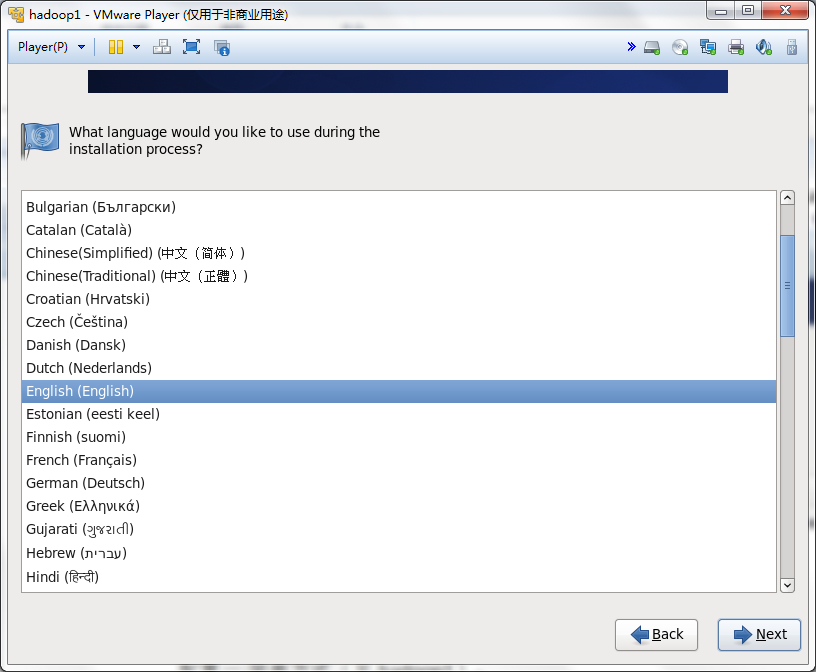
Hadoop1的安装
目前hadoop1的稳定版本是1.2.1,我们以版本1.2.1为例详细的介绍hadoop1的安装,此过程包括OS安装与配置,JDK的安装,用户和组的配置,这些过程在hadoop2也有可能用到。
Hadoop 版本:1.2.1
OS 版本: Centos6.4
Jdk 版本: jdk1.6.0_32
环境配置
|
机器名 |
Ip地址 |
功能 |
|
Hadoop1 |
192.168.124.135 |
namenode, datanode, secondNameNode jobtracker, tasktracer |
|
Hadoop2 |
192.168.124.136 |
Datanode, tasktracker |
|
Hadoop3 |
192.168.124.137 |
Datanode, tasktracker |
OS安装
从Centos官网上下载Centos6.4版本的系统,然后在Vmware Player虚拟机中安装虚拟机
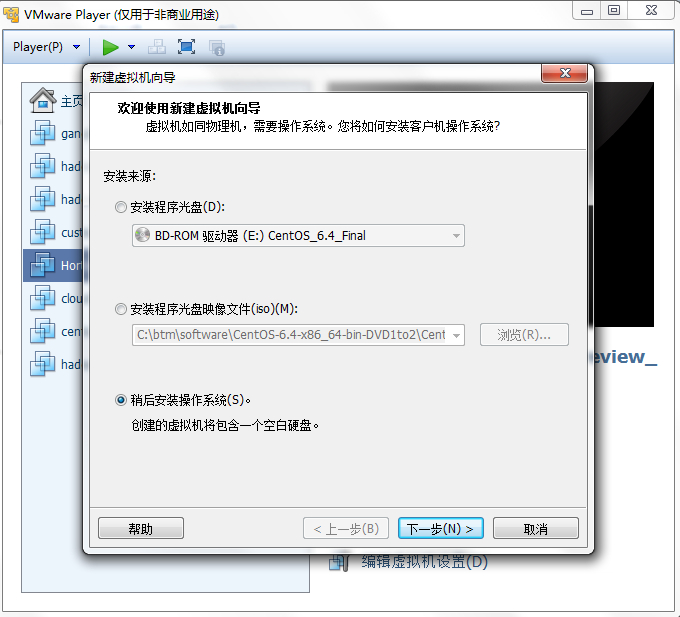
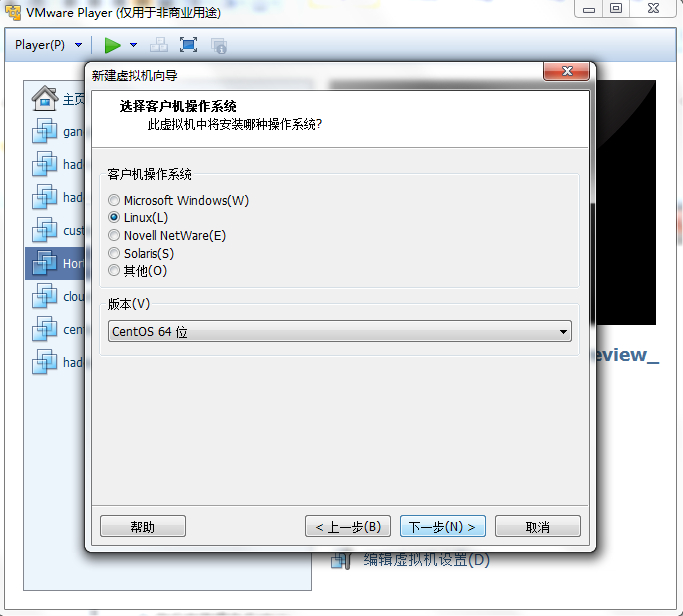
