[转帖] 拒绝蛮力,高效查看Linux日志文件!
https://www.cnblogs.com/codelogs/p/16410363.html
原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,转载请保留出处。
简介#
日常分析问题时,会频繁地查看分析日志,但如果蛮力去查看日志,耗时费力还不一定有效果,因此我总结了在Linux常用的一些日志查看技巧,提升日志阅读效率。
grep查找日志#
在我们查找某些异常日志时,经常需要同时查看异常前面或后面的一些日志,因为有时前面或后面的日志就已经标识出异常原因了,而grep的-A、-B、-C选项就提供了这种功能,如下:
# 查找ERROR日志,以及它的后10行
$ grep -A 10 ERROR app.log
# 查找ERROR日志,以及它的前10行
$ grep -B 10 ERROR app.log
# -C代表前10行和后10行
$ grep -C 10 ERROR app.log
查看某个时间段的日志#
有时,需要查看某个时间段的日志,比如凌晨2点15分系统出现报警,上班后我们想看看这段时间的日志,看能不能找到点线索,方法如下:
# 导出02:14到02:16分的日志
awk '/2022-06-24T02:14/,/2022-06-24T02:1[6-9]/' app.log > app0215.log
# 使用sed也是可以的
sed -n '/2022-06-24T02:14/,/2022-06-24T02:1[6-9]/p' app.log > app0215.log
