地图区域大数据量 marker 坐标点高效抽稀算法
按网上的思路一般要写双层循环,第一层循环遍历点集合,时间复杂度为O(N),第二层循环遍历结果集,逐一计算距离,距离小于阈值的不加入结果集,距离大于阈值的加入结果集,时间复杂度为O(M),双层循环总时间复杂度为O(N * M)。
新的算法思路:坐标点的经纬度经过计算得到的结果作为HashMap的Key,坐标相近的点的Key相同,利用HashMap降低时间复杂度,不需要第二层循环遍历,把时间复杂度由O(N * M)降为O(N)。
该算法的优点:1、抽稀后坐标点位置均匀,2、计算效率高(时间复杂度:O(N)),3、算法逻辑简单,4、计算结果幂等(结果集确定,多次重复计算结果集相同)。
代码:


//抽稀
if (mapZoom >= 15 && mapZoom <= 16) {
currentMarkerMap = new HashMap(); var getKey = function (lng, lat, len, ratio) { //如果计算结果数量较少,就调大ratio
var a = (10000 + lng * ratio).toString().substr(0, len);
var b = (10000 + lat * ratio).toString().substr(0, len)
return a + "," + b;
}; for (var i = 0; i < forAdd.length; i++) {
var marker = forAdd[i]; var key;
if (mapZoom == 15) key = getKey(marker.geometry.x, marker.geometry.y, 9, 1);
if (mapZoom == 16) key = getKey(marker.geometry.x, marker.geometry.y, 10, 1); if (!currentMarkerMap.containsKey(key)) {
currentMarkerMap.put(key, marker);
}
}
}
说明:代码中 forAdd 变量是抽稀前的坐标点集合,currentMarkerMap 变量是HashMap集合(HashMap是自己实现的JS类),定义代码如下:
var forClear = [];
var currentMarkerMap = new HashMap();
效果图:
缩小:
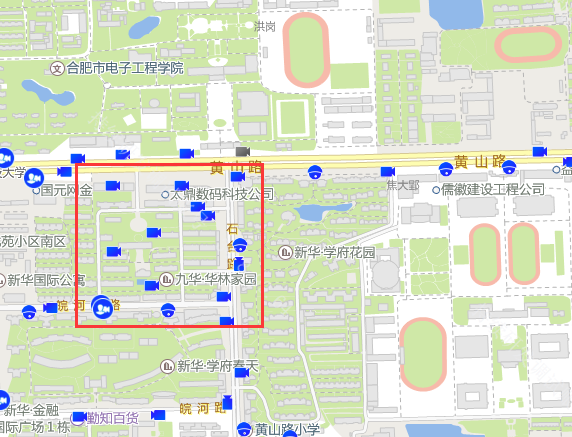
放大:

动态效果:

