神经网络优化篇:将 Batch Norm 拟合进神经网络(Fitting Batch Norm into a neural network)
将 Batch Norm 拟合进神经网络

假设有一个这样的神经网络,之前说过,可以认为每个单元负责计算两件事。第一,它先计算z,然后应用其到激活函数中再计算a,所以可以认为,每个圆圈代表着两步的计算过程。同样的,对于下一层而言,那就是\(z_{1}^{[2]}\)和\(a_{1}^{[2]}\)等。所以如果没有应用Batch归一化,会把输入\(X\)拟合到第一隐藏层,然后首先计算\(z^{[1]}\),这是由\(w^{[1]}\)和\(b^{[1]}\)两个参数控制的。接着,通常而言,会把\(z^{[1]}\)拟合到激活函数以计算\(a^{[1]}\)。但Batch归一化的做法是将\(z^{[1]}\)值进行Batch归一化,简称BN,此过程将由\({\beta}^{[1]}\)和\(\gamma^{[1]}\)两参数控制,这一操作会给一个新的规范化的\(z^{[1]}\)值(\({\tilde{z}}^{[1]}\)),然后将其输入激活函数中得到\(a^{[1]}\),即\(a^{[1]} = g^{[1]}({\tilde{z}}^{[ l]})\)。
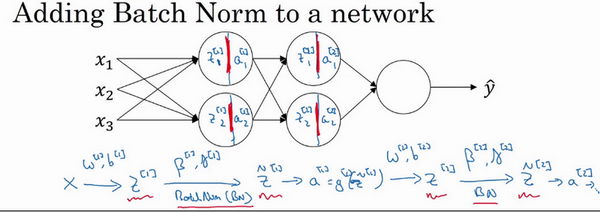
现在,已在第一层进行了计算,此时Batch归一化发生在z的计算和\(a\)之间,接下来,需要应用\(a^{[1]}\)值来计算\(z^{[2]}\),此过程是由\(w^{[2]}\)和\(b^{[2]}\)控制的。与在第一层所做的类似,会将\(z^{[2]}\)进行Batch归一化,现在简称BN,这是由下一层的Batch归一化参数所管制的,即\({\beta}^{[2]}\)和\(\gamma^{[2]}\),现在得到\({\tilde{z}}^{[2]}\),再通过激活函数计算出\(a^{[2]}\)等等。
所以需要强调的是Batch归一化是发生在计算\(z\)和\(a\)之间的。直觉就是,与其应用没有归一化的\(z\)值,不如用归一过的\(\tilde{z}\),这是第一层(\({\tilde{z}}^{[1]}\))。第二层同理,与其应用没有规范过的\(z^{[2]}\)值,不如用经过方差和均值归一后的\({\tilde{z}}^{[2]}\)。所以,网络的参数就会是\(w^{[1]}\),\(b^{[1]}\),\(w^{[2]}\)和\(b^{[2]}\)等等,将要去掉这些参数。但现在,想象参数\(w^{[1]}\),\(b^{[1]}\)到\(w^{[l]}\),\(b^{[l]}\),将另一些参数加入到此新网络中\({\beta}^{[1]}\),\({\beta}^{[2]}\),\(\gamma^{[1]}\),\(\gamma^{[2]}\)等等。对于应用Batch归一化的每一层而言。需要澄清的是,请注意,这里的这些\(\beta\)(\({\beta}^{[1]}\),\({\beta}^{[2]}\)等等)和超参数\(\beta\)没有任何关系,下面会解释原因,后者是用于Momentum或计算各个指数的加权平均值。Adam论文的作者,在论文里用\(\beta\)代表超参数。Batch归一化论文的作者,则使用\(\beta\)代表此参数(\({\beta}^{[1]}\),\({\beta}^{[2]}\)等等),但这是两个完全不同的\(\beta\)。在两种情况下都决定使用\(\beta\),以便阅读那些原创的论文,但Batch归一化学习参数\({\beta}^{[1]}\),\({\beta}^{\left\lbrack2 \right\rbrack}\)等等和用于Momentum、Adam、RMSprop算法中的\(\beta\)不同。

所以现在,这是算法的新参数,接下来可以使用想用的任何一种优化算法,比如使用梯度下降法来执行它。