注:awk与sed实际并不解析时间,它们只是按正则匹配,匹配到第一个正则时,开始输出行,直到遇到第二个正则关闭,所以如果你的日志中没有能匹配第二个正则的行,将导致一直输出到尾行!所以一般需要将第二个正则变宽松点,如上面的/2022-06-24T02:1[6-9]/,以避免出现这种情况
查看最后10条错误#
更多情况是,上班时发现系统有报警,于是想立马看看刚刚发生了什么,即查找最近的异常日志,如下:
# 最容易想到的是tail,但有可能最后1000行日志全是正常日志
$ tail -n 1000 app.log | less
# 最后10条异常, tac会反向读取日志行,然后用grep找到10个异常日志,再用tac又反向一次就正向了
$ tac app.log | grep -n -m10 ERROR | tac
还有一种是从刚报警的时间点开始导出到尾行,比如从2分钟前的5点15分开始导出,如下:
$ tac app.log | sed '/2022-06-24T17:15/q' | tac > app1715.log
原理与上面类似,只不过是换成了sed,sed默认会输出处理的每一行,而q指令代表退出程序,所以上面程序含义是从日志末尾开始输出日志,直到遇到正则/2022-06-24T17:15/停止输出。
awk分段查找#
对于像Java程序,异常日志一般会是一段一段的,且每段带有异常栈,如下: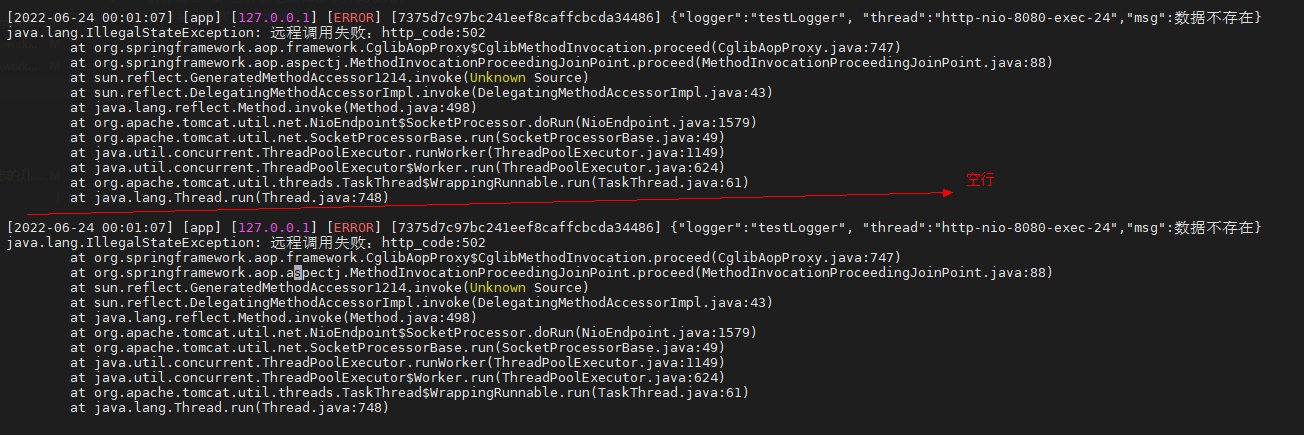
但grep是一行一行过滤的,如何一整段一整段的过滤异常栈呢?awk就提供了这种功能,当将awk中RS变量指定为空时,awk就会一段一段的读取并处理文本,如下:
# 查找异常日志,并保留异常栈
awk -v RS= -v ORS='\n\n' '/Exception/' app_error.log | less
-v RS=等效于-v RS='',设置RS变量为空,使得awk一段一段地读取日志-v ORS='\n\n'设置ORS变量为2个换行,使得awk一段一段的输出/Exception/代表过滤出包含正则Exception的段
使用less查看#
一般情况下,使用less可以更快速的查看日志,比如通过tail -n10000取出最近1w条日志,通过less查看,如下:
tail -n 10000 app.log | less
看日志时,有一个很常见的需求,就是很多日志都是当前不需要关心的,需要将它们过滤掉,less提供了&/的功能,可快速过滤掉不想看的日志,从而找到问题日志,如下: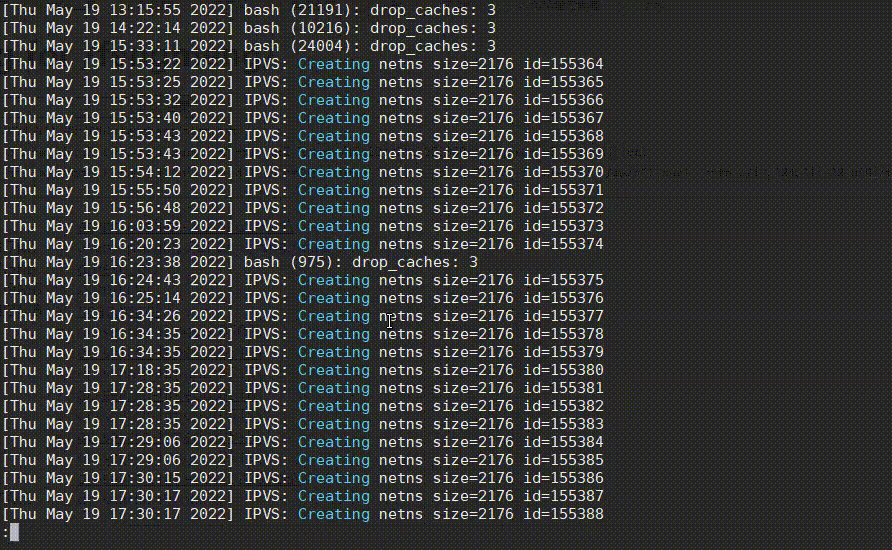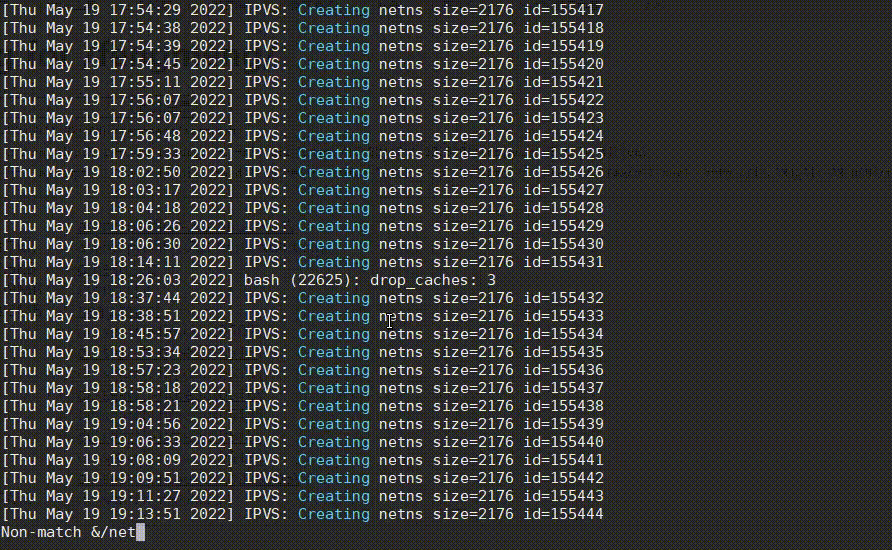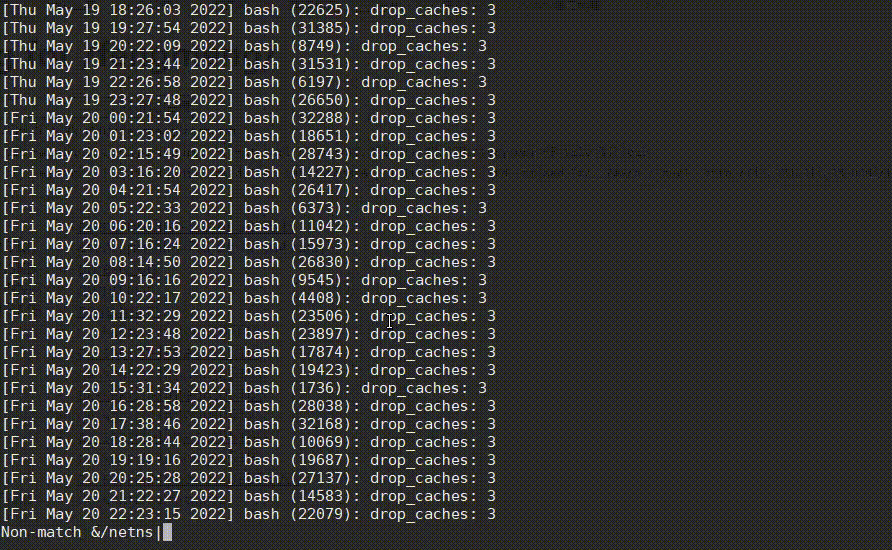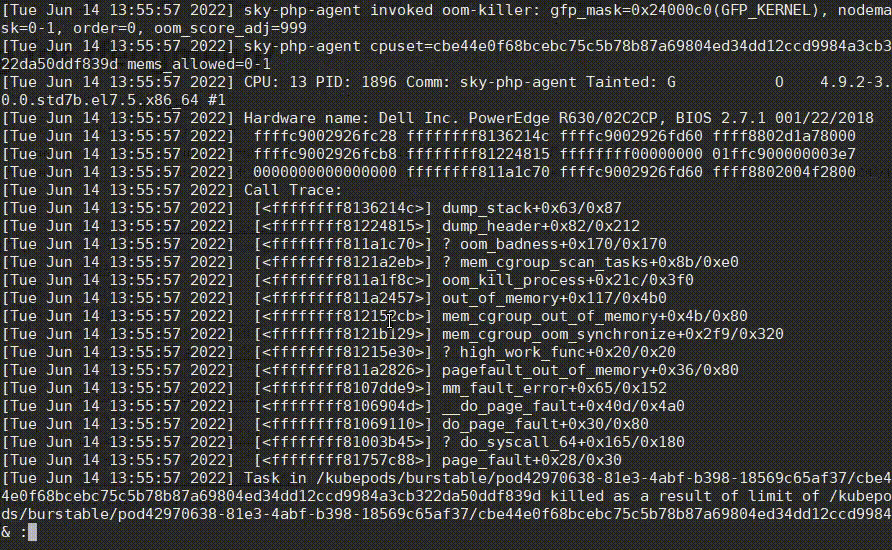
操作步骤:
- 先输入
&,再输入!进入Non-match过滤模式。 - 然后输入正则
netns,再按Enter,排除掉这种正常的日志,过滤后又发现有很多drop_caches日志。 - 然后也是先输入
&,再输入!,再直接按上箭头快速获取上次的输入内容,再接着输入|drop_caches,将drop_caches日志也过滤掉。 - 哦豁,发现了一个oom killer日志!