默认的20G空间可能不够用,修改为80G空间
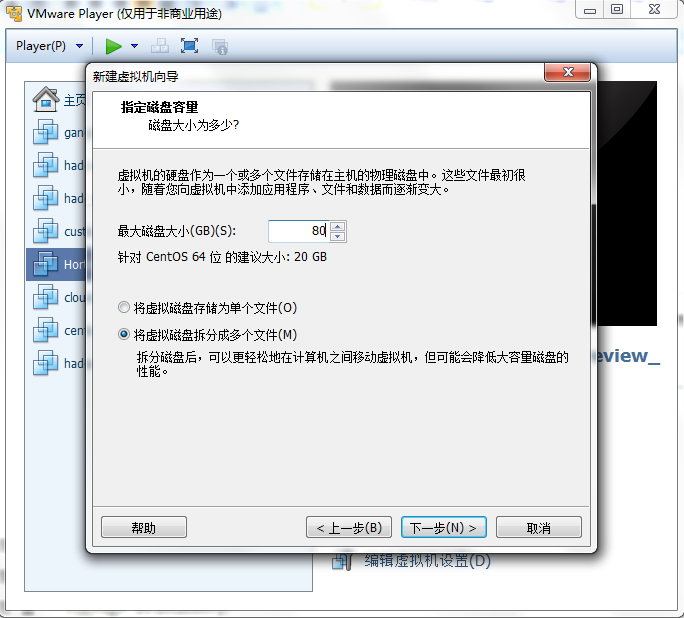
点下一步,可以看出虚拟机的默认配置,1G内存,NAT网卡
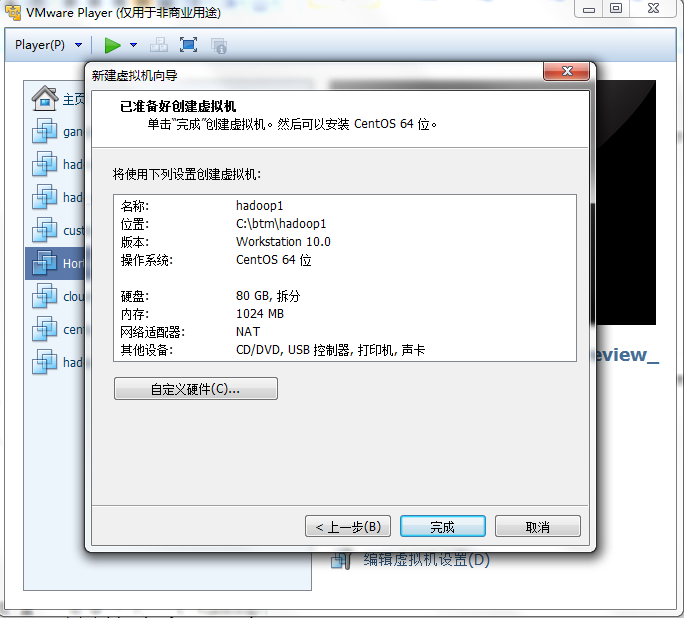
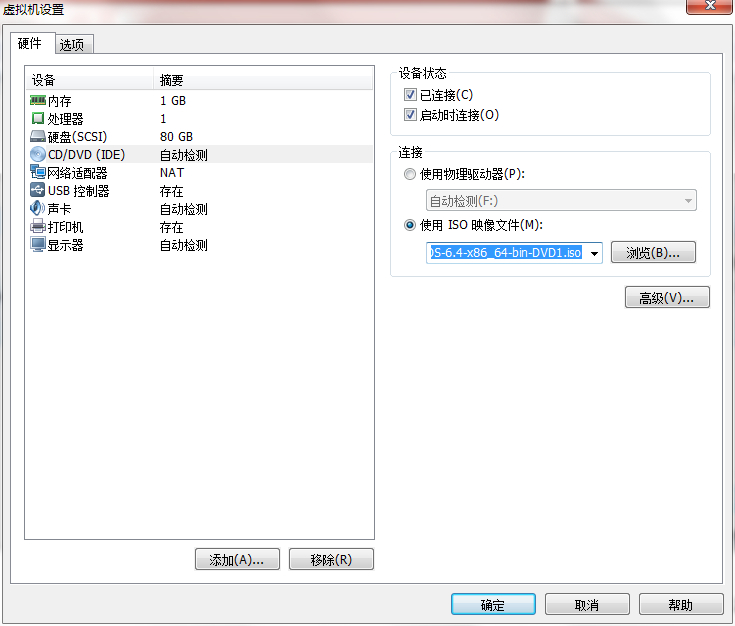
点击播放虚拟机,点击Playerà 可移动设备àCD/DVD(IDE)à设置,在弹出的对话框中设置:使用ISO映像文件,选择Centos系统的文件
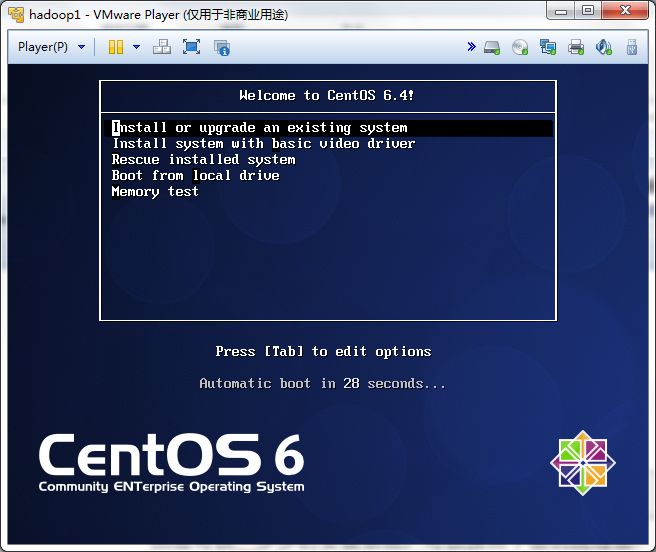
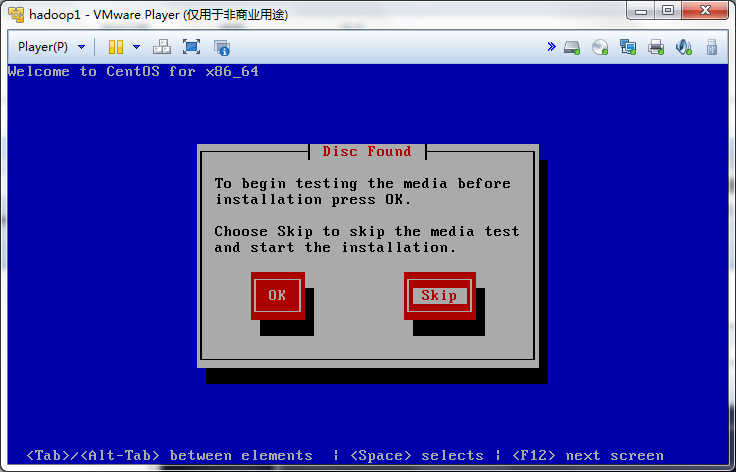
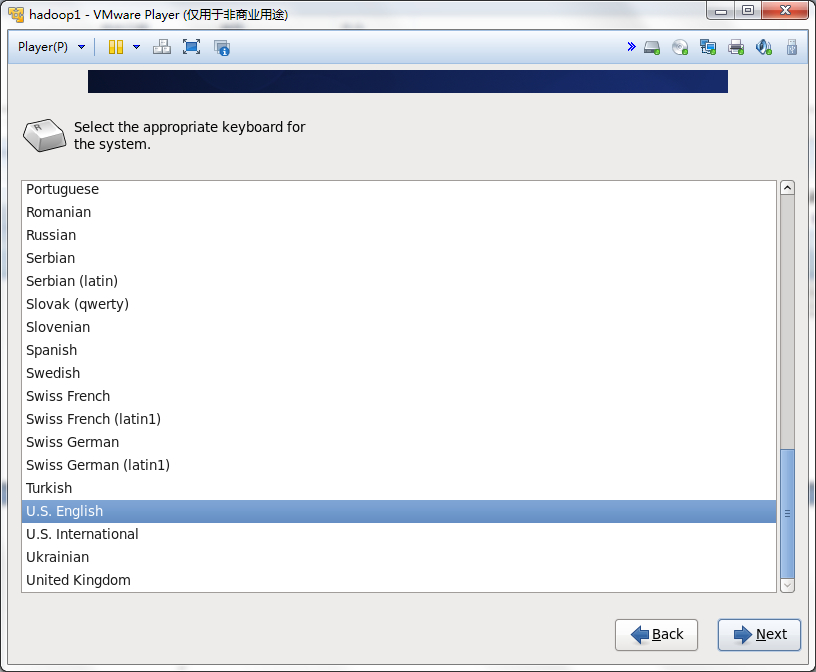
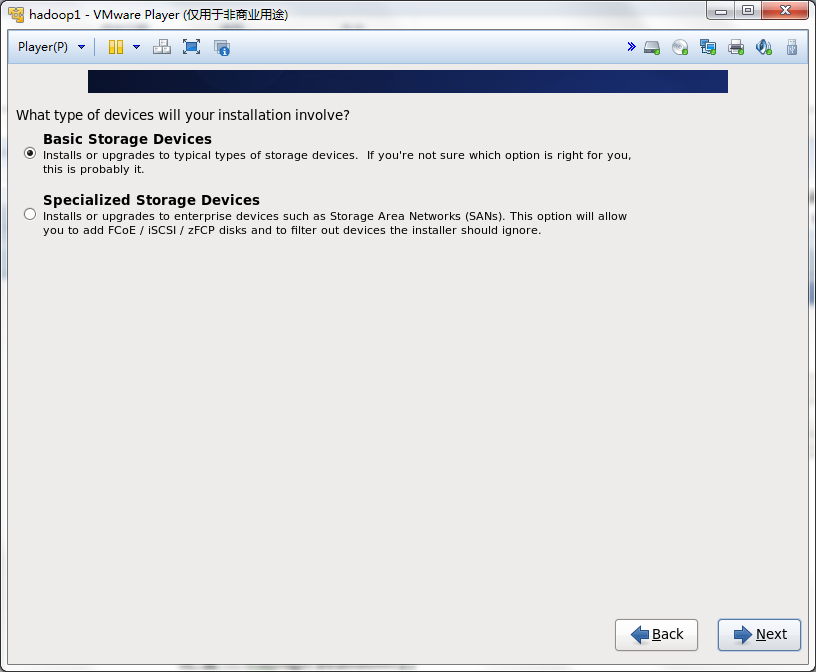
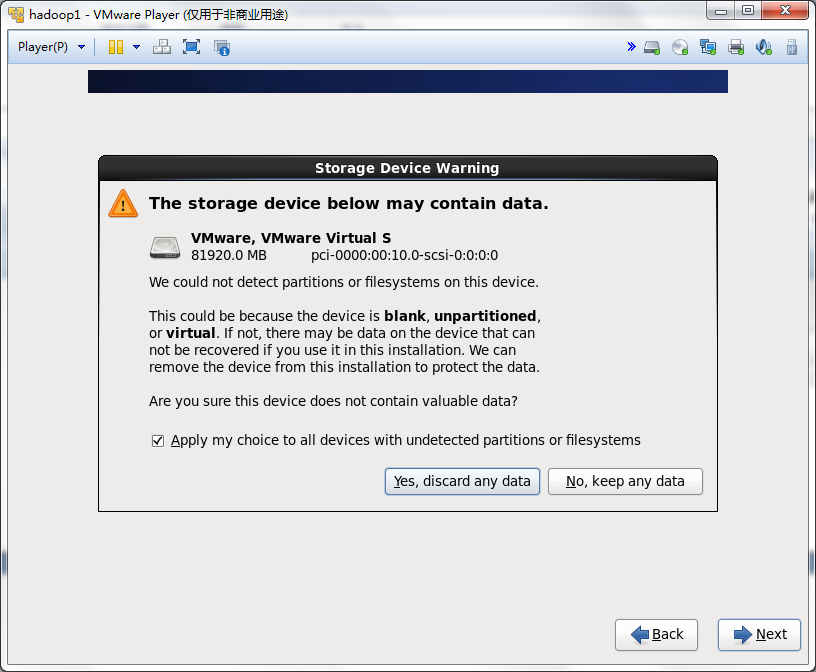
然后一步步的安装系统,可以按照下面的流程做

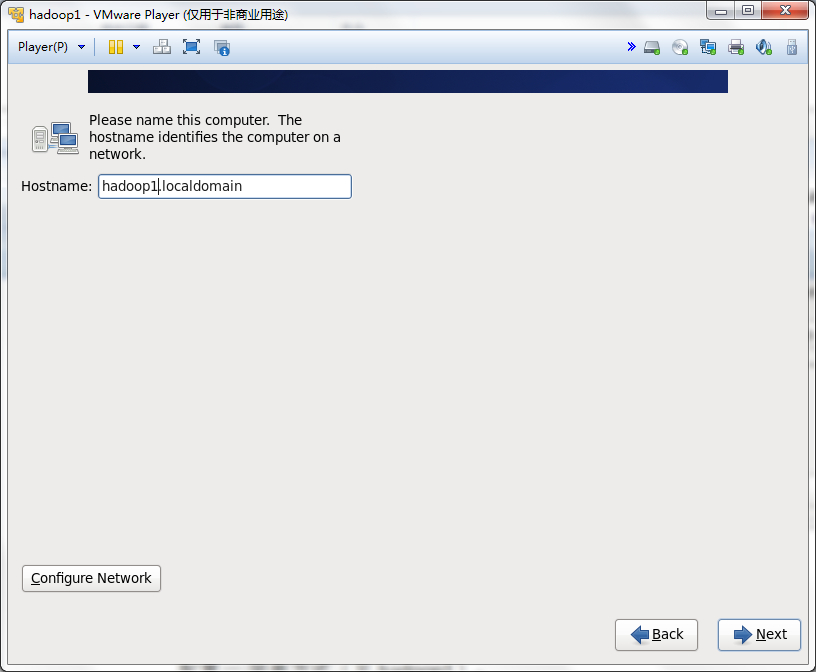
这一步一定要配置Configure Network,否则网卡就不会工作的
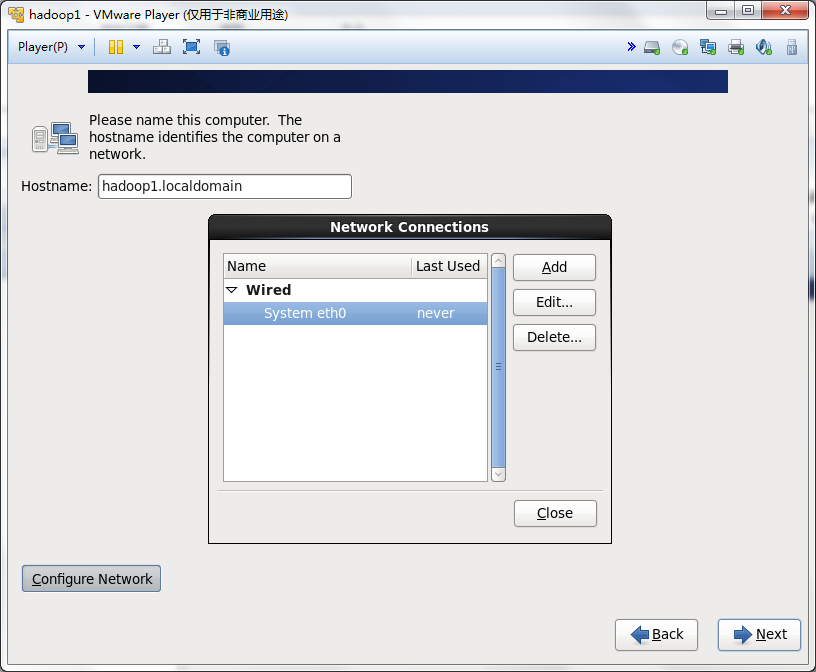