新算法:
说明:上面的代码用的是SuperMap iClient Classic 8C,下面用的是Leaflet
function refreshVillageMarkers(map, deviceLayer) {
//获取地图层级
let mapZoom = map.getZoom();
//点位完全显示层级
let visibleZoom = mapType == 1 ? 17 : 17; //1:使用SuperMap地图 2:使用高德地图
//获取地图可视区域
let polygon = getMapBounds(map);
//获取小区点位集合
let villageMarkerArr = getVillageMarkerArr();
//筛选出可视区域内的点位
let visibleMarkerArr = [];
for (let marker of villageMarkerArr) {
if (!marker.options.rnd) {
marker.options.rnd = Math.random();
}
let latLng = marker.getLatLng();
let point = turf.point([latLng.lng, latLng.lat]);
if (turf.booleanPointInPolygon(point, polygon)) {
visibleMarkerArr.push(marker);
}
}
//可视区域内的点位抽稀
let forAdd = [];
let visibleCount = 300;
let ratio = 1;
if (visibleMarkerArr.length > visibleCount) {
ratio = visibleCount / visibleMarkerArr.length;
}
for (let marker of visibleMarkerArr) {
if (mapZoom >= visibleZoom || marker.options.rnd < ratio) {
forAdd.push(marker);
}
}
//移除可视区域外的和被抽稀掉的点位
for (let marker of currentMarkerMap.values()) {
let latLng = marker.getLatLng();
let point = turf.point([latLng.lng, latLng.lat]);
if (!turf.booleanPointInPolygon(point, polygon) || (mapZoom < visibleZoom && marker.options.rnd >= ratio)) {
deviceLayer.removeLayer(marker);
currentMarkerMap.delete(marker.options.id);
}
}
//可视区域内的点位添加到图层上
for (let marker of forAdd) {
deviceLayer.addLayer(marker);
if (!currentMarkerMap.has(marker.options.id)) {
currentMarkerMap.set(marker.options.id, marker);
}
}
//打印
console.info('实际显示点位数/可视区点位数(' + (currentMarkerMap.size == visibleMarkerArr.length ? '相等' : '不相等') + '):' + currentMarkerMap.size + '/' + visibleMarkerArr.length)
}
//获取地图可视区域
function getMapBounds(map) {
let nw = map.getBounds().getNorthWest();
let ne = map.getBounds().getNorthEast();
let se = map.getBounds().getSouthEast();
let sw = map.getBounds().getSouthWest();
let polygon = turf.polygon([[
[nw.lng, nw.lat],
[ne.lng, ne.lat],
[se.lng, se.lat],
[sw.lng, sw.lat],
[nw.lng, nw.lat]
]]);
return polygon;
}
地图区域大数据量 marker 坐标点高效抽稀算法的更多相关文章
- PGIS大数据量点位显示方案
PGIS大数据量点位显示方案 问题描述 PGIS在地图上显示点位信息时,随点位数量的增加浏览器响应速度会逐渐变慢,当同时显示上千个点时浏览器会变得非常缓慢,以下是进行的测试: 测试环境: 服务器: C ...
- [WP8.1UI控件编程]Windows Phone大数据量网络图片列表的异步加载和内存优化
11.2.4 大数据量网络图片列表的异步加载和内存优化 虚拟化技术可以让Windows Phone上的大数据量列表不必担心会一次性加载所有的数据,保证了UI的流程性.对于虚拟化的技术,我们不仅仅只是依 ...
- php 大数据量及海量数据处理算法总结
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题.下面的一些问题基本直接来源于公司的面试笔试题目, ...
- java处理大数据量任务时的可用思路--未验证版,具体实现方法有待实践
1.Bloom filter适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集基本原理及要点:对于原理来说很简单,位数组+k个独立hash函数.将hash函数对应的值的位数组置1,查找时如 ...
- Export大数据量导出和打包
项目需求 导出生成大批量数据的文件,一个Excel中最多存有五十万条数据,查询多余五十万的数据写多个Excel中.导出完成是生成的多个Excel文件打包压缩成zip,而后更新导出记录中的压缩文件路 ...
- 大数据量冲击下Windows网卡异常分析定位
背景 mqtt的服务端ActiveMQ在windows上,多台PC机客户端不停地向MQ发送消息. 现象 观察MQ自己的日志data/activemq.log里显示,TCP链接皆异常断开.此时尝试从服务 ...
- POI3.8解决导出大数据量excel文件时内存溢出的问题
POI3.8的SXSSF包是XSSF的一个扩展版本,支持流处理,在生成大数据量的电子表格且堆空间有限时使用.SXSSF通过限制内存中可访问的记录行数来实现其低内存利用,当达到限定值时,新一行数据的加入 ...
- jquery.datatable.js与CI整合 异步加载(大数据量处理)
http://blog.csdn.net/kingsix7/article/details/38928685 1.CI 控制器添加方法 $this->show_fields_array=arra ...
- MySQL随机获取数据的方法,支持大数据量
最近做项目,需要做一个从mysql数据库中随机取几条数据出来. 总所周知,order by rand 会死人的..因为本人对大数据量方面的只是了解的很少,无解,去找百度老师..搜索结果千篇一律.特发到 ...
- 大数据量下,分页的解决办法,bubuko.com分享,快乐人生
大数据量,比如10万以上的数据,数据库在5G以上,单表5G以上等.大数据分页时需要考虑的问题更多. 比如信息表,单表数据100W以上. 分页如果在1秒以上,在页面上的体验将是很糟糕的. 优化思路: 1 ...
随机推荐
- freeswitch的一个性能问题
概述 freeswitch是一款简单好用的VOIP开源软交换平台. 在fs的使用过程中,会遇到各种各样的问题,各种问题中,性能问题是最头疼的. 最近在测试某些场景的时候,压测会造成fs的内存占用持续升 ...
- 微信小程序直播接入指南
微信小程序直播接入指南 小程序直播组件接入指引 一.简介 小程序直播,是微信提供给小程序开发者的直播组件.通过调用该组件,商家可以在小程序中实现直播功能. 按下面的使用说明接入,在你的小程序中引入直播 ...
- 【GIT】学习day02 | git环境搭建并将项目进行本地管理【外包杯】
进入终端 输入GitHub或者给gitee的用户名和邮箱地址 然后依次敲入一下信息 git commit -m "init project" git init git add . ...
- Unicode编码解码
一.Unicode概述 Unicode是一种字符编码标准,旨在解决不同字符集之间的兼容性问题.它为全球所有语言提供了一种统一的编码方式,使得各种字符能够在计算机系统中正确显示和处理.Unicode字符 ...
- SpringBoot事件机制
1.是什么? SpringBoot事件机制是指SpringBoot中的开发人员可以通过编写自定义事件来对应用程序进行事件处理.我们可以创建自己的事件类,并在应用程序中注册这些事件,当事件被触发时,可以 ...
- 一行代码修复100vh bug | 京东云技术团队
你知道奇怪的移动视口错误(也称为100vh bug)吗?或者如何以正确的方式创建全屏块? 一.100vh bug 什么是移动视口错误? 你是否曾经在网页上创建过全屏元素?只需添加一行 CSS 并不难: ...
- Asp.net core Webapi 项目如何优雅地使用内存缓存
前言 缓存是提升程序性能必不可少的方法,Asp.net core 支持多级缓存配置,主要有客户端缓存.服务器端缓存,内存缓存和分布式缓存等.其中客户端缓和服务器端缓存在使用上都有比较大的限制,而内存缓 ...
- vulnhub - tornado - wp
coverY: 0 tornado 信息收集 目标开放了80,22端口. 访问80网页,是默认页面: 目录枚举 用dirsearch没有什么发现,换gobuster发现了一个bluesky目录.访问如 ...
- Python——第二章:运算符
1. 算数运算 + - * / // % "//"除 "%"余 a = 20 b = 3 c = a // b d = a % b # 20 / 3 = ...
- hwclock详解
linux下hwclock命令详解 hwclock(hardware clock) 功能说明:显示与设定硬件时钟. 语 法:hwclock [--adjust][--debug][--directis ...