Kubernetes OOM 和 CPU Throttling 问题
介绍
使用 Kubernetes 时,内存不足(OOM)错误和 CPU 限制(Throttling)是云应用程序中资源处理的主要难题。为什么呢?
云应用程序中的 CPU 和内存要求变得越来越重要,因为它们与您的云成本直接相关。
通过 limits 和 requests,您可以配置 pod 应如何分配内存和 CPU 资源,以防止资源匮乏并调整云成本。
- 如果节点没有足够的资源,Pod 可能会因抢占或节点压力而被驱逐。
- 当进程运行内存不足 (OOM) 时,它会因为没有所需的资源而被 Kill。
- 如果 CPU 消耗高于实际
limits,进程将开始受到限制。
OK,如何监控 Pod 快要 OOM 了,或者 CPU 快要被限制了呢?
Kubernetes OOM
Pod 中的每个容器都需要内存才能运行。
Kubernetes limits 是在 Pod 定义或 Deployment 定义中为每个容器设置的。
所有现代 Unix 系统都有一种方法可以杀死进程,以此回收内存(没用空闲内存的时候,只能杀进程了)。这个错误将被标记为 137 错误码或 OOMKilled。
State: Running
Started: Thu, 10 Oct 2019 11:14:13 +0200
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Thu, 10 Oct 2019 11:04:03 +0200
Finished: Thu, 10 Oct 2019 11:14:11 +0200退出代码 137 意味着该进程使用的内存超过允许的数量,必须被 OS 终止。
这是 Linux 中的一项功能,内核为系统中运行的进程设置 oom_score 值。此外,它还允许设置一个名为 oom_score_adj 的值,Kubernetes 使用该值来实现服务质量。它还具有 OOM Killer,它将检查进程并终止那些使用超过过多内存(比如申请了超过 limits 限制的数量的内存)的进程。
请注意,在 Kubernetes 中,进程可能会达到以下任何限制:
- 在容器上设置的 Kubernetes 限制。
- 在 namespace 上设置的 Kubernetes ResourceQuota。
- 节点的实际内存大小。
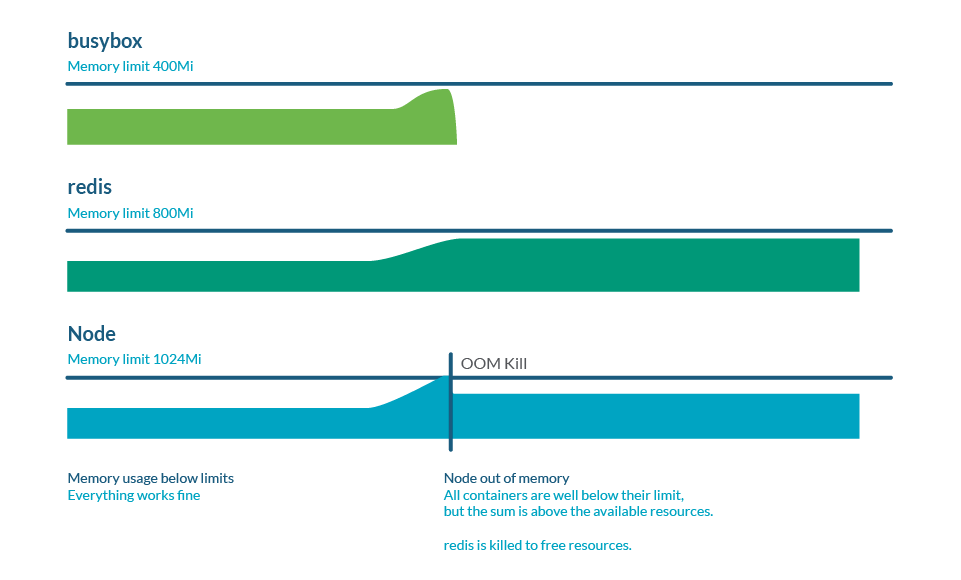
内存过量分配(overcommitment)
限制(limits)可以高于请求(requests),因此所有限制的总和可以高于节点容量。这称为过量分配,而且很常见。实际上,如果所有容器使用的内存多于 request 的内存,则可能会耗尽节点中的内存。这通常会导致一些 pod 死亡,以释放一些内存。
监控 Kubernetes OOM
在 Prometheus 生态中,使用 node-exporter 时,有一个名为 node_vmstat_oom_kill 的指标。跟踪 OOM 终止何时发生非常重要,但您可能希望在此类事件发生之前抢占先机并了解其情况。
我们更希望的是,检查进程与 Kubernetes limits 的接近程度:
(sum by (namespace,pod,container)
(rate(container_cpu_usage_seconds_total{container!=""}[5m])) / sum by
(namespace,pod,container)
