splunk LB和scale(根本在于分布式扩展index,search)
Forwarder deployment topologies
You can deploy forwarders in a wide variety of scenarios. This topic provides an overview of some of the most useful topologies that you can create with forwarders. For detailed information on how to configure various deployment topologies, see Consolidate data from multiple hosts.
Data consolidation
Data consolidation is one of the most common topologies, with multiple forwarders sending data to a single Splunk instance. The scenario typically involves universal forwarders forwarding unparsed data from workstations or production servers to a central Splunk Enterprise instance for consolidation and indexing. In other scenarios, heavy forwarders can send parsed data to a central Splunk indexer.
Here, three universal forwarders are sending data to a single indexer:

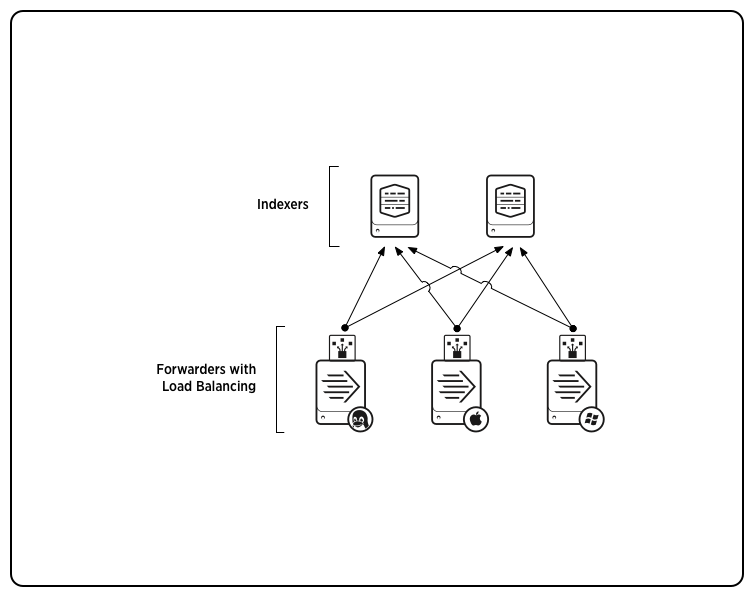
Load balancing
Load balancing simplifies the process of distributing data across several indexers to handle considerations such as high data volume, horizontal scaling for enhanced search performance, and fault tolerance. In load balancing, the forwarder routes data sequentially to different indexers at specified intervals.
Forwarders perform automatic load balancing, in which the forwarder switches receivers at set time intervals. If parsing is turned on (for a heavy forwarder), the switching will occur at event boundaries.
In this diagram, three universal forwarders perform load balancing between two indexers:
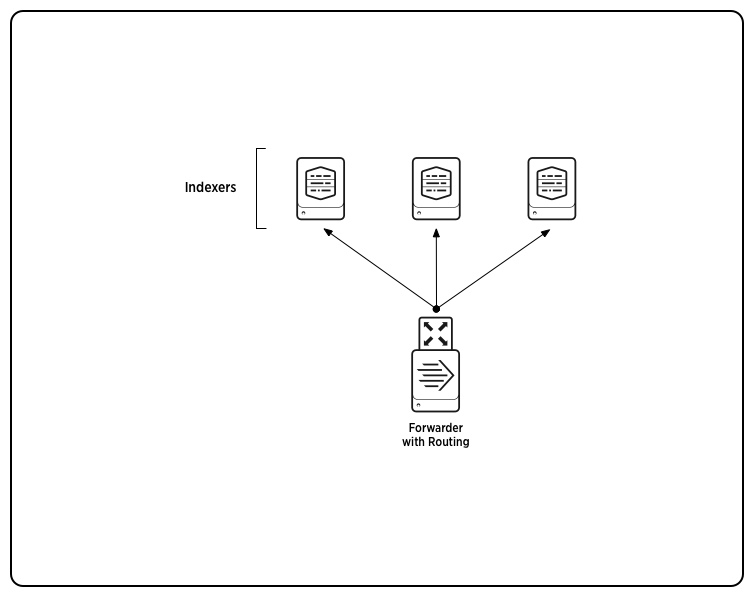
Routing and filtering
In data routing, a forwarder routes events to specific hosts, based on criteria such as source, source type, or patterns in the events themselves. Routing at the event level requires a heavy forwarder.