举个例子,对于给定层,会计算\(d{\beta}^{[l]}\),接着更新参数\(\beta\)为\({\beta}^{[l]} = {\beta}^{[l]} - \alpha d{\beta}^{[l]}\)。也可以使用Adam或RMSprop或Momentum,以更新参数\(\beta\)和\(\gamma\),并不是只应用梯度下降法。
即使在之前的说明中,已经解释过Batch归一化是怎么操作的,计算均值和方差,减去均值,再除以方差,如果它们使用的是深度学习编程框架,通常不必自己把Batch归一化步骤应用于Batch归一化层。因此,探究框架,可写成一行代码,比如说,在TensorFlow框架中,可以用这个函数(tf.nn.batch_normalization)来实现Batch归一化,稍后讲解,但实践中,不必自己操作所有这些具体的细节,但知道它是如何作用的,可以更好的理解代码的作用。但在深度学习框架中,Batch归一化的过程,经常是类似一行代码的东西。
所以,到目前为止,已经讲了Batch归一化,就像在整个训练站点上训练一样,或就像正在使用Batch梯度下降法。
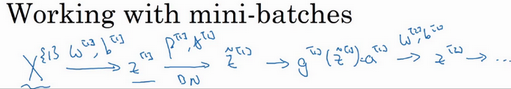
实践中,Batch归一化通常和训练集的mini-batch一起使用。应用Batch归一化的方式就是,用第一个mini-batch(\(X^{\{1\}}\)),然后计算\(z^{[1]}\),这和上面所做的一样,应用参数\(w^{[1]}\)和\(b^{[1]}\),使用这个mini-batch(\(X^{\{1\}}\))。接着,继续第二个mini-batch(\(X^{\{2\}}\)),接着Batch归一化会减去均值,除以标准差,由\({\beta}^{[1]}\)和\(\gamma^{[1]}\)重新缩放,这样就得到了\({\tilde{z}}^{[1]}\),而所有的这些都是在第一个mini-batch的基础上,再应用激活函数得到\(a^{[1]}\)。然后用\(w^{[2]}\)和\(b^{[2]}\)计算\(z^{[2]}\),等等,所以做的这一切都是为了在第一个mini-batch(\(X^{\{1\}}\))上进行一步梯度下降法。

类似的工作,会在第二个mini-batch(\(X^{\left\{2 \right\}}\))上计算\(z^{[1]}\),然后用Batch归一化来计算\({\tilde{z}}^{[1]}\),所以Batch归一化的此步中,用第二个mini-batch(\(X^{\left\{2 \right\}}\))中的数据使\({\tilde{z}}^{[1]}\)归一化,这里的Batch归一化步骤也是如此,让来看看在第二个mini-batch(\(X^{\left\{2 \right\}}\))中的例子,在mini-batch上计算\(z^{[1]}\)的均值和方差,重新缩放的\(\beta\)和\(\gamma\)得到\(z^{[1]}\),等等。

然后在第三个mini-batch(\(X^{\left\{ 3 \right\}}\))上同样这样做,继续训练。
现在,想澄清此参数的一个细节。先前说过每层的参数是\(w^{[l]}\)和\(b^{[l]}\),还有\({\beta}^{[l]}\)和\(\gamma^{[l]}\),请注意计算\(z\)的方式如下,\(z^{[l]} =w^{[l]}a^{\left\lbrack l - 1 \right\rbrack} +b^{[l]}\),但Batch归一化做的是,它要看这个mini-batch,先将\(z^{[l]}\)归一化,结果为均值0和标准方差,再由\(\beta\)和\(\gamma\)重缩放,但这意味着,无论\(b^{[l]}\)的值是多少,都是要被减去的,因为在Batch归一化的过程中,要计算\(z^{[l]}\)的均值,再减去平均值,在此例中的mini-batch中增加任何常数,数值都不会改变,因为加上的任何常数都将会被均值减去所抵消。

