海量文件查重SimHash和Minhash
SimHash
事实上,传统比较两个文本相似性的方法,大多是将文本分词之后,转化为特征向量距离的度量,比如常见的欧氏距离、海明距离或者余弦角度等等。两两比较固然能很好地适应,但这种方法的一个最大的缺点就是,无法将其扩展到海量数据。例如,试想像Google那种收录了数以几十亿互联网信息的大型搜索引擎,每天都会通过爬虫的方式为自己的索引库新增的数百万网页,如果待收录每一条数据都去和网页库里面的每条记录算一下余弦角度,其计算量是相当恐怖的。
我们考虑采用为每一个web文档通过hash的方式生成一个指纹(fingerprint)。传统的加密式hash,比如md5,其设计的目的是为了让整个分布尽可能地均匀,输入内容哪怕只有轻微变化,hash就会发生很大地变化。我们理想当中的哈希函数,需要对几乎相同的输入内容,产生相同或者相近的hashcode,换句话说,hashcode的相似程度要能直接反映输入内容的相似程度。很明显,前面所说的md5等传统hash无法满足我们的需求。
simhash是locality sensitive hash(局部敏感哈希)的一种,最早由Moses Charikar在《similarity estimation techniques from rounding algorithms》一文中提出。Google就是基于此算法实现网页文件查重的。
海明距离的定义,为两个二进制串中不同位的数量。上述三个文本的simhash结果,其两两之间的海明距离为(p1,p2)=4,(p1,p3)=16以及(p2,p3)=12。事实上,这正好符合文本之间的相似度,p1和p2间的相似度要远大于与p3的。
如何实现这种hash算法呢?以上述三个文本为例,整个过程可以分为以下六步:
1、选择simhash的位数,请综合考虑存储成本以及数据集的大小,比如说32位
2、将simhash的各位初始化为0
3、提取原始文本中的特征,一般采用各种分词的方式。比如对于"the cat sat on the mat",采用两两分词的方式得到如下结果:{"th", "he", "e ", " c", "ca", "at", "t ", " s", "sa", " o", "on", "n ", " t", " m", "ma"}
4、使用传统的32位hash函数计算各个word的hashcode,比如:"th".hash = -502157718
,"he".hash = -369049682,……
5、对各word的hashcode的每一位,如果该位为1,则simhash相应位的值加它的权重(通常是出现的频率);否则减它的权重
6、对最后得到的32位的simhash,如果该位大于1,则设为1;否则设为0
整个过程可以描述为:

按照Charikar在论文中阐述的,64位simhash,海明距离在3以内的文本都可以认为是近重复文本。当然,具体数值需要结合具体业务以及经验值来确定。
利用鸽舍原理在快速查找出位数不同的数目小于等于3的算法的描述如下:
1)先复制原表T为Tt份:T1,T2,….Tt
2)每个Ti都关联一个pi和一个πi,其中pi是一个整数,πi是一个置换函数,负责把pi个bit位换到高位上。
3)应用置换函数πi到相应的Ti表上,然后对Ti进行排序
4)然后对每一个Ti和要匹配的指纹F、海明距离k做如下运算:
a) 然后使用F’的高pi位检索,找出Ti中高pi位相同的集合
b) 在检索出的集合中比较f-pi位,找出海明距离小于等于k的指纹
5)最后合并所有Ti中检索出的结果
代码:
#!/usr/bin/python
#-*- coding:utf-8 -*- from __future__ import division,unicode_literals import sys import re
import hashlib
import collections
import datetime reload(sys) sys.setdefaultencoding('utf-8') import codecs import itertools lib_newsfp_file = sys.argv[1] #读入库中存储的所有新闻
result_file = sys.argv[2] test_news_fp = {}
lib_news_fp = {} bucket = collections.defaultdict(set) offsets = [] def cacu_frequent(list1):
frequent = {}
for i in list1:
if i not in frequent:
frequent[i] = 0
frequent[i] += 1
return frequent def load_lib_newsfp_file():
global lib_news_fp fin = codecs.open(lib_newsfp_file,'r','utf-8')
for line in fin:
lines = line.strip()
if len(lines) == 0:
continue
Arr = lines.split('\t') if len(Arr) < 3:
continue
lib_news_fp[Arr[0]] = Arr[3] def get_near_dups(check_value):
ans = set() for key in get_keys(int(check_value)):
dups = bucket[key]
for dup in dups:
total_value,url = dup.split(',',1)
if isSimilar(int(check_value),int(total_value)) == True:
ans.add(url)
break #与一条重复 退出查找
if ans:
break return list(ans) def ini_Index():
global bucket getoffsets()
print offsets
objs = [(str(url),str(values)) for url,values in lib_news_fp.items()] for i,q in enumerate(objs):
addindex(*q) def addindex(url,value):
global bucket
for key in get_keys(int(value)):
v = '%d,%s' % (int(value),url)
