YOLO v2 损失函数源码分析
损失函数的定义是在region_layer.c文件中,关于region层使用的参数在cfg文件的最后一个section中定义。
首先来看一看region_layer 都定义了那些属性值:
layer make_region_layer(int batch, int w, int h, int n, int classes, int coords)
{
layer l = {};
l.type = REGION; l.n = n; // anchors 的个数, 文章中选择为5
l.batch = batch; // batchsize
l.h = h;
l.w = w;
l.c = n*(classes + coords + ); // 输出的通道数
l.out_w = l.w;
l.out_h = l.h;
l.out_c = l.c;
l.classes = classes; // 检测的类别数
l.coords = coords;
l.cost = calloc(, sizeof(float));
l.biases = calloc(n*, sizeof(float)); // anchors的存储位置,一个anchor对应两个值
l.bias_updates = calloc(n*, sizeof(float));
l.outputs = h*w*n*(classes + coords + ); //输出tensor的存储空间大小 13*13*5*(20+4+1)
l.inputs = l.outputs;
l.truths = *(l.coords + ); // ***********注1************
l.delta = calloc(batch*l.outputs, sizeof(float)); // 批量梯度
l.output = calloc(batch*l.outputs, sizeof(float));// 批量输出tensor的存储空间
int i;
for(i = ; i < n*; ++i){
l.biases[i] = .;//anchors的默认值设为0.5
} l.forward = forward_region_layer; // 前向计算函数
l.backward = backward_region_layer;//反向计算函数,这里delta在前向计算函数中获得了,所以该函数为空
#ifdef GPU
l.forward_gpu = forward_region_layer_gpu;
l.backward_gpu = backward_region_layer_gpu;
l.output_gpu = cuda_make_array(l.output, batch*l.outputs);
l.delta_gpu = cuda_make_array(l.delta, batch*l.outputs);
#endif
fprintf(stderr, "detection\n");
srand();
return l;
}
layer parse_region(list *options, size_params params)
{
int coords = option_find_int(options, "coords", );
int classes = option_find_int(options, "classes", );
int num = option_find_int(options, "num", );// 每一个cell对应的anchors个数, 文中num=5 layer l = make_region_layer(params.batch, params.w, params.h, num, classes, coords);
assert(l.outputs == params.inputs); l.log = option_find_int_quiet(options, "log", ); // 是否计算log,这个标志定义了,却未使用
l.sqrt = option_find_int_quiet(options, "sqrt", ); // 输出预测值的w,h是否开方 l.softmax = option_find_int(options, "softmax", ); // 采用softmax分类
l.background = option_find_int_quiet(options, "background", );
l.max_boxes = option_find_int_quiet(options, "max",); //******** 注2 **************
// 图片中最多真实boxes的个数,这个应该和make_region_layer中的30有关
l.jitter = option_find_float(options, "jitter", .);//抖动,cfg中设置为.3
l.rescore = option_find_int_quiet(options, "rescore",); //******** 注3 ************** l.thresh = option_find_float(options, "thresh", .); // .6 大于该值的时候认为包含目标
l.classfix = option_find_int_quiet(options, "classfix", );
l.absolute = option_find_int_quiet(options, "absolute", ); //
l.random = option_find_int_quiet(options, "random", ); // l.coord_scale = option_find_float(options, "coord_scale", ); // 坐标损失的权重,1
l.object_scale = option_find_float(options, "object_scale", ); // 有目标的权重, 5
l.noobject_scale = option_find_float(options, "noobject_scale", ); // 无目标的权重, 1
l.mask_scale = option_find_float(options, "mask_scale", );
l.class_scale = option_find_float(options, "class_scale", ); // 类别权重, 1
l.bias_match = option_find_int_quiet(options, "bias_match",); // 1
// 下面几句未执行
char *tree_file = option_find_str(options, "tree", );
if (tree_file) l.softmax_tree = read_tree(tree_file);
char *map_file = option_find_str(options, "map", );
if (map_file) l.map = read_map(map_file); char *a = option_find_str(options, "anchors", );
if(a){
int len = strlen(a);
int n = ;
int i;
for(i = ; i < len; ++i){
if (a[i] == ',') ++n;
}
for(i = ; i < n; ++i){
float bias = atof(a);
l.biases[i] = bias;
a = strchr(a, ',')+;
}
}
// l.biases存放了anchor的数值
return l;
}
注1: 这里的30应该是限制了每帧图像中目标的最大个数,个人认为应该和 注2 相关,但这里设为了定值
注2: 应该和注1 相关,即再调用make_region_layer方法之前定义,并将后面的30都替换成 l.max_boxes
注3: rescore是一个标志位,推测是regression of confidence score的表示。 当该标志为1的时候,在计算损失时需要回归出被选择的anchor与真实target的iou,否则当该标志为0的时候,直接认为置信度为1。源码中该值在cfg中设置为1.