所以,如果在使用Batch归一化,其实可以消除这个参数(\(b^{[l]}\)),或者也可以,暂时把它设置为0,那么,参数变成\(z^{[l]} = w^{[l]}a^{\left\lbrack l - 1 \right\rbrack}\),然后计算归一化的\(z^{[l]}\),\({\tilde{z}}^{[l]} = \gamma^{[l]}z^{[l]} + {\beta}^{[l]}\),最后会用参数\({\beta}^{[l]}\),以便决定\({\tilde{z}}^{[l]}\)的取值,这就是原因。
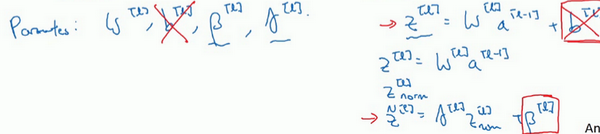
所以总结一下,因为Batch归一化超过了此层\(z^{[l]}\)的均值,\(b^{[l]}\)这个参数没有意义,所以,必须去掉它,由\({\beta}^{[l]}\)代替,这是个控制参数,会影响转移或偏置条件。
最后,请记住\(z^{[l]}\)的维数,因为在这个例子中,维数会是\((n^{[l]},1)\),\(b^{[l]}\)的尺寸为\((n^{[l]},1)\),如果是l层隐藏单元的数量,那\({\beta}^{[l]}\)和\(\gamma^{[l]}\)的维度也是\((n^{[l]},1)\),因为这是隐藏层的数量,有\(n^{[l]}\)隐藏单元,所以\({\beta}^{[l]}\)和\(\gamma^{[l]}\)用来将每个隐藏层的均值和方差缩放为网络想要的值。
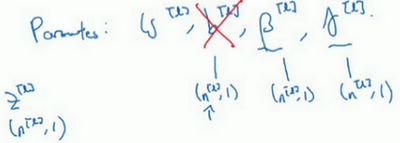
让总结一下关于如何用Batch归一化来应用梯度下降法,假设在使用mini-batch梯度下降法,运行\(t=1\)到batch数量的for循环,会在mini-batch \(X^{\left\{ t\right\}}\)上应用正向prop,每个隐藏层都应用正向prop,用Batch归一化代替\(z^{[l]}\)为\({\tilde{z}}^{[l]}\)。接下来,它确保在这个mini-batch中,\(z\)值有归一化的均值和方差,归一化均值和方差后是\({\tilde{z}}^{[l]}\),然后,用反向prop计算\(dw^{[l]}\)和\(db^{[l]}\),及所有l层所有的参数,\(d{\beta}^{[l]}\)和\(d\gamma^{[l]}\)。尽管严格来说,因为要去掉\(b\),这部分其实已经去掉了。最后,更新这些参数:\(w^{[l]} = w^{[l]} -\text{αd}w^{[l]}\),和以前一样,\({\beta}^{[l]} = {\beta}^{[l]} - {αd}{\beta}^{[l]}\),对于\(\gamma\)也是如此\(\gamma^{[l]} = \gamma^{[l]} -{αd}\gamma^{[l]}\)。
如果已将梯度计算如下,就可以使用梯度下降法了,这就是写到这里的,但也适用于有Momentum、RMSprop、Adam的梯度下降法。与其使用梯度下降法更新mini-batch,可以使用这些其它算法来更新,也可以应用其它的一些优化算法来更新由Batch归一化添加到算法中的\(\beta\) 和\(\gamma\) 参数。

能学会如何从头开始应用Batch归一化,如果想的话。如果使用深度学习编程框架之一,之后会谈。如果希望可以直接调用别人的编程框架,这会使Batch归一化的使用变得很容易。
神经网络优化篇:将 Batch Norm 拟合进神经网络(Fitting Batch Norm into a neural network)的更多相关文章
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- zz图像、神经网络优化利器:了解Halide
动图示例实在太好 图像.神经网络优化利器:了解Halide Oldpan 2019年4月17日 0条评论 1,327次阅读 3人点赞 前言 Halide是用C++作为宿主语言的一个图像处理相 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
- Halide视觉神经网络优化
Halide视觉神经网络优化 概述 Halide是用C++作为宿主语言的一个图像处理相关的DSL(Domain Specified Language)语言,全称领域专用语言.主要的作用为在软硬层面上( ...