bucket[key].add(v) def deleteindex(url,value):
global bucket
for key in get_keys(int(value)):
v = '%d,%s' %(int(value),url)
if v in bucket[key]:
bucket[key].remove(v) def getoffsets(f = 64 , k = 4):
global offsets offsets = [f // (k + 1) * i for i in range(k + 1)] def get_keys(value, f = 64):
for i, offset in enumerate(offsets):
if i == (len(offsets) - 1):
m = 2 ** (f - offset) - 1
else:
m = 2 ** (offsets[i + 1] - offset) - 1
c = value >> offset & m
yield '%x:%x' % (c , i) def bucket_size():
return len(bucket) def isSimilar(value1,value2,n = 4,f = 64):
ans = 0
x = (value1 ^ value2) &((1 << f) - 1)
while x and (ans <= n):
ans += 1
x &= x - 1
if ans <= n:
return True
return False def load_test_file(): global test_news_fp for line in sys.stdin: features = [] result = line.strip().split('\t') url = result[0]
content = result[2].split()
title = result[1].split()
features.extend(content)
features.extend(title)
total_features = cacu_frequent(features) test_news_fp[url] = build_by_features(total_features) def load_test_newsfp_file(): global test_news_fp for line in sys.stdin:
lines = line.strip()
if len(lines) == 0:
continue
Arr = lines.split('\t') if len(Arr) < 3:
continue
test_news_fp[Arr[0]] = Arr[3] def build_by_features(features,f=64,hashfunc=None):
v = [0]*f
masks = [1 << i for i in range(f+f)]
if hashfunc is None:
def _hashfunc(x):
return int(hashlib.md5(x).hexdigest(),16)
hashfunc = _hashfunc
if isinstance(features,dict):
total_features = features.items()
else:
total_features = features for fea in total_features:
if isinstance(fea,basestring):
h = hashfunc(fea.encode('utf-8'))
w = 1
else:
h = hashfunc(fea[0].encode('utf-8'))
w = fea[1]
for i in range(f):
v[i] += w if h & masks[i+32] else -w
ans = 0 for i in range(f):
if v[i] >= 0:
ans |= masks[i]
return ans
sum = 0
def process():
global test_news_fp
global sum fout = codecs.open(result_file,'w','utf-8') load_lib_newsfp_file()
# load_test_file()
ini_Index()
check_features = test_news_fp.items()
lib_features = lib_news_fp.items()
i = 0
for check_fp in check_features:
# print i
ans = []
ans = get_near_dups(check_fp[1])
if ans:
for url in ans:
output_str = str(check_fp[0])+'\t'+str(url)
fout.write(output_str+'\n')
#break
#print check_fp[0],'is duplicate'
sum = sum + 1 #del test_news_fp[check_fp[0]]
print i i += 1
fout.close() if __name__ == '__main__':
# process()
begin = datetime.datetime.now()
load_test_newsfp_file() # load_test_file()
# getoffsets()
# print offsets
# load_lib_newsfp_file() process() end = datetime.datetime.now() print '耗时:',end - begin,' 重复新闻数:',sum,' 准确率: ', sum/2589
MinHash
1.概述
Jaccard index是用来计算相似性,也就是距离的一种度量标准。假如有集合A、B,那么, 也就是说,集合A,B的Jaccard系数等于A,B中共同拥有的元素数与A,B总共拥有的元素数的比例。很显然,Jaccard系数值区间为[0,1]。
那么对集合A、B,hmin(A) = hmin(B)成立的条件是A ∪ B 中具有最小哈希值的元素也在 ∩ B中。这里
有一个假设,h(x)是一个良好的哈希函数,它具有很好的均匀性,能够把不同元素映射成不同的整数。