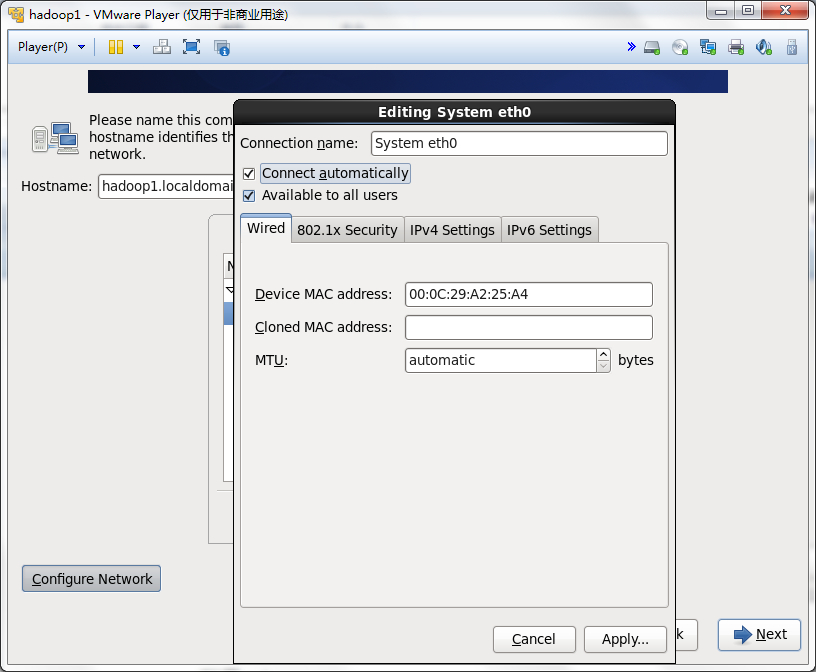
选中Connect automatically
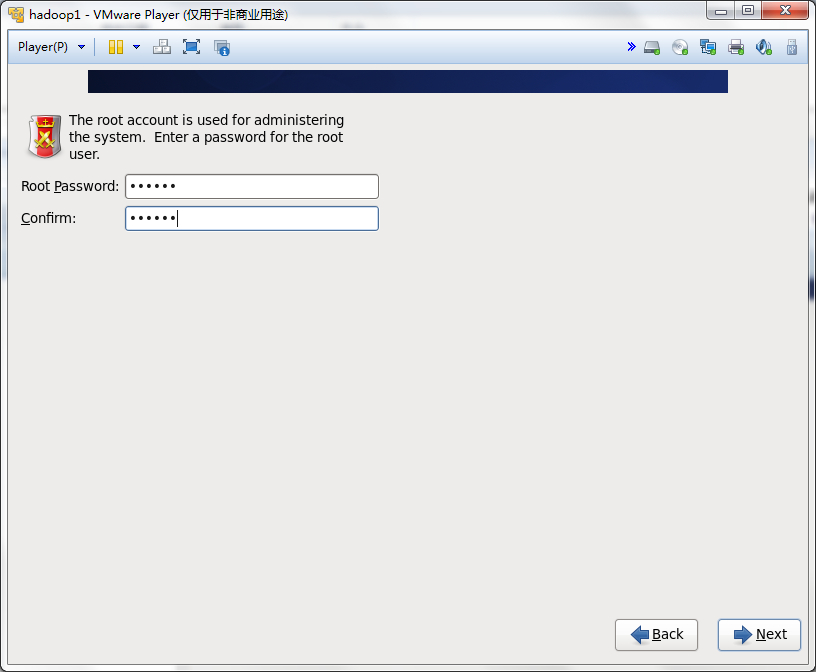
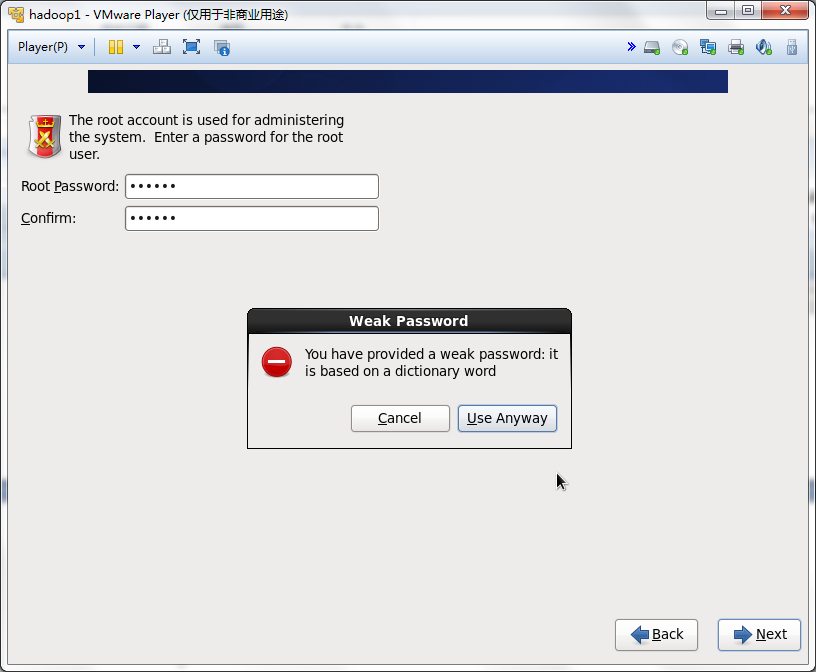
如果密码过短或者比较简单,会出现下面的问题,不用管它,点击Use Anyway
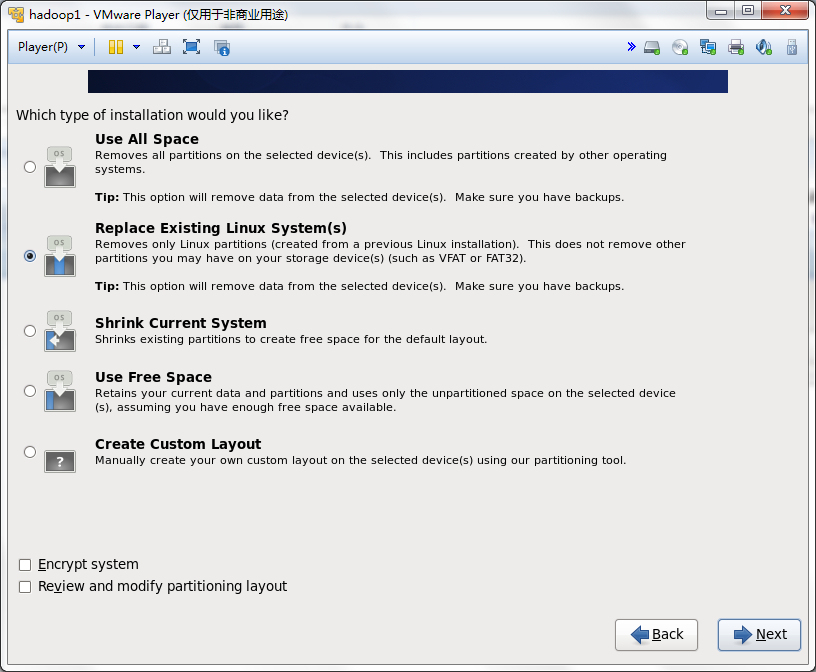
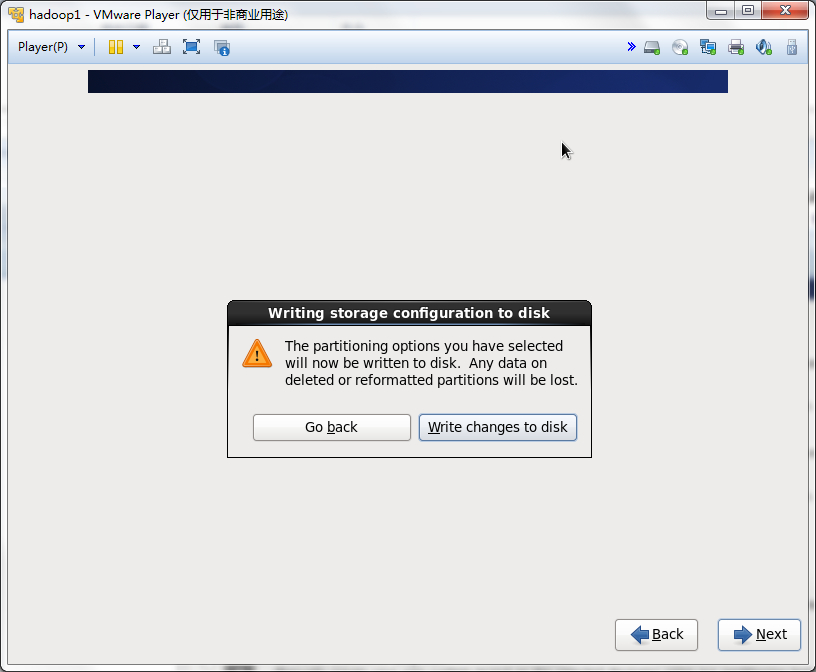
一定要将变化写进磁盘,点击Write changes to disk
在Desktop, Mininal Desktop, Minimal, Basic Server, Database Server, Web Server, Virtual Host, Software Development Workstation 中,选择Minimal可以保证最清洁的hadoop集群。
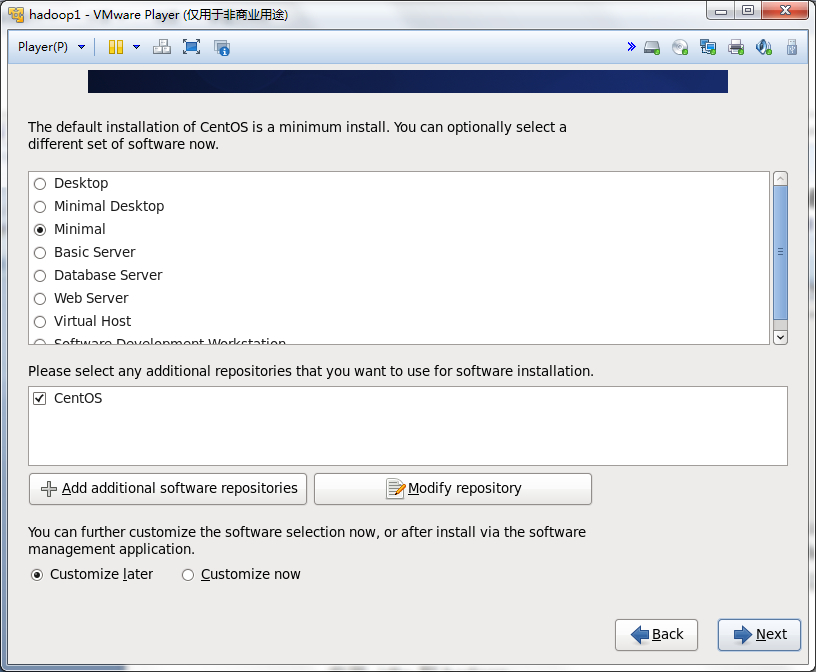
然后启动安装过程,大约需要安装211个rpm包,安装过程大约5分钟
最后重启

按照上面的过程安装hadoop2和hadoop3