使用vim查看#
less可以一行一行的排除,但如果要一段一段的排除,如日志中经常会有一些常见且无影响的错误日志,这种情况可以通过vim配合awk排除,如下:
tail -n 10000 app_error.log | vim -
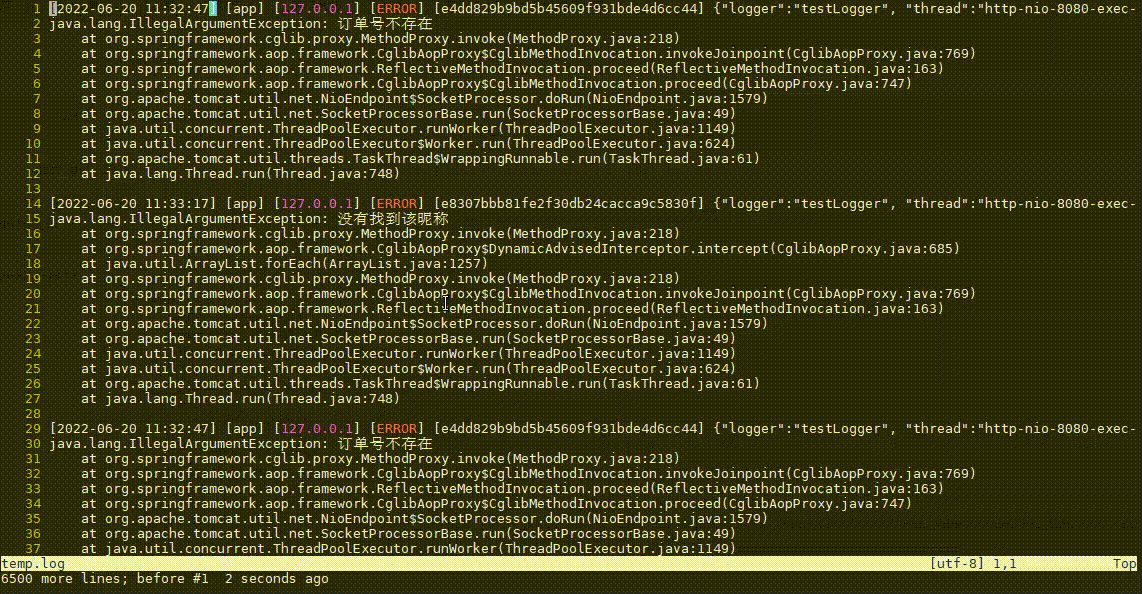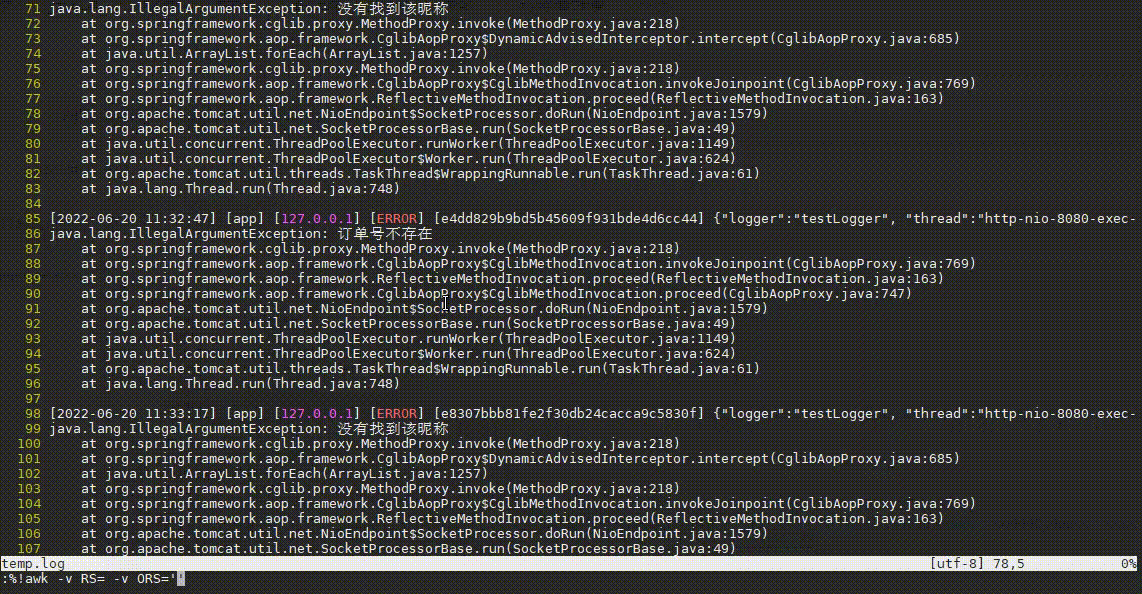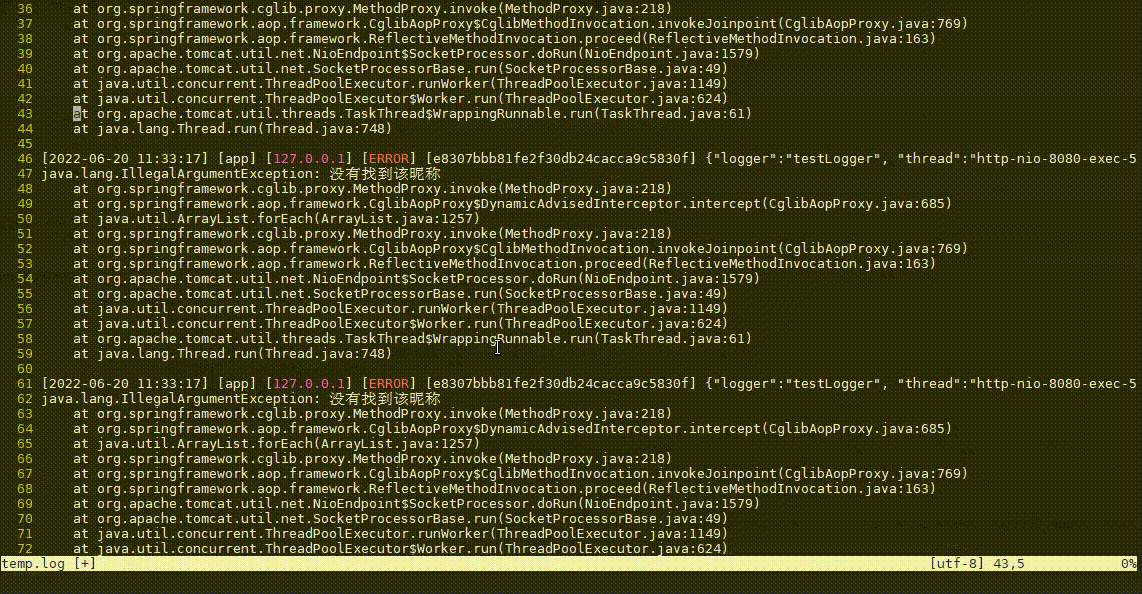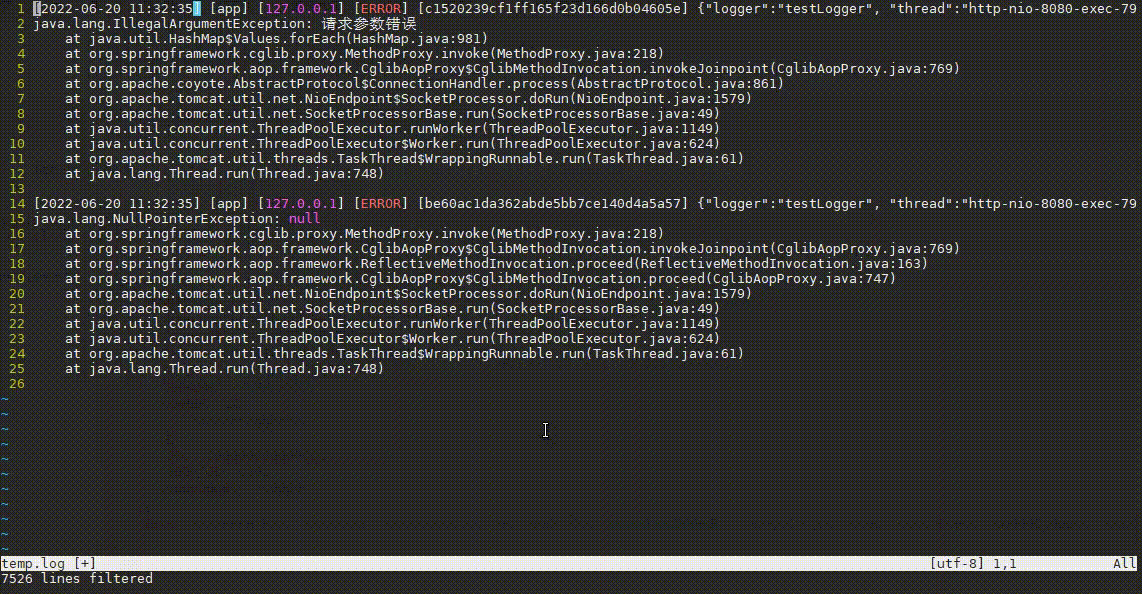
操作步骤:
- 先输入
:,进入vim的命令模式 - 再输入
%!awk -v RS= -v ORS='\n\n' ...,执行awk命令,其中%代表当前文件所有内容,!代表执行命令,所以%!代表将当前文件内容输入到命令中 - 然后awk规则中输入
'\!/订单号不存在/'并回车,这代表排除段中包含订单号不存在的段,排除后又发现很多没有找到该昵称异常。 - 接着输入
:再按上箭头快速获取上次输入内容,并补充&& \!/没有找到该昵称/,将这种常见异常也过滤掉。 - 哦豁,发现了一个NullPointerException异常!