A forwarder can also filter and route events to specific queues, or discard them altogether by routing to the null queue.
Here, a heavy forwarder routes data to three indexers based on event patterns:
For more information on routing and filtering, see Route and filter data in this manual.
Forwarders and indexer clusters
You can use forwarders to send data to peer nodes in an indexer cluster. A Splunk best practice is to use load-balanced forwarders for that purpose.
This diagram shows two load-balanced forwarders sending data to a cluster:
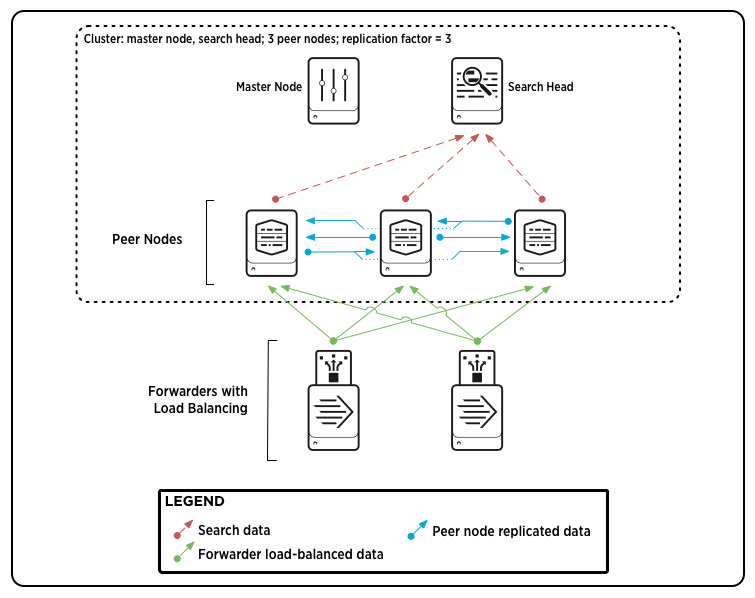
To learn more about forwarders and indexer clusters, see Use forwarders to get your data in Managing Indexers and Clusters of Indexers. To learn more about indexer clusters in general, see About indexer clusters and index replication.
Forward to non-Splunk systems
With a heavy forwarder, you can send raw data to a third-party system such as a syslog aggregator. You can combine this with data routing, sending some data to a non-Splunk system and other data to one or more Splunk instances.
In this diagram, three forwarders route data to two Splunk instances and a non-Splunk system:

For more information on forwarding to non-Splunk systems, see Forward data to third-party systems.
Intermediate forwarding
To handle some advanced use cases, you might want to insert an intermediate forwarder between a group of forwarders and the indexer. In this type of scenario, the originating forwarders send data to a consolidating forwarder, which then forwards the data on to an indexer. In some cases, the intermediate forwarders also index the data.
Typical use cases are situations where you need an intermediate index, either for "store-and-forward" requirements or to enable localized searching. (In this case, you would need to use a heavy forwarder.) You can also use an intermediate forwarder if you have some need to limit access to the indexer machine; for instance, for security reasons.
To enable intermediate forwarding, see Configure an intermediate forwarder.
Scale your deployment with Splunk Enterprise components
In single-instance deployments, one instance of Splunk Enterprise handles all aspects of processing data, from input through indexing to search. A single-instance deployment can be useful for testing and evaluation purposes and might serve the needs of department-sized environments.
To support larger environments, however, where data originates on many machines and where many users need to search the data, you can scale your deployment by distributing Splunk Enterprise instances across multiple machines. When you do this, you configure the instances so that each instance performs a specialized task. For example, one or more instances might index the data, while another instance manages searches across the data.