配置Centos系统
Selinux
将/etc/sysconfig/selinux 中的SELINUX置为disabled
SELINUX=disabled
Hosts文件
192.168.124.135 hadoop1.localdomain hadoop1
192.168.124.136 hadoop2.localdomain hadoop2
192.168.124.137 hadoop3.localdomain hadoop3
防火墙
Centos默认是开机启动防火墙,我们需要把它关闭,运行下面两个命令
service iptables stop
chkconfig iptables off
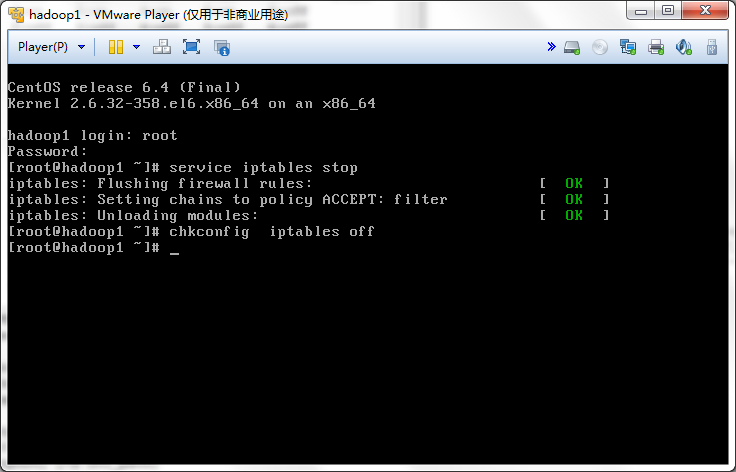
介绍一下防火墙的命令
启动/停止防火墙service iptables start/stop
开机启动/停止防火墙chkconfig iptables off/on
创建用户和组
创建组groupadd hadoop
创建用户useradd -g hadoop hadoop
切换用户su - hadoop
配置ssh
安装ssh客户端yum install openssh-clients
运行ssh-keygen -t rsa 生成一对公钥/私钥