(kube_pod_container_resource_limits{resource="cpu"})) > 0.8Kubernetes CPU throttling
CPU 限制(throttling)是一种当进程即将达到某些资源限制时减慢速度的行为。与内存情况类似,这些限制可能是:
- 在容器上设置的 Kubernetes limits。
- 在命名空间上设置的 Kubernetes ResourceQuota。
- 节点的实际算力大小。
想想下面的类比。我们有一条高速公路,交通流量如下:
- CPU 就好比一条路
- 车辆代表 Process,每辆车都有不同的尺寸
- 多个通道代表有多个 CPU 核心
- request 将是一条专用道路,例如自行车道
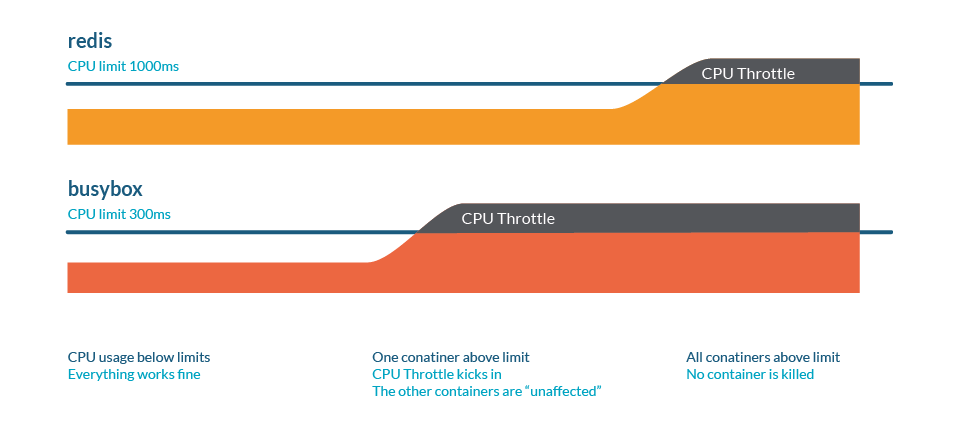
这里的 throttling 被表示为交通拥堵:最终,所有进程都会运行,但一切都会变慢。
Kubernetes 中的 CPU 处理逻辑
CPU 在 Kubernetes 中通过 shares 进行处理。每个 CPU 核心被分为 1024 个 shares,然后使用 Linux 内核的 cgroups(control groups)功能在运行的所有进程之间进行划分。
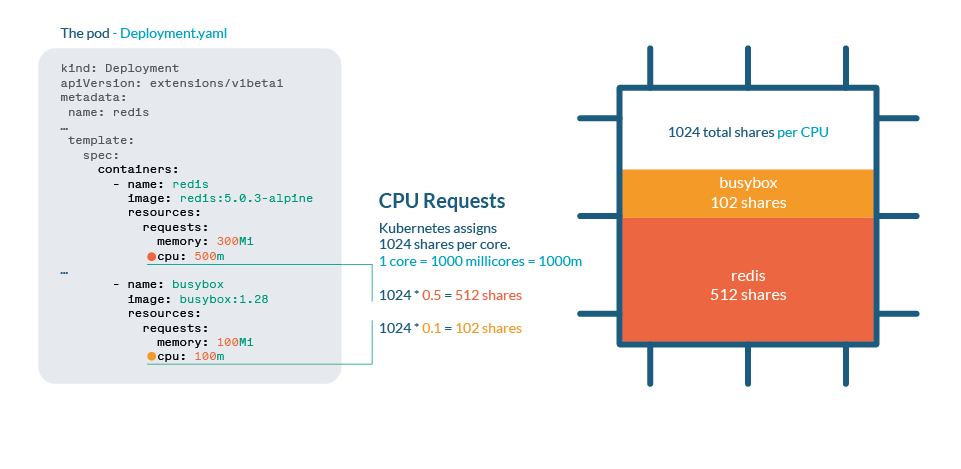
如果 CPU 可以处理当前所有进程,则无需执行任何操作。如果进程使用超过 100% 的 CPU,shares 机制就要起作用了。与任何 Linux 内核一样,Kubernetes 使用 CFS(Completely Fair Scheduler)机制,因此拥有更多份额的进程将获得更多的 CPU 时间。
与内存不同,Kubernetes 不会因为限流而杀死 Pod。
You can check CPU stats in /sys/fs/cgroup/cpu/cpu.stat
CPU 过渡分配
正如我们在limits 和 requests 文章中看到的,当我们想要限制进程的资源消耗时,设置 limits 或 requests 非常重要。尽管如此,请注意不要将总 requests 设置为大于实际 CPU 大小,每个容器都应该有保证的 CPU。
监控 Kubernetes CPU throttling
您可以检查进程与 Kubernetes limits 的接近程度:
(sum by (namespace,pod,container)(rate(container_cpu_usage_seconds_total
{container!=""}[5m])) / sum by (namespace,pod,container)
(kube_pod_container_resource_limits{resource="cpu"}))如果我们想要跟踪集群中发生的限制量,cadvisor 提供了 container_cpu_cfs_throttled_periods_total 和 container_cpu_cfs_periods_total 两个指标。通过这两个指标,您可以轻松计算所有 CPU 周期内的限制百分比。
最佳实践
注意 limits 和 requests
Limits 是在节点中设置资源最大上限的一种方法,但需要谨慎对待,因为您可能最终会受到限制或终止进程。
准备好应对驱逐
通过设置非常低的请求,您可能认为这将为您的进程授予最少的 CPU 或内存。但 kubelet 会首先驱逐那些使用率高于请求的 Pod,因此就相当于您将这些进程标记为最先被杀死的!
