论文笔记之:End-to-End Localization and Ranking for Relative Attributes
End-to-End Localization and Ranking for Relative Attributes
arXiv Paper
摘要:本文提出一种 end-to-end 的属性识别方法,能够同时定位和相对属性的排序(simultaneously localize and rank relative visual attributes)。给定训练图像对,并且对于预测该属性的强度进行排行,我们的目标是训练一个深度神经网络,能够学习一个函数,同时发现图像中每一个属性出现的位置,以及根据对属性预测的强度进行 rank。更要的一点是,仅用的监督信息是 the pairwise image comparisons。
方法框架:
1. 输入:对于训练来说,网络的输入是图像对 (I1, I2)以及对应的标签 L,表明该图相对是否属于集合 E 或者 Q。
(I1, I2)属于 E 表明 I1 and I2 的 ground-truth attribute strength 是相似的;
(I1, I2)属于 Q 表明 I1 的属性强度比 I2 大;
(I2, I1)属于 Q 表明 I2 的属性强度比 I1 大。
对于测试来讲,我们的输入是一张图像 $I_{test}$,我们利用学到的函数(网络权重)来预测属性的强度 $v = f(I_{test})$。
2. 结构:

从上图可以看出,该网络的输入是:两幅图像 image 1 and 2 以及其对应的 label,然后将其输入到孪生网络(Siamese Network)中,该网络包括两个子网络:Spatial Transformer Network 和 Ranker Network。经过这两个网络之后,分别输出其预测 label 的可信度,然后链接一个损失函数,通过此进行网络的更新和回传。
Spatial Transformer Network(STN):直观上来看,为了发现每一个图相对和属性相关的区域,我们可以采用一个 ranking function 不同区域对,选择和 gt 对 匹配的最好的 pair。NIPs 的文章 STNs 给我们提供了一个很好的思路,就借鉴了该网络结构,因其有两个优势:
1. 全差分,可以用 BP 算法来训练;
2. 可以学习进行 translate,crop,rotate,scale,or warp 一张图像,而不需要任何 explicit 的监督来做变换。--> 此处可以考虑借鉴此网络进行多模态图像的配准工作。
本文借鉴该网络结构主要是想用于 ROI region 的获取。STN 的输出可以输入到 ensuing Ranker network中,easing its task。
STN 的网络结构参考下图:

在本文中,我们有三个转换参数,分别是 isotropic scaling (各向同性尺寸变换)s,水平和竖直转移 tx, ty。转移是通过一个 inverse warp 来产生输出image:

训练该网络就是为了得到转换的这 6 个参数。其前5层和 Alexnet 相同,加了一层卷积用于降维,然后是两层 fc,输出6个参数。
下图是随着训练的进行,所得到的图像 patch 的位置变化情况:

可以看出这个过程,其实和 Attention Model 的过程非常相似,也就是说,不断的调整参数,使得bbox 得到的图像 patch就是所需要的 attention region。这个就是进行定位,并且产生图像 patch 的过程。
Ranker Network(RN): RN 将 STN 的输出 以及 原始图像作为输入,也就是 local 和 global information 的组合。将两个图像的feature 组合在一次,经过一个线性层(linear layer),得到一个 score,反应了预测属性的可信度。
3. 定位和排行的损失函数:
我们将输出 v1 and v2 通过一个逻辑函数 P 映射为一个概率 P,优化标准的交叉熵损失函数(the standard cross-entropy loss):
$Rank_{loss}(I_1, I_2) = -L*log(P) - (1-L)*log(1-P)$
其中,如果 (I1,I2)属于Q,则 L = 1,否则 如果(I1, I2)属于 E,则 L = 0.5.
在作者初始的实验当中发现,大规模的转移参数会导致输出的 patch 超出图像的边界,从而导致黑色部分,因为其值全为 0. 为了处理这种情况,本文提出了新的损失函数:
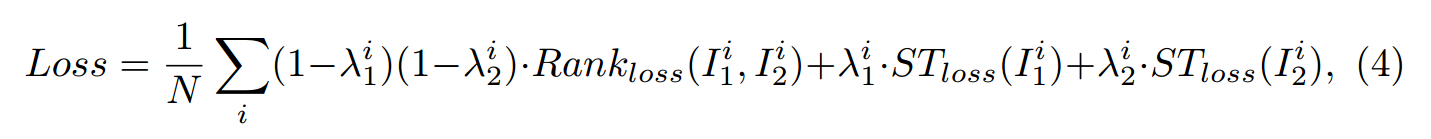
实验效果:


论文笔记之:End-to-End Localization and Ranking for Relative Attributes的更多相关文章
- 论文笔记:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
2014 ICLR 纽约大学 LeCun团队 Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann ...
- 论文笔记之:Active Object Localization with Deep Reinforcement Learning
Active Object Localization with Deep Reinforcement Learning ICCV 2015 最近Deep Reinforcement Learning算 ...
- 论文笔记:CNN经典结构1(AlexNet,ZFNet,OverFeat,VGG,GoogleNet,ResNet)
前言 本文主要介绍2012-2015年的一些经典CNN结构,从AlexNet,ZFNet,OverFeat到VGG,GoogleNetv1-v4,ResNetv1-v2. 在论文笔记:CNN经典结构2 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
随机推荐
- Django中配置用Redis做缓存和session
django-redis文档: http://django-redis-chs.readthedocs.io/zh_CN/latest/# 一.在Django中配置 # Django的缓存配置 CAC ...
- 仿照hibernate封装的一个对数据库操作的jdbc工具类
package project02_Order_management.util; import java.io.IOException; import java.lang.reflect.Field; ...
- UIImage添加滤镜
UIImage *image =[UIImage imageNamed:"]; NSArray *arr = [NSArray arrayWithObjects:@"CISRGBT ...
- Scala系统学习(五):Scala访问修辞符
本章将介绍Scala访问修饰符.包,类或对象的成员可以使用私有(private)和受保护(protected)的访问修饰符进行标注,如果不使用这两个关键字的其中一个,那么访问将被视为公开(public ...
- 畅通工程&&How Many Tables
http://acm.hdu.edu.cn/showproblem.php?pid=1232 #include <iostream> #include <stdio.h> #i ...
- hdu1671Phone List(字典树)
#include <iostream> #include <stdio.h> #include <string.h> #include <stdlib.h&g ...
- 设置pip的默认源
Python在导入第三方模块的时候用设置豆瓣源的方法提高效率,每次设置很麻烦,所以通过下面方法设置默认源,这样就可以直接pip install package,而不用指定源了. [global] ti ...
- Kaggle案例泰坦尼克号问题
泰坦里克号预测生还人口问题 泰坦尼克号问题背景 - 就是那个大家都熟悉的『Jack and Rose』的故事,豪华游艇倒了,大家都惊恐逃生,可是救生艇#### 的数量有限,无法人人都有,副船长发话了l ...
- type Props={};
Components Learn how to type React class components and stateless functional components with Flow Se ...
- Canvas标签基础
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...