This manual describes how to distribute Splunk Enterprise across multiple machines. Distributed deployment provides the ability to:
- Scale Splunk Enterprise functionality to handle the data needs for enterprises of any size and complexity.
- Access diverse or dispersed data sources.
- Achieve high availability and ensure disaster recovery with data replication and multisite deployment.
How Splunk Enterprise scales
Splunk Enterprise performs three key functions as it processes data:
1. It ingests data from files, the network, or other sources.
2. It parses and indexes the data.
3. It runs searches on the indexed data.
To scale your system, you can split this functionality across multiple specialized instances of Splunk Enterprise. These instances can range in number from just a few to many thousands, depending on the quantity of data that you are dealing with and other variables in your environment.
In a typical distributed deployment, each instance occupies one of three tiers that correspond to the key processing functions:
- Data input
- Indexing
- Search management
You might, for example, create a deployment with many instances that only ingest data, several other instances that index the data, and one instance that manages searches.
It is possible to combine some of these tiers or configure processing in other ways, but these three tiers are typical of most distributed deployments.
Splunk Enterprise components
Specialized instances of Splunk Enterprise are known collectively as components. With one exception, components are full Splunk Enterprise instances that have been configured to focus on one or more specific functions, such as indexing or search. The exception is the universal forwarder, which is a lightweight version of Splunk Enterprise with a separate executable.
There are several types of Splunk Enterprise components. They fall into two broad categories:
- Processing components. These components handle the data.
- Management components. These components support the activities of the processing components.
This topic discusses the processing components and their role in a Splunk Enterprise deployment. For information on the management components, see "Components that help to manage your deployment."
Types of processing components
There are three main types of processing components:
- Forwarders
- Indexers
- Search heads
Forwarders ingest data. There are a few types of forwarders, but the universal forwarder is the right choice for most purposes. It uses a lightweight version of Splunk Enterprise that simply inputs data, performs minimal processing on the data, and then forwards the data to an indexer. Because its resource needs are minimal, you can co-locate it on the machines that produce the data, such as web servers.
