Java 8 Stream原理解析
说起 Java 8,我们知道 Java 8 大改动之一就是增加函数式编程,而 Stream API 便是函数编程的主角,Stream API 是一种流式的处理数据风格,也就是将要处理的数据当作流,在管道中进行传输,并在管道中的每个节点对数据进行处理,如过滤、排序、转换等。
首先我们先看一个使用Stream API的示例,具体代码如下:

code1 Stream example
这是个很简单的一个Stream使用例子,我们过滤掉空字符串后,转成int类型并计算出最大值,这其中包括了三个操作:filter、mapToInt、sum。相信大多数人再刚使用Stream API的时候都会有个疑问,Stream是指怎么实现的,是每一次函数调用就执行一次迭代吗?答案肯定是否,因为如果真的是每一次函数调用就执行一次迭代,这个效率是很难接受的,Stream也不会那么受欢迎。
其实Stream内部是通过流水线(Pipeline)的方式来实现的,基本思想是在迭代的时候顺着流水线尽可能的执行更多的操作,从而避免多次迭代。为了对Stream的操作有更清晰的认识,我们汇总了Stream的所有操作。
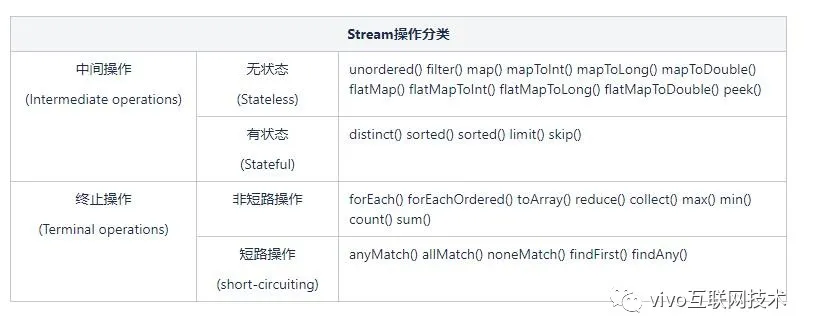
从上表可以看出Stream将所有操作分为两类:中间操作和终止操作。其中中间操作分为无状态和有状态,终止操作分为非短路操作和短路操作,下面是针对这几个操作的含义说明:
1、中间操作:中间操作只是一种标记,只有结束操作才会触发实际计算
- 无状态:指元素的处理不受前面元素的影响;
- 有状态:有状态的中间操作必须等到所有元素处理之后才知道最终结果,比如排序是有状态操作,在读取所有元素之前并不能确定排序结果。
2、终止操作:顾名思义,就是得出最后计算结果的操作
- 短路操作:指不用处理全部元素就可以返回结果;
- 非短路操作:指必须处理所有元素才能得到最终结果。
Stream流水线解决方案
通过上面的介绍,我们了解到Stream在执行中间操作时仅仅是记录,当用户调用终止操作时,会在一个迭代里将已经记录的操作顺着流水线全部执行掉。沿着这个思路,有几个问题需要解决:
- 用户的操作如何记录?
- 操作如何叠加?
- 叠加之后的操作如何执行?