所以有,Pr[hmin(A) = hmin(B)] = J(A,B),即集合A和B的相似度为集合A、B经过hash后最小哈希值相
等的概率。
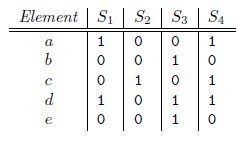
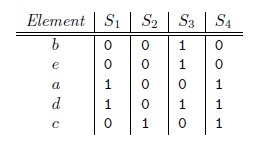
简单粗暴的方法
统计分词后的文本中出现的各个词,直接计算两个文本的jaccard距离。(相同的词出现的越多,文本重复的概率越大。)
#!/usr/bin/python
#-* coding:utf-8 -*- 4 import sys
5 import re
6 import hashlib
7 import collections
8 import datetime
9 import codecs
10
11 reload(sys)
12 sys.setdefaultencoding('utf-8')
13
14 import threading
15 from Queue import Queue
16 queue = Queue()
17 thread_flag_list = [0,0,0,0,0]
18
19 res_file = sys.argv[1]
20
21 news_list = []
22 def load():
23 global news_list
24 for line in sys.stdin:
25 line = line.strip()
26 if len(line) == 0:
27 continue
28 Arr = line.split('\t')
29
30 if len(Arr) < 3:
31 continue
32
33 url = Arr[0]
34 title = Arr[1]
35 content = Arr[2]
36
37 term_list = content.split(' ')
38 term_set = set(term_list)
39 news_list.append([url,term_set])
40
41
42 def calculate(news_f,news_s):
43 set1 = news_f[1]
44 set2 = news_s[1]
45
46 set_join = set1 & set2
47 set_union = set1 | set2
48
49 simi_value = float(len(set_join))/float(len(set_union))
50 return simi_value
51
52 def run_thread(start_id,thread_id):
53 global queue
54 global thread_flag_list
55 news_first = news_list[start_id]
56 for i in range(start_id+1,len(news_list)):
57 news_second = news_list[i]
58 simi_value = calculate(news_first,news_second)
59 if simi_value > 0.8:
60 url1 = news_first[0]
61 url2 = news_second[0]
62 output_str = url1+'\t'+url2+'\t'+str(simi_value)
63 queue.put(output_str)
64 thread_flag_list[thread_id] = 0#标记线程结束
65
66 def process():
67 global queue
68 global thread_flag_list
69 fout = codecs.open(res_file,'w','utf-8')
70 id_max = len(news_list)
71 id_now = 0
72 while True:
73 run_flag = False
74 thread_list = []
75 for i in range(0,len(thread_flag_list)):
76 if thread_flag_list[i] == 0:
77 if id_now == id_max:
continue
79 thread_flag_list[i] = 1
80 print 'now run is:',id_now
81
82 thread = threading.Thread(target=run_thread,args=(id_now,i))
83 thread_list.append(thread)
84
85 id_now = id_now + 1
86 else:
87 run_flag = True
88
89 for thread in thread_list:
90 thread.setDaemon(True)
91 thread.start()
92
93 while not queue.empty():
94 elem = queue.get()
95 print elem
96 fout.write(elem+'\n')
97
98 if run_flag != True and id_now == id_max:
99 break
100
101 fout.close()
102
103 if __name__ == '__main__':
104 load()
105 print 'load done'
106 process()
107
海量文件查重SimHash和Minhash的更多相关文章
- simhash进行文本查重 Simhash算法原理和网页查重应用
simhash进行文本查重http://blog.csdn.net/lgnlgn/article/details/6008498 Simhash算法原理和网页查重应用http://blog.jobbo ...
- 文件查重工具 ultraCompare 和 UltraFinder 用法
UltraCompare 是一款文件内容比较工具,它可以对于文本.文件夹.二进制进行比较.可进行文本模式,文件夹模式以及二进制模式的比较,可对比较的文件.文件夹等进行合并,同步等操作.是进行比较操作的 ...
- 基于hash的文档判重——simhash
本文环境: python3.5 ubuntu 16.04 第三方库: jieba 文件寄于github: https://github.com/w392807287/angelo_tools.git ...