OK,接下来看一看region_layer 的forward方法是如何实现的。
在看这部分源码之前,先了解一下数据的存储结构,方便看懂源码中寻找各种值得索引。
首先net.truth,及真实target的存储格式 : x,y,w,h,class,x,y,w,h,class,...
然后是*output的存储格式: 维度 w->h>entry->n->batch, 其中entry对应着每个anchor生成的向量维度,文章中就是长度为(4+1+20)的向量,该向量中存储顺序为 box, confidence,classes
void forward_region_layer(const layer l, network net)
{
int i,j,b,t,n;
memcpy(l.output, net.input, l.outputs*l.batch*sizeof(float)); #ifndef GPU
for (b = ; b < l.batch; ++b){
for(n = ; n < l.n; ++n){
int index = entry_index(l, b, n*l.w*l.h, );
activate_array(l.output + index, *l.w*l.h, LOGISTIC);
index = entry_index(l, b, n*l.w*l.h, l.coords);
fprintf(stderr,"background %s \n", l.background)
if(!l.background) activate_array(l.output + index, l.w*l.h, LOGISTIC);
}
}
if (l.softmax_tree){
int i;
int count = l.coords + ;
for (i = ; i < l.softmax_tree->groups; ++i) {
int group_size = l.softmax_tree->group_size[i];
softmax_cpu(net.input + count, group_size, l.batch, l.inputs, l.n*l.w*l.h, , l.n*l.w*l.h, l.temperature, l.output + count);
count += group_size;
}
} else if (l.softmax){
int index = entry_index(l, , , l.coords + !l.background);
softmax_cpu(net.input + index, l.classes + l.background, l.batch*l.n, l.inputs/l.n, l.w*l.h, , l.w*l.h, , l.output + index);
}
#endif memset(l.delta, , l.outputs * l.batch * sizeof(float)); // 梯度清零
if(!net.train) return; // 非训练模式直接返回
float avg_iou = ; // average iou
float recall = ; // 召回数
float avg_cat = ; // 平均的类别辨识率
float avg_obj = ;
float avg_anyobj = ;
int count = ; // 该batch内检测的target数
int class_count = ;
*(l.cost) = ; // 损失
for (b = ; b < l.batch; ++b) { // 遍历batch内数据
if(l.softmax_tree){// 不执行
int onlyclass = ;
for(t = ; t < ; ++t){
box truth = float_to_box(net.truth + t*(l.coords + ) + b*l.truths, );
if(!truth.x) break;
int class = net.truth[t*(l.coords + ) + b*l.truths + l.coords];
float maxp = ;
int maxi = ;
if(truth.x > && truth.y > ){
for(n = ; n < l.n*l.w*l.h; ++n){
int class_index = entry_index(l, b, n, l.coords + );
int obj_index = entry_index(l, b, n, l.coords);
float scale = l.output[obj_index];
l.delta[obj_index] = l.noobject_scale * ( - l.output[obj_index]);
float p = scale*get_hierarchy_probability(l.output + class_index, l.softmax_tree, class, l.w*l.h);
if(p > maxp){
maxp = p;
maxi = n;
}
}
int class_index = entry_index(l, b, maxi, l.coords + );
int obj_index = entry_index(l, b, maxi, l.coords);
delta_region_class(l.output, l.delta, class_index, class, l.classes, l.softmax_tree, l.class_scale, l.w*l.h, &avg_cat);
if(l.output[obj_index] < .) l.delta[obj_index] = l.object_scale * (. - l.output[obj_index]);
else l.delta[obj_index] = ;
l.delta[obj_index] = ;
++class_count;
onlyclass = ;
break;
}
}
if(onlyclass) continue;
}
for (j = ; j < l.h; ++j) {
for (i = ; i < l.w; ++i) {
for (n = ; n < l.n; ++n) {
int box_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, );
//带入 entry_index, 由output tensor的存储格式可以知道这里是第n类anchor在(i,j)上对应box的首地址
box pred = get_region_box(l.output, l.biases, n, box_index, i, j, l.w, l.h, l.w*l.h);
// 在cell(i,j)上相对于anchor n的预测结果, 相对于feature map的值
float best_iou = ;
for(t = ; t < ; ++t){//net.truth存放的是真实数据
// net.truth存储格式:x,y,w,h,c,x,y,w,h,c,....