Indexers and search heads are built from Splunk Enterprise instances that you configure to perform the specialized function of indexing or search management, respectively. Each indexer and search head is a separate instance that usually resides on its own machine.
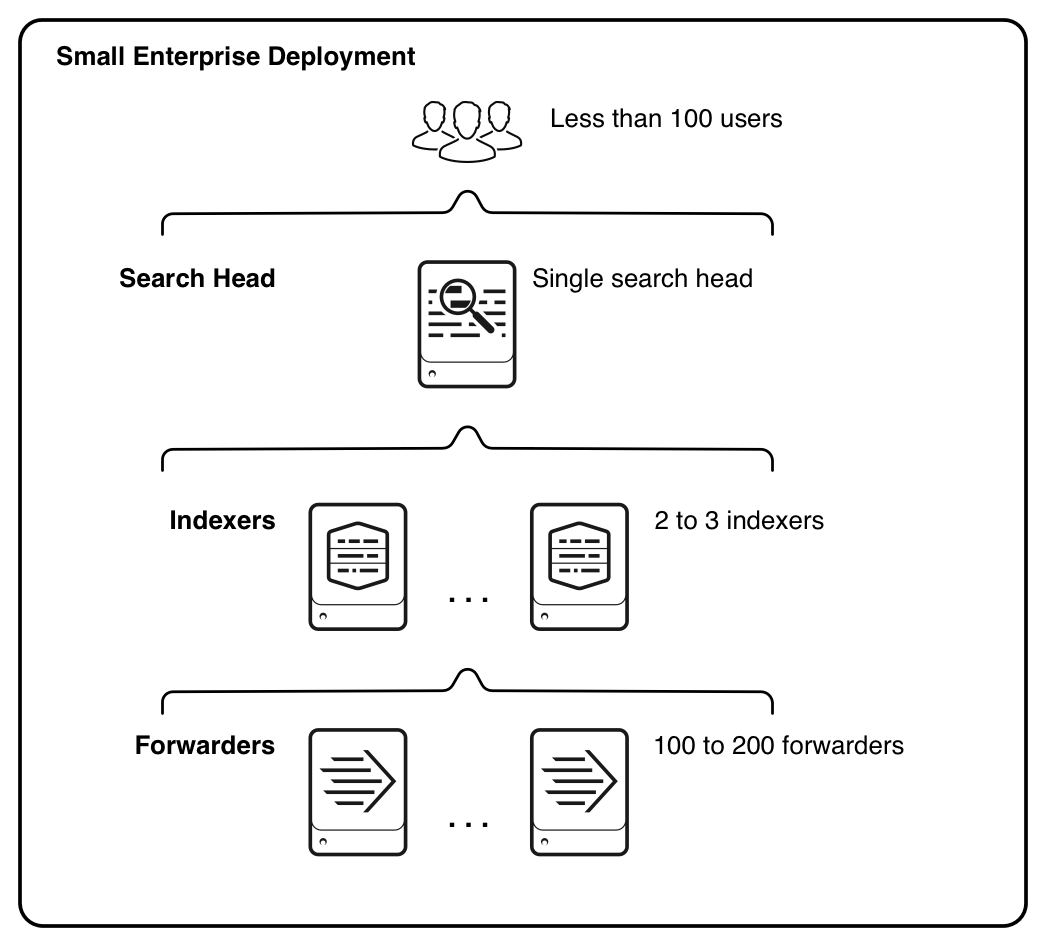
Processing components in action
This diagram provides a simple example of how the processing components can reside on the various processing tiers. It illustrates the type of deployment that might support the needs of a small enterprise.
根本在于分布式扩展index,search
Starting from the bottom, the diagram illustrates the three tiers of processing, in the context of a small enterprise deployment:
- Data input. Data enters the system through forwarders, which consume external data, perform a small amount of preprocessing on it, and then forward the data to the indexers. The forwarders are typically co-located on the machines that are generating data. Depending on your data sources, you could have hundreds of forwarders ingesting data.
- Indexing. Two or three indexers receive, index, and store incoming data from the forwarders. The indexers also search that data, in response to requests from the search head. The indexers reside on dedicated machines.
- Search management. A single search head performs the search management function. It handles search requests from users and distributes the requests across the set of indexers, which perform the actual searches on their local data. The search head then consolidates the results from all the indexers and serves them to the users. The search head provides the user with various tools, such as dashboards, to assist the search experience. The search head resides on a dedicated machine.
To scale your system, you add more components to each tier. For ease of management, or to meet high availability requirements, you can group components into indexer clusters or search head clusters. See "Use clusters for high availability and ease of management."
This manual describes how to scale a deployment to fit your exact needs, whether you are managing data for a single department or a global enterprise, or for anything in between.
splunk LB和scale(根本在于分布式扩展index,search)的更多相关文章
- cassandra mongodb选择——cassandra:分布式扩展好,写性能强,以及可以预料的查询;mongodb:非事务,支持复杂查询,但是不适合报表
Of course, like any technology MongoDB has its strengths and weaknesses. MongoDB is designed for OLT ...
- ElasticSearch Shard——本质上是做分布式扩展,副本对于集群的稳定性有很强的影响
什么是一个Shard? Shard就是一个Lucene Index,参照文章(深入理解Shard和Lucene Index). Index需要多少个Shard? 回答这个问题,我们需要先谈谈节点,一个 ...
- MySQL索引扩展(Index Extensions)学习总结
MySQL InnoDB的二级索引(Secondary Index)会自动补齐主键,将主键列追加到二级索引列后面.详细一点来说,InnoDB的二级索引(Secondary Index)除了存储索引列k ...
- AbpVnext使用分布式IDistributedCache Redis缓存(自定义扩展方法)
AbpVnext使用分布式IDistributedCache缓存from Redis(带自定义扩展方法) 我的依赖包的主要版本以及Redis依赖如下 1:添加依赖 <PackageReferen ...