如果您需要保护特定 Pod 免遭抢占(当 kube-scheduler 需要分配新 Pod 时),请为最重要的进程分配 Priority Classes。
Throttling 是一个无声的敌人
设置不切实际的 limits 或过度使用,您可能没有意识到您的进程正在受到限制并且性能受到影响。主动监控 CPU 用量,了解确切的容器和命名空间层面的限制,及时发现问题非常重要。
附
下面这张图,比较好的解释了 Kubernetes 中 CPU 和内存的限制问题。供参考:
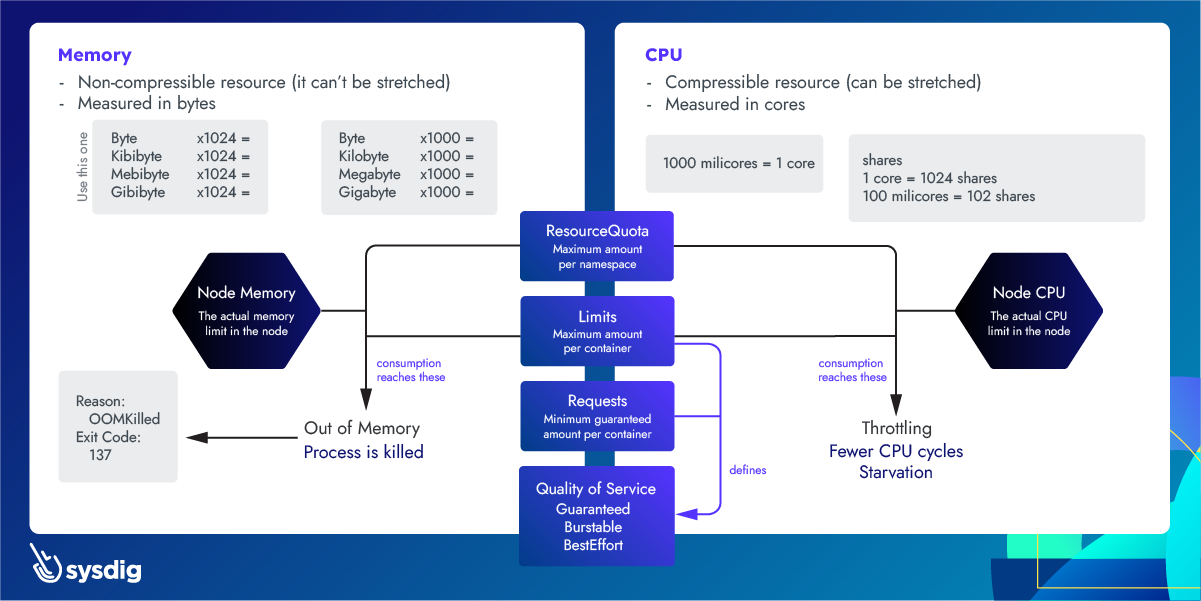
Kubernetes OOM 和 CPU Throttling 问题的更多相关文章
- 关于在centos6 + grub的旧版本中,如何关闭CPU throttling
由于个人需求,要编译安装ATLAS库,其中就有关闭CPU throttling的步骤, 最常规简单的方法是修改grub /etc/default/grub/ 之后再接一些简单的步骤 + 重启就完成了. ...
- Kubernetes K8S之CPU和内存资源限制详解
Kubernetes K8S之CPU和内存资源限制详解 Pod资源限制 备注:CPU单位换算:100m CPU,100 milliCPU 和 0.1 CPU 都相同:精度不能超过 1m.1000m C ...
- docker对cpu使用及在kubernetes中的应用
docker对CPU的使用 docker对于CPU的可配置的主要几个参数如下: --cpu-shares CPU shares (relative weight) --cpu-period Limit ...
- 深入理解 Kubernetes 资源限制:CPU
原文地址:https://www.yangcs.net/posts/understanding-resource-limits-in-kubernetes-cpu-time/ 在关于 Kubernet ...