box truth = float_to_box(net.truth + t*(l.coords + ) + b*l.truths, );
//读取一个真实目标框
if(!truth.x) break;//遍历完所有真实box则跳出循环
float iou = box_iou(pred, truth);//计算iou
if (iou > best_iou) {
best_iou = iou;//找到与当前预测box的最大iou
}
}
int obj_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, l.coords);
// 存储第n个anchor在cell (i,j)的预测的confidence的index
avg_anyobj += l.output[obj_index]; // 有目标的概率 l.delta[obj_index] = l.noobject_scale * ( - l.output[obj_index]);
// *********** 注4 **********
// 所有的predict box都当做noobject,计算其损失梯度,主要是为了计算速度考虑
if(l.background) l.delta[obj_index] = l.noobject_scale * ( - l.output[obj_index]);//未执行
if (best_iou > l.thresh) {//该预测框中有目标
// *********** 注5 ***********
l.delta[obj_index] = ;
} if(*(net.seen) < ){// net.seen 已训练样本的个数
// *********** 注6 ***********
box truth = {}; // 当前cell为中心对应的第n个anchor的box
truth.x = (i + .)/l.w; // cell的中点 // 对应tx=0.5
truth.y = (j + .)/l.h; //ty=0.5
truth.w = l.biases[*n]/l.w; //相对于feature map的大小 // tw=0
truth.h = l.biases[*n+]/l.h; //th=0
delta_region_box(truth, l.output, l.biases, n, box_index, i, j, l.w, l.h, l.delta, ., l.w*l.h);
//将预测的tx,ty,tw,th和上面的box差值存入l.delta
}
}
}
}
for(t = ; t < ; ++t){
box truth = float_to_box(net.truth + t*(l.coords + ) + b*l.truths, );
//对应的真实值,归一化的真实值 if(!truth.x) break;
float best_iou = ;
int best_n = ;
i = (truth.x * l.w);// 类型的强制转换,计算该truth所在的cell的i,j坐标
j = (truth.y * l.h);
//printf("%d %f %d %f\n", i, truth.x*l.w, j, truth.y*l.h);
box truth_shift = truth;
truth_shift.x = ;
truth_shift.y = ;
//printf("index %d %d\n",i, j);
for(n = ; n < l.n; ++n){ // 遍历对应的cell预测出的n个anchor
// 即通过该cell对应的anchors与truth的iou来判断使用哪一个anchor产生的predict来回归
int box_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, );
box pred = get_region_box(l.output, l.biases, n, box_index, i, j, l.w, l.h, l.w*l.h);
// 预测box,归一化的值
//下面这几句是将truth与anchor中心对齐后,计算anchor与truch的iou
if(l.bias_match){ // ********* 注7 ***************
pred.w = l.biases[*n]/l.w; // 因为是和anchor比较,所以直接使用anchor的相对大小
pred.h = l.biases[*n+]/l.h;
}
//printf("pred: (%f, %f) %f x %f\n", pred.x, pred.y, pred.w, pred.h);
pred.x = ;
pred.y = ;
float iou = box_iou(pred, truth_shift);
if (iou > best_iou){
best_iou = iou;
best_n = n;// 最优iou对应的anchor索引,然后使用该anchor预测的predict box计算与真实box的误差
}
}
//printf("%d %f (%f, %f) %f x %f\n", best_n, best_iou, truth.x, truth.y, truth.w, truth.h); int box_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, );
float iou = delta_region_box(truth, l.output, l.biases, best_n, box_index, i, j, l.w, l.h, l.delta, l.coord_scale * ( - truth.w*truth.h), l.w*l.h);
// 注意这里的关于box的损失权重 ************* 注 8 **********************
if(l.coords > ){// 不执行
int mask_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, );
delta_region_mask(net.truth + t*(l.coords + ) + b*l.truths + , l.output, l.coords - , mask_index, l.delta, l.w*l.h, l.mask_scale);
}