然后在/home/hadoop/.ssh下,可以看到两个文件:id_rsa id_rsa.pub
cp .ssh/id_rsa.pub .ssh/authorized_keys
将hadoop2和hadoop3中的.ssh/id_rsa.pub文件内存添加到hadoop1中的.ssh/authorized_keys
然后通过下面两条命令,可以讲.ssh/authorized_keys复制到hadoop2和hadoop3上
scp .ssh/authorized_keys hadoop@hadoop2:/home/hadoop/.ssh/authorized_keys
scp .ssh/authorized_keys hadoop@hadoop2:/home/hadoop/.ssh/authorized_keys
这样,hadoop1,hadoop2,haoop3都可以用hadoop用户登录到其他机器,并且不需要密码。
测试是否登录成功
ssh hadoop2

安装 jdk和hadoop
使用FileZilla将jdk-6u32-linux-x64.bin和Hadoop-1.2.1上传到hadoop1,hadoop2,hadoop3
赋予jdk执行权限
chown a+x jdk-6u32-linux-x64.bin
运行安装./ jdk-6u32-linux-x64.bin
然后jdk就安装在/home/hadoop/jdk1.6.0_32目录下
测试一下jdk是否安装成功
/home/hadoop/jdk1.6.0_32/bin/java –version

hadoop的安装很简单,只需要解压压缩包即可
tar xzvf hadoop-1.2.1.tar.gz
配置hadoop-1.2.1
进入hadoop-1.2.1目录
cd hadoop-1.2.1
vi conf/hadoop-env.sh,修改jdk目录
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi conf/core-site.xml,需要配置temp目录和hdfs地址
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/repo4/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:9000</value>
</property>
</configuration>
vi conf/hdfs-site.xml,需要配置name node,data node的目录,以及一个replication因子