- 【NLP】Python实例:申报项目查重系统设计与实现
Python实例:申报项目查重系统设计与实现 作者:白宁超 2017年5月18日17:51:37 摘要:关于查重系统很多人并不陌生,无论本科还是硕博毕业都不可避免涉及论文查重问题,这也对学术不正之风起 ...
- 【NLP】Python实例:基于文本相似度对申报项目进行查重设计
Python实例:申报项目查重系统设计与实现 作者:白宁超 2017年5月18日17:51:37 摘要:关于查重系统很多人并不陌生,无论本科还是硕博毕业都不可避免涉及论文查重问题,这也对学术不正之风起 ...
- 论文 查重 知网 万方 paperpass
相信各个即将毕业的学生或在岗需要评职称.发论文的职场人士,论文检测都是必不可少的一道程序.面对市场上五花八门的检测软件,到底该如何选择?选择查重后到底该如何修改?现在就做一个知识的普及.其中对于中国的 ...
- 在PHP项目中使用Standford Moss代码查重系统
Standford Moss 系统是斯坦福大学大名鼎鼎的代码查重系统,它可以查出哪些同学提交的代码是抄袭别人的,从而将提交结果拒之门外.它对一切希望使用该系统的人都是开放的,那么在PHP的项目中如何使 ...
- 【实习记】2014-09-01从复杂到简单:一行命令区间查重+长整型在awk中的bug
9月1号,导出sql文件后,想到了awk,但很复杂.想到了用sed前期处理+python排序比较的区间查重法.编写加调试用了约3小时. 9月2号,编写C代码的sql语句过程中,发现排序可以交m ...
- week07 13.3 NewsPipeline之 三News Deduper之 tf_idf 查重
我们运行看结果 安装包sklearn 安装numpy 安装scipy 终于可以啦 我们把安装的包都写在文件里面吧 4行4列 轴对称 只需要看一半就可以 横着看 竖着看都行 数值越接近1 表示越相似 我 ...
随机推荐
- poj3207 Ikki's Story IV - Panda's Trick 2-sat问题
---题面--- 题意:给定一个圈,m条边(给定),边可以通过外面连,也可以通过里面连,问连完这m条边后,是否可以做到边两两不相交 题解: 将连里面和连外面分别当做一种决策(即每条边都是决策点), 如 ...
- Redis 的安装配置介绍
redis 是一个高性能的key-value数据库. redis的出现,很大程度补偿了memcached这类keyvalue存储的不足,在部 分场合可以对关系数据库起到很好的补充作用.它提供了Pyth ...
- 《python核心编程》读书笔记--第18章 多线程编程
18.1引言 在多线程(multithreaded,MT)出现之前,电脑程序的运行由一个执行序列组成.多线程对某些任务来说是最理想的.这些任务有以下特点:它们本质上就是异步的,需要多个并发事务,各个事 ...
- DataXceiver error processing unknown operation src: /127.0.0.1:36479 dst: /127.0.0.1:50010处理
异常信息如下: 2015-12-09 17:39:20,310 ERROR datanode.DataNode (DataXceiver.java:run(278)) - hadoop07:50010 ...
- Shell脚本循环读取文件中的每一行
1.使用for循环 for line in `cat filename` do echo $line done 2.使用for循环 for line in $(cat filename) do ech ...
- Spring Boot 启动报错 Exception in thread "main" java.lang.StringIndexOutOfBoundsException: String index out of range: 37
使用命令 java -jar springBoot.jar 启动项目,结果报错如下: Exception at java.lang.String.substring(String.java:) at ...
- React Mixin
为什么使用 Mixin ? React为了将同样的功能添加到多个组件当中,你需要将这些通用的功能包装成一个mixin,然后导入到你的模块中. 可以说,相比继承而已,React更喜欢这种组合的方式. 写 ...
- Mabatis(2) 全局配置文件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC & ...
- [LeetCode] 接雨水,题 Trapping Rain Water
这题放上来是因为自己第一回见到这种题,觉得它好玩儿 =) Trapping Rain Water Given n non-negative integers representing an eleva ...
- 如何生成Java Key以及sign一个jar
1. 生成Java Key: keytool -genkey -alias mydomain -keyalg RSA -keystore keystore.jks -keysize mydomain ...