if(iou > .) recall += ;// 如果iou> 0.5, 认为找到该目标,召回数+1
avg_iou += iou; //l.delta[best_index + 4] = iou - l.output[best_index + 4];
int obj_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, l.coords);// 对应predict预测的confidence
avg_obj += l.output[obj_index];
l.delta[obj_index] = l.object_scale * ( - l.output[obj_index]);//有目标时的损失
if (l.rescore) { //定义了rescore表示同时对confidence score进行回归
l.delta[obj_index] = l.object_scale * (iou - l.output[obj_index]);
}
if(l.background){//不执行
l.delta[obj_index] = l.object_scale * ( - l.output[obj_index]);
} int class = net.truth[t*(l.coords + ) + b*l.truths + l.coords];// 真实类别
if (l.map) class = l.map[class];//不执行
int class_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, l.coords + );//预测的class向量首地址
delta_region_class(l.output, l.delta, class_index, class, l.classes, l.softmax_tree, l.class_scale, l.w*l.h, &avg_cat);
++count;
++class_count;
}
}
//printf("\n");
*(l.cost) = pow(mag_array(l.delta, l.outputs * l.batch), );//MSEloss
printf("Region Avg IOU: %f, Class: %f, Obj: %f, No Obj: %f, Avg Recall: %f, count: %d\n", avg_iou/count, avg_cat/class_count, avg_obj/count, avg_anyobj/(l.w*l.h*l.n*l.batch), recall/count, count);
}
注4,5: 这两个地方定义了iou的损失
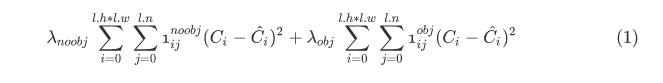
注6: 这段代码主要是计算anchors中没能提供truth的有效预测的那些anchor如何计算损失。有点类似于包含object和不包含object的cell的损失差异,这里没有提供有效预测的anchors则使用scale=0.01的权重计算损失。主要目的是为了在模型训练的前期更加稳定。参见yolo v1中关于object和非object cell的论述
>Also, in every image many grid cells do not contain any object. This pushes the donfidence scores of thos cells towards zero, ofthen overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.
注7: bias_match标志位用来确定由anchor还是anchor对应的prediction来确定用哪个anchor产生的prediction来回归。 如果bias_match=1,即cfg中设置,那么先用anchor与truth box的iou来选择每个cell使用哪个anchor的预测框计算损失。如果bias_match=0的话,使用每个anchor的预测框与truth box的iou选择使用哪一个anchor的预测框计算损失,这里我刚开始纳闷,bias_match=0计算的iou和后面rescore=1里面用的iou不是一样了吗,那delta就一直为0啊?其实这里在选择anchor时计算iou是在中心对齐的情况下计算的,所以和后面rescore计算的iou还是不一样的。
注8: 这里计算了box的梯度,注意loss的权重为 这么设置的好处是缓解box尺寸不平衡问题。
在yolo中有这么一段
> Sum-squred error also equally weights errors in large boxes and small boxes. Our error metric should reflect that small derivations in large boxes matter less than in small boxes. To partially address this we predict the square root of the bounding box width and height instead of the width and height directly.
即yolo v1中使用w和h的开方还和该问题,而在yolo v2中则通过赋值一个和w,h相关的权重函数达到该目的。
3. 所以总结起来,代码中计算的损失包括:其中最后一项只在训练初期使用

源码中计算loss的步骤:
计算包含目标和不包含目标的anchors的iou损失
12800样本之前计算未预测到target的anchors的梯度
针对于每一个target,计算最接近的anchor的coord梯度
计算类别预测的损失和梯度。
YOLO v2 损失函数源码分析的更多相关文章
- 鸿蒙内核源码分析(进程管理篇) | 谁在管理内核资源 | 百篇博客分析OpenHarmonyOS | v2.07
百篇博客系列篇.本篇为: v02.xx 鸿蒙内核源码分析(进程管理篇) | 谁在管理内核资源 | 51.c.h .o 进程管理相关篇为: v02.xx 鸿蒙内核源码分析(进程管理篇) | 谁在管理内核 ...
- Yolov3&Yolov4网络结构与源码分析
Yolov3&Yolov4网络结构与源码分析 从2018年Yolov3年提出的两年后,在原作者声名放弃更新Yolo算法后,俄罗斯的Alexey大神扛起了Yolov4的大旗. 文章目录 1. 论 ...
