Flink Job(XXXPT_dimDeviceLogEventRi) 作业类型: Flink SQ ...
- Calendar日历类型常见方法(必看!!)
Hi i,m JinXiang 前言 本篇文章主要介绍Calendar日历类型的几种常见方法以及部分理论知识 欢迎点赞 收藏 留言评论 私信必回哟 博主收将持续更新学习记录获,友友们有任何问题可以在 ...