- 从腾讯QQgame高性能服务器集群架构看“分而治之”与“自治”等分布式架构设计原则
转载:http://space.itpub.net/17007506/viewspace-616852 腾讯QQGame游戏同时在线的玩家数量极其庞大,为了方便组织玩家组队游戏,腾讯设置了大量游戏室( ...
- LB 高可扩展性集群(负载均衡集群)
一.什么是负载均衡 首先我们先介绍一下什么是负载均衡: 负载平衡(Load balancing)是一种计算机网络技术,用来在多个计算机(计算机集群).网络连接.CPU.磁盘驱动器或其他资源中分配负载, ...
- nginx反向代理、负载均衡以及分布式下的session保持
[前言]部署服务器用到了nginx,相比较于apache并发能力更强,优点也比其多得多.虽然我的项目可能用不到这么多性能,还是部署一个流行的服务器吧! 此篇博文主要学习nginx(ingine x)的 ...
- nginx+iis+redis+Task.MainForm构建分布式架构 之 (redis存储分布式共享的session及共享session运作流程)
本次要分享的是利用windows+nginx+iis+redis+Task.MainForm组建分布式架构,上一篇分享文章制作是在windows上使用的nginx,一般正式发布的时候是在linux来配 ...
- 高性能的分布式内存对象缓存系统Memcached
Memcached概述 什么是Memcached? 先看看下面几个概念: Memory:内存存储,不言而喻,速度快,对于内存的要求高,不指出的话所缓存的内容非持久化.对于CPU要求很低,所以常常采 ...
随机推荐
- Python3.x(windows系统)安装matplotlib库
Python3.x(windows系统)安装matplotlib库 cmd命令: pip install matplotlib 执行结果:
- Linux下Tomcat端口、进程以及防火墙设置
Linux下Tomcat端口.进程以及防火墙设置 1,查看tomcat进程: #ps -aux | grep tomcat(或者ps -ef | grep tomcat都行) 可以看到现在运行着两个 ...
- spring MVC @Resource不支持Lazy加载及解决方法
今天迁一系统时发现有个bean使用@Resource注入了另外一个bean,这个被注入的bean是将被deprecated的类,而且只有一两个功能使用到,为了先调整进行测试,增加了@Lazy注解,启动 ...
- ubuntu 更改python3为默认版本
ubuntu 自带两个python版本,一个是python2一个是python3 默认版本是python2的,想要更改ubuntu python3 为默认版本, 只需要两行命令: sudo updat ...
- PHP进程及进程间通信
一.引言 进程是一个具有独立功能的程序关于某个数据集合的一次运行活动.换句话说就是,在系统调度多个cpu的时候,一个程序的基本单元.进程对于大多数的语言都不是一个陌生的概念,作为"世界上最好 ...
- Hive-查询结果导入到 MySQL
step1:add jar /home/chenweidong/lib/hive-contrib-2.1.1-cdh.0.0.jar;add jar /home/chenweidong/lib/mys ...
- VC++实现程序重启的方法(转载)
转载:http://blog.csdn.net/clever101/article/details/9327597 很多时候系统有很多配置项,修改了配置项之后能有一个按钮实现系统重启.所谓重启就是杀死 ...
- trust zone之我见【转】
本文转载自:https://blog.csdn.net/hovan/article/details/42520879 老板交待任务,这个星期我都在研究trust zone的东东,之前有看过代码,但没有 ...
- JavaScript 各种验证收集
filter或者forEach函数,可能是因为你的浏览器还不够新,暂时不支持新标准的函数,你可以使用如下方式自己定义: if (!Array.prototype.forEach) { Array.pr ...
- C#下载歌词文件
前段时间写了一篇c#解析Lrc歌词文件,对lrc文件进行解析,支持多个时间段合并.本文借下载歌词文件来探讨一下同步和异步方法. Lrc文件在网络上随处可见,我们可以通过一些方法获取,最简单的就是别人的 ...