1、操作如何记录
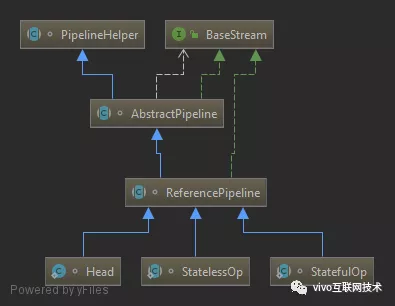
图1-1
关于操作如何记录,在JDK源码注释中多次用(操作)stage来标识用户的每一次操作,而通常情况下Stream的操作又需要一个回调函数,所以一个完整的操作是由数据来源、操作、回调函数组成的三元组来表示。而在具体实现中,使用实例化的ReferencePipeline来表示,即图1-1中的Head、StatelessOp、StatefulOp的实例。接下来我们来看下Stream几个常用方法的源码。
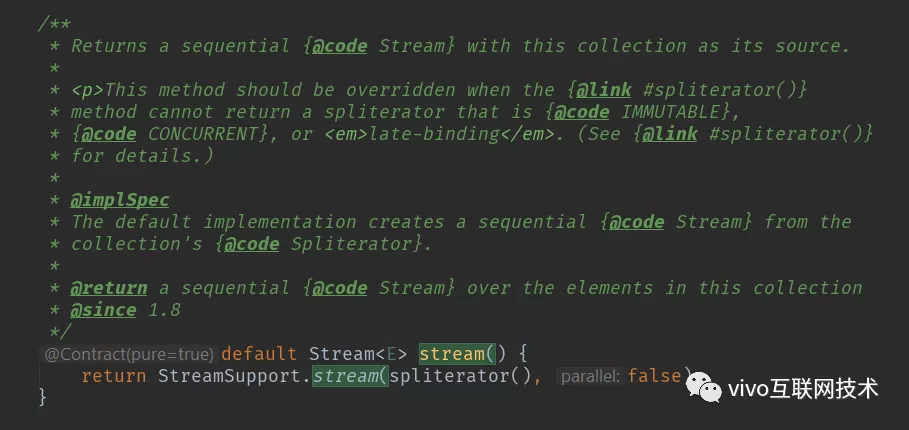
code2 Collection.Stream()

code3 StreamSupport.stream()
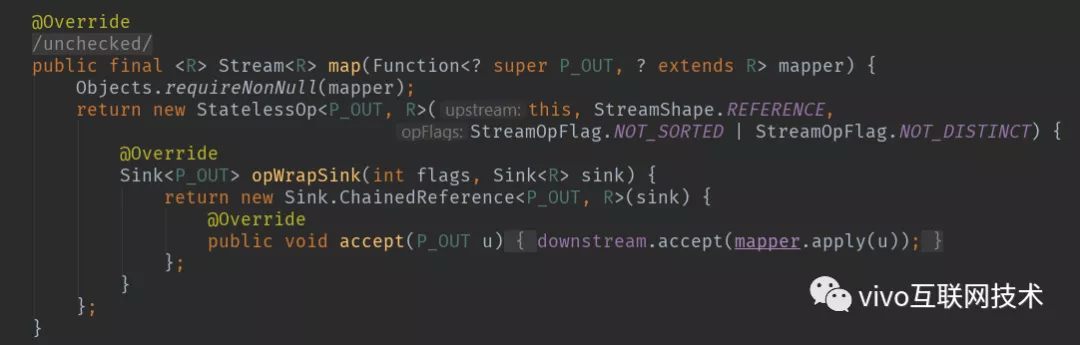
code4 ReferencePipeline.map()
从上面源码中可以看出来,我们调用stream()方法时最终会创建一个Head实例来表示流操作的头,当调用map()方法时则会创建无状态的中间操作实例StatelessOp,同样调用其他操作对应的方法也会生成一个ReferencePipeline实例,在这里就不一一列举。在用户调用一系列操作后,最终会形成一个双向链表,如下图所示:
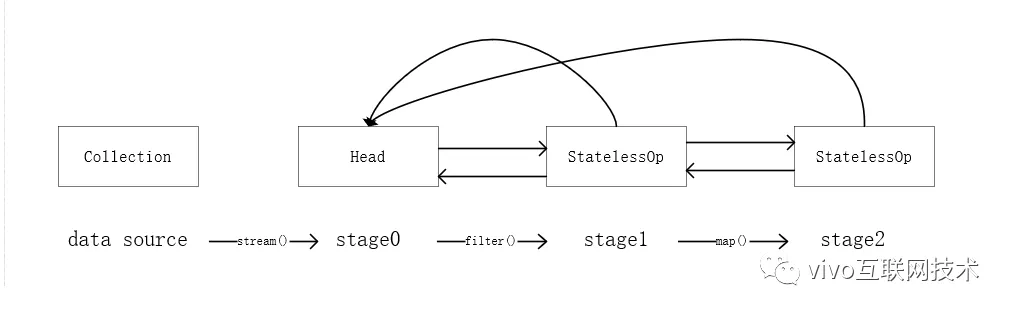
图1-2
2、操作如何叠加
上面我们说明了Stream是通过stage记录操作,但stage只保存当前操作,它并不知道下个stage如何操作,需要什么操作。所以要执行的话还需要某种协议将各个stage关联起来。jdk中就是使用Slink接口来实现的,Slink接口定义begin()、end()、cancellationRequested()、accept()四个方法,如下表所示。

往回看code3 ReferencePipeline.map()的方法,我们会发现我们在创建一个ReferencePipeline实例的时候,需要重写opWrapSink方法来生成对应Sink实例。而且通过阅读源码会发现常用的操作都会创建一个ChainedReference实例。我们可以看下code5 ChainedReference抽象类的源码实现,因为ChainedReference只是个抽象实现,不携带具体操作的特性,所以是更能体现作者的设计理念。