其它工具#
有时为节省磁盘空间,日志会压缩成*.gz格式,这也是可以直接查看的,如下:
# 类似cat,同时解压并输出内容
zcat app.log.gz
# 类似grep,同时解压并查找内容
zgrep -m 10 ERROR app.log.gz
# 类似less,同时解压并查看内容
zless app.log.gz
而在处理时间方面,dateutils工具包用起来会更方便一些,如下:
# CentOS7安装dateutils
$ wget https://download-ib01.fedoraproject.org/pub/epel/8/Everything/x86_64/Packages/d/dateutils-0.4.9-1.el8.x86_64.rpm && rpm -Uvh dateutils-0.4.9-1.el8.x86_64.rpm
# Ubuntu安装dateutils
$ apt install dateutils
# 根据时间范围过滤日志,可指定时间串格式
$ cat dmesg.log | dategrep -i '%a %b %d %H:%M:%S %Y' '>=2022-06-24T12:00:00 && <now'
[Fri Jun 24 12:15:36 2022] bash (23610): drop_caches: 3
[Fri Jun 24 13:16:16 2022] bash (30249): drop_caches: 3
# 有时我们需要将日志中时间串转换为unix时间缀,方便处理
$ head -n4 access.log
127.0.0.1 - - [07/May/2022:19:00:25 +0800] "GET /health HTTP/1.1" 200 4 3ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - [07/May/2022:19:00:26 +0800] "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - [07/May/2022:19:00:27 +0800] "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - [07/May/2022:19:00:28 +0800] "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
$ head -n4 access.log |dateconv -i '[%d/%b/%Y:%H:%M:%S %Z]' -f '%s' -z 'Asia/Shanghai' -S
127.0.0.1 - - 1651950025 "GET /health HTTP/1.1" 200 4 3ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - 1651950026 "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - 1651950027 "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
127.0.0.1 - - 1651950028 "GET /health HTTP/1.1" 200 4 2ms "-" "curl/7.29.0" "-" "-"
注:Ubuntu中对命令进行了改名,dategrep叫dateutils.dgrep,dateconv叫dateutils.dconv
总结#
这些工具组合起来还是很强大的,这也是为什么即使在公司有日志平台的情况下,依然还是有很多人会去使用命令行!
往期内容#
接口偶尔超时,竟又是JVM停顿的锅!
耗时几个月,终于找到了JVM停顿十几秒的原因
mysql的timestamp会存在时区问题?
真正理解可重复读事务隔离级别
密码学入门
字符编码解惑
[转帖] 拒绝蛮力,高效查看Linux日志文件!的更多相关文章
- 拒绝蛮力,高效查看Linux日志文件!
原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,转载请保留出处. 简介 日常分析问题时,会频繁地查看分析日志,但如果蛮力去查看日志,耗时费力还不一定有效果,因此我总结了在Linux常用的 ...
- Linux下查看alert日志文件的两种方法
--linux下查看alert日志文件的两种方法: --方法1: SQL> show parameter background_dump_dest; NAME TYPE VALUE ------ ...
- 【linux】linux上 查看tomcat日志文件
1.查看实时日志文件 tail -f catalina.out 2.实时查看日志文件 最后n行 tail -n -f catalina.out 3.退出tail命令 ctrl + C 4.翻页查看 日 ...
- [转帖]Linux日志文件utmp、wtmp、lastlog、messages
Linux日志文件utmp.wtmp.lastlog.messages https://www.cnblogs.com/zhuiluoyu/p/6874255.html 1.有关当前登录用户的信息记录 ...