- 【集合框架】JDK1.8源码分析之Comparable && Comparator(九)
一.前言 在Java集合框架里面,各种集合的操作很大程度上都离不开Comparable和Comparator,虽然它们与集合没有显示的关系,但是它们只有在集合里面的时候才能发挥最大的威力.下面是开始我 ...
- docker 源码分析 四(基于1.8.2版本),Docker镜像的获取和存储
前段时间一直忙些其他事情,docker源码分析的事情耽搁了,今天接着写,上一章了解了docker client 和 docker daemon(会启动一个http server)是C/S的结构,cli ...
- 介绍开源的.net通信框架NetworkComms框架 源码分析
原文网址: http://www.cnblogs.com/csdev Networkcomms 是一款C# 语言编写的TCP/UDP通信框架 作者是英国人 以前是收费的 售价249英镑 我曾经花了 ...
- Java集合源码分析(七)HashMap<K, V>
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- Nmap源码分析(脚本引擎)
Nmap提供了强大的脚本引擎(NSE),以支持通过Lua编程来扩展Nmap的功能.目前脚本库已经包含300多个常用的Lua脚本,辅助完成Nmap的主机发现.端口扫描.服务侦测.操作系统侦测四个基本功能 ...
- Java集合类源码分析
常用类及源码分析 集合类 原理分析 Collection List Vector 扩充容量的方法 ensureCapacityHelper很多方法都加入了synchronized同步语句,来保 ...
- 【JAVA集合】HashMap源码分析(转载)
原文出处:http://www.cnblogs.com/chenpi/p/5280304.html 以下内容基于jdk1.7.0_79源码: 什么是HashMap 基于哈希表的一个Map接口实现,存储 ...
随机推荐
- Linux基础命令---bzcat
bzcat 解压缩被bzip2压缩过的文件,将文件解压到标准输出,此命令只有一个选项-s.该指令对压缩过的二进制文件没有意义,因为二进制文件没有可读性. 此命令的适用范围:RedHat.RHEL.Ub ...
- DeepMind已将AlphaGo引入多领域 Al泡沫严重
DeepMind已将AlphaGo引入多领域 Al泡沫严重 在稳操胜券的前提下,谷歌旗下的AlphaGo还是向柯洁下了战书.4月10日,由中国围棋协会.浙江省体育局.谷歌三方联合宣布,将于5月23日至 ...
- HTML5 多媒体音视频处理
HTML5 多媒体音视频处理 版权声明:未经博主授权,内容严禁转载 ! 音频处理 - audio HTML5 Audio 音频 目前大多数音频是通过哦插件的形式来播放的. 不同浏览器在网页上播放音频的 ...
- 03: shell简单监控脚本
1.1 监控apache web server #! /bin/bash # apache netstat -anpt | grep 80 &> /dev/null if [ $? -e ...
- Python3基础 json.loads 解析json格式的数据,得到一个字典
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- Autotools使用流程【转】
本文转载自:http://blog.csdn.net/scucj/article/details/6079052 手工写Makefile是一件很有趣的事情,对于比较大型的项目,如果有工具可以代劳,自然 ...
- HDU3652 B-number(数位DP)题解
思路: 这里的状态分为3种,无13和末尾的1,无13且末尾为1,有13,然后DFS 等我搞清楚数位DP就来更新Orz 代码: #include<iostream> #include< ...
- 【第十六章】 springboot + OKhttp + String.format
模拟浏览器向服务器发送请求四种方式: jdk原生的Http包下的一些类 httpclient(比较原始,不怎么用了):第一章 HttpClient的使用 Okhttp(好用,推荐) retrofit( ...
- [luogu 2458][SDOI2006]保安站岗
题目描述 五一来临,某地下超市为了便于疏通和指挥密集的人员和车辆,以免造成超市内的混乱和拥挤,准备临时从外单位调用部分保安来维持交通秩序. 已知整个地下超市的所有通道呈一棵树的形状:某些通道之间可以互 ...
- C#学习笔记(十八):数据结构和泛型
数据结构 只有这四种 a.集合:数据之间没有特定的关系 b.线性结构:数据之间有一对一的前后联系 c.树形结构:数据之间有一对多的关系,一个父节点有多个子节点,一个子节点只能有一个父节点 d.图状结构 ...