- [Kubernetes]资源模型与资源管理
作为 Kubernetes 的资源管理与调度部分的基础,需要从它的资源模型说起. 资源管理模型的设计 我们知道,在 Kubernetes 里面, Pod 是最小的原子调度单位,这就意味着,所有和调度和 ...
- kubernetes 降本增效标准指南| 资源利用率提升工具大全
背景 公有云的发展为业务的稳定性.可拓展性.便利性带来了极大帮助.这种用租代替买.并且提供完善的技术支持和保障的服务,理应为业务带来降本增效的效果.但实际上业务上云并不意味着成本一定较少,还需适配云上 ...
- 【kubernetes入门到精通】Kubernetes的健康监测机制以及常见ExitCode问题分析「探索篇」
kubernetes进行Killed我们服务的问题背景 无论是在微服务体系还是云原生体系的开发迭代过程中,通常都会以Kubernetes进行容器化部署,但是这也往往带来了很多意外的场景和情况.例如,虽 ...
- 全面了解 Linux 服务器 - 1. 查看 Linux 服务器的 CPU 详细情况
1. 查看 Linux 服务器的 CPU 详细情况 判断依据: 具有相同的 core id 的 CPU 是同意个 core 超线程. 具有相同的 physical id 的 CPU 是同一个 CPU ...
- 记一次Web应用CPU偏高
LZ开发的一个公司内部应用供查询HIVE数据使用.部署上线后总是会出现CPU偏高的情况,而且本地测试很难重现.之前出现几次都是通过直接重启后继续使用,因为是内部使用,重启一下也没有很大影响(当然,每次 ...
- Kubernetes 1.8火热出炉:稳定性、安全性与存储支持能力全面提升
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/M2l0ZgSsVc7r69eFdTj/article/details/78130225 周三,Kub ...
随机推荐
- 力扣263(java)-丑数(简单)
题目: 丑数 就是只包含质因数 2.3 和 5 的正整数. 给你一个整数 n ,请你判断 n 是否为 丑数 .如果是,返回 true :否则,返回 false . 示例 1: 输入:n = 6输出:t ...
- OpenKruise v1.0:云原生应用自动化达到新的高峰
简介:OpenKruise 是针对 Kubernetes 的增强能力套件,聚焦于云原生应用的部署.升级.运维.稳定性防护等领域. 云原生应用自动化管理套件.CNCF Sandbox 项目 -- Op ...
- 2021云栖大会丨阿里云发布第四代神龙架构,提供业界首个大规模弹性RDMA加速能力
简介: 10月20日,2021年杭州栖大云会上,阿里云发布第四代神龙架构,升级至全新的eRMDA网络架构,是业界首个大规模弹性RDMA加速能力. 10月20日,2021年杭州栖大云会上,阿里云发布第 ...
- Flink CDC 2.0 正式发布,详解核心改进
简介: 本文由社区志愿者陈政羽整理,内容来源自阿里巴巴高级开发工程师徐榜江 (雪尽) 7 月 10 日在北京站 Flink Meetup 分享的<详解 Flink-CDC>.深入讲解了最新 ...
- Cube 技术解读 | 支付宝新一代动态化技术架构与选型综述
简介: 支付宝客户端的动态化技术经历三个阶段:现阶段也就是第三阶段是实体组件+部分光栅化的hybrid模式,Cube 就是该模式下的产物. 如标题所述,笔者将持续更新<Cube 技术解读& ...
- [Ethereum] 浅谈 ERC20 在 openzeppelin-contracts 中的结构与实现
目前 openzeppelin-contracts 的稳定版是 v2.5,截止到本文发布,最新的 Tag 为 v3.0.0-rc.0 以下是 token/ETC20 的文件列表: IERC20.sol ...
- OSI模型之网络层
一.简介 网络层是OSI参考模型中的第三层,同时也是TCP/IP模型的第二层.它介于传输层和数据链路层之间,主要任务是把分组从源端传到目的端,为分组交换网上的不同主机提供通信服务.网络层传输单位是数据 ...
- 如何用python运用ocr技术来识别文字
要先安装ocr技术,也就是光学符号识别,通过扫描等光学输入方式将各种票据.报刊.书籍.文稿及其他印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的文本的技术(我在百度百科抄的), ...
- 开源相机管理库Aravis例程学习(六)——camera-features
目录 简介 例程代码 函数说明 arv_camera_get_integer arv_camera_get_string 简介 本文针对官方例程中的:04-camera-features做简单的讲解. ...
- 简说Python之列表,元祖,字典
目录 Python列表 创建列表 添加元素 查询元素 列表分片 分片简写 修改元素 一些其他添加列表元素的方法 extend() insert() 删除元素 remove()删除 del 通过索引删除 ...