通过查看源码可以发现ChainedReference会持有下一个操作的Slink,并在调用begin、end、cancellationRequested方法会调用下一个操作的Slink的相应方法,以此来达到叠加的效果。
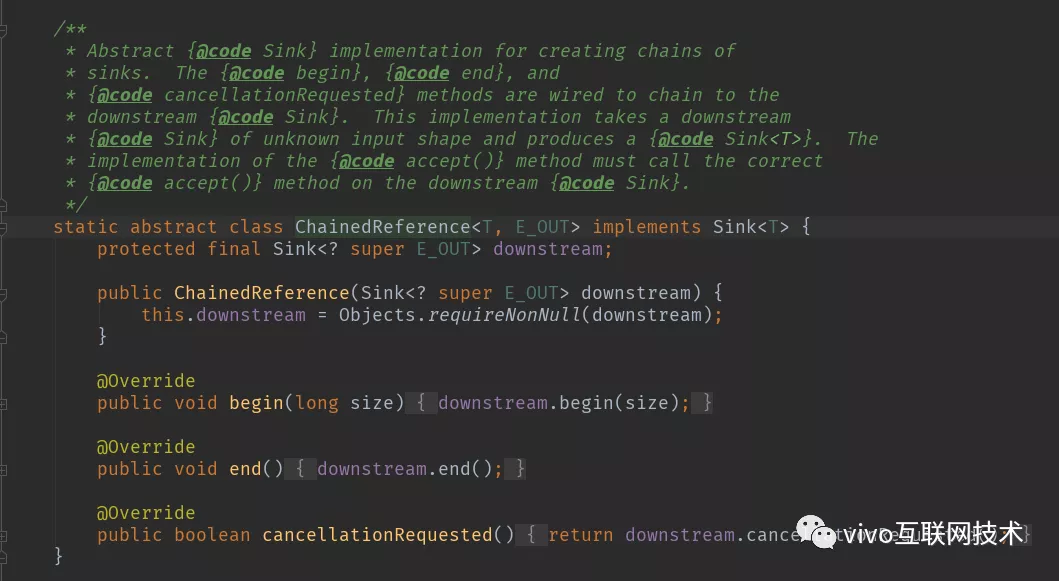
code5 ChainedReference
3、叠加之后的操作如何执行
Sink完美封装了Stream每一步操作,并给出了[处理->转发]的模式来叠加操作。这一连串的齿轮已经咬合,就差最后一步拨动齿轮启动执行。是什么启动这一连串的操作呢?也许你已经想到了启动的原始动力就是结束操作(Terminal Operation),一旦调用某个结束操作,就会触发整个流水线的执行。
结束操作之后不能再有别的操作,所以结束操作不会创建新的流水线阶段(Stage),直观的说就是流水线的链表不会在往后延伸了。结束操作会创建一个包装了自己操作的Sink,这也是流水线中最后一个Sink,这个Sink只需要处理数据而不需要将结果传递给下游的Sink(因为没有下游)。对于Sink的[处理->转发]模型,结束操作的Sink就是调用链的出口。
我们再来考察一下上游的Sink是如何找到下游Sink的。一种可选的方案是在PipelineHelper中设置一个Sink字段,在流水线中找到下游Stage并访问Sink字段即可。但Stream类库的设计者没有这么做,而是设置了一个Sink AbstractPipeline.opWrapSink(int flags, Sink downstream)方法来得到Sink,该方法的作用是返回一个新的包含了当前Stage代表的操作以及能够将结果传递给downstream的Sink对象。为什么要产生一个新对象而不是返回一个Sink字段?这是因为使用opWrapSink()可以将当前操作与下游Sink(上文中的downstream参数)结合成新Sink。试想只要从流水线的最后一个Stage开始,不断调用上一个Stage的opWrapSink()方法直到最开始(不包括stage0,因为stage0代表数据源,不包含操作),就可以得到一个代表了流水线上所有操作的Sink,用代码表示就是这样:
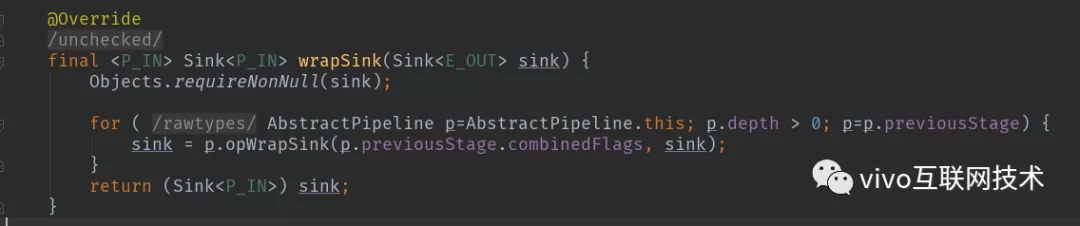
code6 AbstractPipeline.wrapSink
现在流水线上从开始到结束的所有的操作都被包装到了一个Sink里,执行这个Sink就相当于执行整个流水线,执行Sink的代码如下:
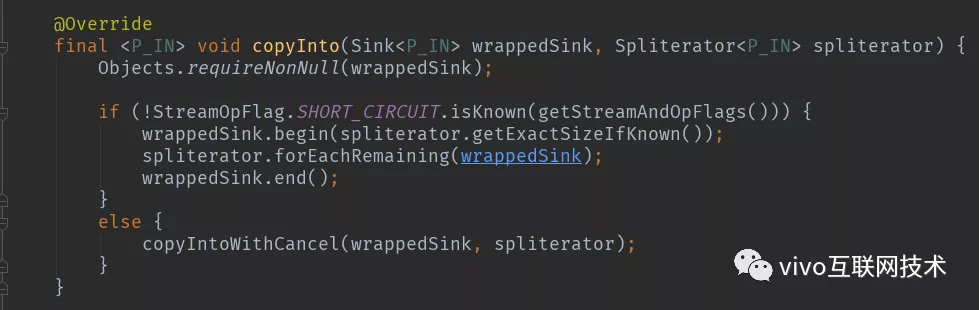
code7 AbstractPipeline.copyInto
上述代码首先调用wrappedSink.begin()方法告诉Sink数据即将到来,然后调用spliterator.forEachRemaining()方法对数据进行迭代,最后调用wrappedSink.end()方法通知Sink数据处理结束。逻辑如此清晰。
作者:Huang Rongpeng
Java 8 Stream原理解析的更多相关文章
- java线程池原理解析
五一假期大雄看了一本<java并发编程艺术>,了解了线程池的基本工作流程,竟然发现线程池工作原理和互联网公司运作模式十分相似. 线程池处理流程 原理解析 互联网公司与线程池的关系 这里用一 ...
- Java反序列化漏洞原理解析(案例未完善后续补充)
序列化与反序列化 序列化用途:方便于对象在网络中的传输和存储 java的反序列化 序列化就是将对象转换为流,利于储存和传输的格式 反序列化与序列化相反,将流转换为对象 例如:json序列化.XML序列 ...
- Java synchronized的原理解析
开始 类有一个特性叫封装,如果一个类,所有的field都是private的,而且没有任何的method,那么这个类就像是四面围墙+天罗地网,没有门.看起来就是一个封闭的箱子,外面的进不来,里面的出不去 ...
- java stream 原理
java stream 原理 需求 从"Apple" "Bug" "ABC" "Dog"中选出以A开头的名字,然后从中选 ...
- Java Web每天学之Servlet的原理解析
Java Web每天学之Servlet的工作原理解析,上海尚学堂Java技术文章Java Web系列之二上一篇文章Java Web每天学之Servlet的工作原理解析是之一,欢迎点击阅读. Servl ...