- Linux查看打日志文件
1.如果文件比较小的话,使用vim直接查看,如果文件比较大的话,使用vim会直接卡主 2.如果想要查看正在滚动的日志文件.这个命令可以查看大文件. tail -f file Ctrl+c 终止tail ...
- linux日志文件
linux日志文件 在系统运行正常的情况下学习了解这些不同的日志文件有助于你在遇到紧急情况时从容找出问题并加以解决. /var/log/messages — 包括整体系统信息,其中也包含系统启动期间的 ...
- Linux - 日志文件
Linux日志文件绝大多数存放在/var/log目录,其中一些日志文件由应用程序创建,其他的则通过syslog来创建. Linux系统日志文件通过syslog守护程序在syslog套接字/dev/lo ...
- /var/log目录下的20个Linux日志文件功能详解
如果愿意在Linux环境方面花费些时间,首先就应该知道日志文件的所在位置以及它们包含的内容.在系统运行正常的情况下学习了解这些不同的日志文件有助于你在遇到紧急情况时从容找出问题并加以解决. 以下介绍的 ...
- /var/log目录下的20个Linux日志文件功能详解 分类: 服务器搭建 linux内核 Raspberry Pi 2015-03-27 19:15 80人阅读 评论(0) 收藏
如果愿意在Linux环境方面花费些时间,首先就应该知道日志文件的所在位置以及它们包含的内容.在系统运行正常的情况下学习了解这些不同的日志文件有助于你在遇到紧急情况时从容找出问题并加以解决. 以下介绍的 ...
- Linux - 日志文件简介
Linux日志文件绝大多数存放在/var/log目录,其中一些日志文件由应用程序创建,其他的则通过syslog来创建. Linux系统日志文件通过syslog守护程序在syslog套接字/dev/lo ...
随机推荐
- Programming Abstractions in C阅读笔记:p197-p201
<Programming Abstractions in C>学习第64天,p196-p201总结. 一.技术总结 很难,唯有继续往下看才能让其变容易. 二.英语总结 1.psycholo ...
- 文心一言 VS 讯飞星火 VS chatgpt (18)-- 算法导论4.1 5题
五.使用如下思想为最大子数组问题设计一个非递归的.线性时间的算法.从数组的左边界开始,由左至右处理,记录到目前为止已经处理过的最大子数组.若已知 A[1..j]门的最大子数组,基于如下性质将解扩展为 ...
- 十分钟从入门到精通(上)——OBS权限配置
[摘要]作为公有云的数据底座,大量的应用场景产生的数据都会存储到OBS对象存储服务中,如直播.电商.大数据可视化.机器学习.物联网等.作为公有云的海量存储基础服务, OBS提供了灵活的权限配置功能,解 ...
- 云图说丨带你了解GaussDB(for Redis)双活解决方案
摘要:GaussDB(for Redis)推出了双活解决方案,基于GaussDB NoSQL统一架构,通过两个数据库实例之间的数据同步,达成数据的一致性. 本文分享自华为云社区<[云图说]一张图 ...
- OCR性能优化:从认识BiLSTM网络结构开始
摘要: 想要对OCR进行性能优化,首先要了解清楚待优化的OCR网络的结构,本文从动机的角度来推演下基于Seq2Seq结构的OCR网络是如何一步步搭建起来的. 本文分享自华为云社区<OCR性能优化 ...
- 火山引擎DataLeap数据血缘技术建设实践
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap是火山引擎数智平台VeDI旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理 ...
- 低门槛上手快!火山引擎 VeDI 这样满足数据分析新需求
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 近日,市场研究机构 IDC 发布<2022 年 V2 全球大数据支出指南>. 数据显示,2021 ...
- Solon2 开发之插件,三、插件体外扩展机制(E-Spi)
插件体外扩展机制,简称:E-Spi.用于解决 fatjar 模式部署时的扩展需求.比如: 把一些"业务模块"做成插件包放到体外 把数据源配置文件放到体外,方便后续修改 其中, .p ...
- 你好 Java!Solon v1.10.3 发布
相对于 Spring Boot 和 Spring Cloud 的项目: 启动快 5 - 10 倍. (更快) qps 高 2- 3 倍. (更高) 运行时内存节省 1/3 ~ 1/2. (更少) 打包 ...
- 查看公网出口ip
curl cip.cc curl http://members.3322.org/dyndns/getip curl icanhazip.com curl ident.me curl ifconfig ...