- AWS研究热点:BMXNet – 基于MXNet的开源二进神经网络实现
http://www.atyun.com/9625.html 最近提出的二进神经网络(BNN)可以通过应用逐位运算替代标准算术运算来大大减少存储器大小和存取率.通过显着提高运行时的效率并降低能耗,让最 ...
- [Spring Batch 系列] 第一节 初识 Spring Batch
距离开始使用 Spring Batch 有一段时间了,一直没有时间整理,现在项目即将完结,整理下这段时间学习和使用经历. 官网地址:http://projects.spring.io/spring-b ...
- 神经网络中Batch Size的理解
直观的理解:Batch Size定义:一次训练所选取的样本数.Batch Size的大小影响模型的优化程度和速度.同时其直接影响到GPU内存的使用情况,假如你GPU内存不大,该数值最好设置小一点. 为 ...
- Neural Network Toolbox使用笔记1:数据拟合
http://blog.csdn.net/ljp1919/article/details/42556261 Neural Network Toolbox为各种复杂的非线性系统的建模提供多种函数和应用程 ...
- 过拟合和欠拟合(Over fitting & Under fitting)
欠拟合(Under Fitting) 欠拟合指的是模型没有很好地学习到训练集上的规律. 欠拟合的表现形式: 当模型处于欠拟合状态时,其在训练集和验证集上的误差都很大: 当模型处于欠拟合状态时,根本的办 ...
随机推荐
- SpringCloud Alibaba技术栈(一)微服务介绍
B 站黑马视频教程:Here 源码-笔记:Code for Github 第一章 微服务总览 1. 软件系统架构的历史 软件系统架构大致经历了:单体应用架构->垂直应用架构->分布式架构- ...
- L3-008 喊山 (30 分) (BFS)
喊山,是人双手围在嘴边成喇叭状,对着远方高山发出"喂-喂喂-喂喂喂--"的呼唤.呼唤声通过空气的传递,回荡于深谷之间,传送到人们耳中,发出约定俗成的"讯号",达 ...
- iOS Class Guard github用法、工作原理和安装详解及使用经验总结
iOS Class Guard github用法.工作原理和安装详解及使用经验总结 iOS Class Guard是一个用于OC类.协议.属性和方法名混淆的命令行工具.它是class-dump的扩展 ...
- k8s探针详解
一.探针类型 Kubernetes(k8s)中的探针是一种健康检查机制,用于监测Pod内容器的运行状况.主要包括以下三种类型的探针: 1.存活探针(Liveness Probe) 2.就绪探针(Rea ...
- vue-router路由复用后页面没有刷新
vue-router提供了页面路由功能,可以用来构建单页面应用,在使用vue-router的动态路由匹配的时候,遇到了url变化了,但是页面却没有任何动静的问题,记录一下. 动态路由匹配url变化了, ...
- zookeeper 特点、使用场景及安装,配置文件解析
本文为博主原创,未经允许不得转载: 1. Zookeeper 特点: ZooKeeper是用于分布式应用程序的协调服务.它公开了一组简单的API,分布式应用程序可以基于这些API用于同步,节点状态.配 ...
- 00.Oracle 11g安装
通过Docker安装Oracle 1.搜索镜像 先使用指令搜素远程仓库中的Oracle镜像 sudo docker search docker-oracle-xe-11g 2.拉取镜像 选择一个sta ...
- Linux_sqlcmd或者是Cloudquery连接SQLSERVER2012的问题解决
Linux_sqlcmd或者是Cloudquery连接SQLSERVER2012的问题解决 背景 最近想使用shell脚本给SQLServer数据库插入数据,但是发现了报错 同时进行CLoudquer ...
- [转帖]Linux中的inode到底是什么
https://www.jianshu.com/p/6aa4d7ef17de inode 是什么? 要了解 Linux 操作系统上的 inode 前,我们先来说说 Linux操作系统上的文件.对于 L ...
- [转帖]Jmeter脚本录:抓取https请求
Jmeter抓取http请求 https://blog.csdn.net/qq19970496/article/details/86595109 代理设置步骤请参照该篇文章.本文件只做补充HTTPS中 ...