- 【转载】Java类加载原理解析
Java类加载原理解析 原文出处:http://www.blogjava.net/zhuxing/archive/2008/08/08/220841.html 1 基本信息 摘要: 每个j ...
- 【转】URL短地址压缩算法 微博短地址原理解析 (Java实现)
转自: URL短地址压缩算法 微博短地址原理解析 (Java实现) 最近,项目中需要用到短网址(ShortUrl)的算法,于是在网上搜索一番,发现有C#的算法,有.Net的算法,有PHP的算法,就是没 ...
- Java并发包JUC核心原理解析
CS-LogN思维导图:记录CS基础 面试题 开源地址:https://github.com/FISHers6/CS-LogN JUC 分类 线程管理 线程池相关类 Executor.Executor ...
- Java中多线程的使用(超级超级详细)线程安全原理解析 4
Java中多线程的使用(超级超级详细)线程安全 4 什么是线程安全? 有多个线程在同时运行,这些线程可能会运行相同的代码,程序运行的每次结果和单线程运行的结果是一样的,而且其他变量的值也和预期的值一样 ...
- Java volatile 关键字底层实现原理解析
本文转载自Java volatile 关键字底层实现原理解析 导语 在Java多线程并发编程中,volatile关键词扮演着重要角色,它是轻量级的synchronized,在多处理器开发中保证了共享变 ...
随机推荐
- java集合框架(三)ArrayList常见方法的使用
@[toc]## 一.什么是ArrarListArrayList是Java中的一个动态数组类,可以根据实际需要自动调整数组的大小.ArrayList是基于数组实现的,它内部维护的是一个Object数组 ...
- JPA动态注册多数据源
背景 目前已经是微服务的天下,但是随着业务需求的日益增长,部分应用还是出现了需要同时连接多个数据源操作数据的技术诉求. 需要对现有的技术架构进行优化升级,查阅了下网上的文章,基本都是照搬的同一篇文章, ...
- 【纯手工打造】时间戳转换工具(python)
1.背景 最近发现一个事情,如果日志中的时间戳,需要我们转换成时间,增加可读性.或者将时间转换成时间戳,来配置时间.相信大多人和我一样,都是打开网页,搜索在线时间戳转换工具,然后复制粘贴进去.个人认为 ...
- Java8新特性Stream流
1.是什么? Stream(流)是一个来自数据源的元素队列并支持聚合操作 2.能干嘛? Stream流的元素是特定类型的对象,形成一个队列. Java中的Stream并不会存储元素,而是按需计算. 数 ...
- 安卓之DocumentsProvider应用场景以及优劣分析
文章摘要 本文深入探讨了安卓DocumentsProvider的应用场景,分析了其优势与不足,并提供了简单的代码实现.DocumentsProvider是安卓系统中用于文件存储与访问的关键组件,为应用 ...
- 使用 GPT4V+AI Agent 做自动 UI 测试的探索
一.背景 从 Web 诞生之日起,UI 自动化就成了测试的难点,到现在近 30 年,一直没有有效的手段解决Web UI测试的问题,尽管发展了很多的 webdriver 驱动,图片 diff 驱动的工具 ...
- NetSuite Tips —— 发送邮件未被接收或被退回
Background: NS 发送的邮件过于频繁被邮箱系统识别为垃圾邮件,被拒收或被拦截 Solution: 添加以下邮箱地址到白名单 system@sent-via.netsuite.com nlm ...
- Bert-vits2最终版Bert-vits2-2.3云端训练和推理(Colab免费GPU算力平台)
对于深度学习初学者来说,JupyterNoteBook的脚本运行形式显然更加友好,依托Python语言的跨平台特性,JupyterNoteBook既可以在本地线下环境运行,也可以在线上服务器上运行.G ...
- JDK1.8下载阿里云盘不限速
JDK1.8下载阿里云盘不限速 专门给你写篇jdk文章容纳方便下载 废话不多说直接上链接 「jdk-8u202-windows-x64.exe」https://www.aliyundrive.com/ ...
- Collection和Map的区别
Collection接口,包含list和set子接口Collection和Map接口之间的主要区别在于:Collection中存储了一组对象,而Map存储关键字/值对.在Map对象中,每一个关键字最多 ...