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/repo4/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/repo4/data</value>
</property>
</configuration>
需要注意的是需要创建如下几个目录
Mkdir –p /home/hadoop/repo4/name
Mkdir –p /home/hadoop/repo4/data
Mkdir –p /home/hadoop/repo4/tmp

vi conf/mapred-site.xml,仅仅只需要配置jobtracker的地址
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://hadoop1:9001</value>
</property>
</configuration>
vi conf/masters
hadoop1
vi conf/slaves
hadoop1
hadoop2
hadoop3
将这些配置文件,复制到hadoop2和hadoop3上
cp -r conf/* hadoop@hadoop2:/home/hadoop/hadoop-1.2.1/conf/
cp -r conf/* hadoop@hadoop3:/home/hadoop/hadoop-1.2.1/conf/
在启动hadoop集群之前,需要格式化namenode
bin/hadoop namenode –format
启动hadoop集群
bin/start-all.sh

可以看出,先启动namenode, data, secondarynamenode, jobtracker, tasktracker
通过jps验证是否启动
在 hadoop1上, 运行jps
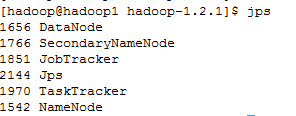
在hadoop2上,运行jps
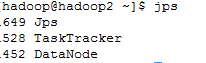
在hadoop3上,运行jps

很显然,NameNode, DataNode, SecondaryNameNode, JobTracker, TaskTracker都已启动了
查看hadoop集群状态
bin/hadoop dfsadmin -report
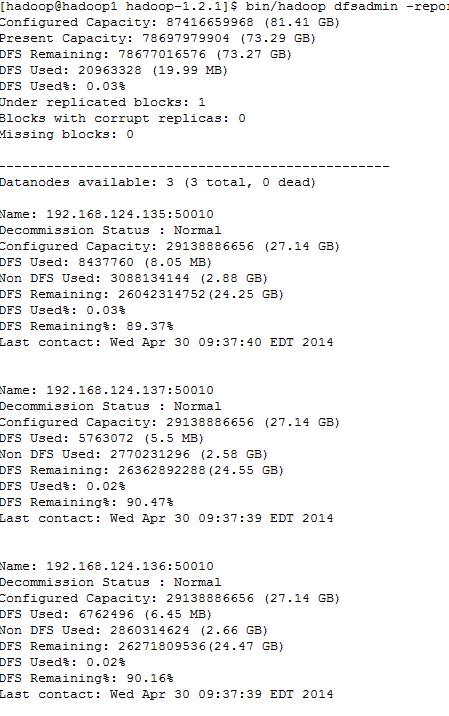
hadoop提供了web页面的接口
在浏览器里输入:http://hadoop1:50070

在浏览器里输入:http://hadoop1:50030
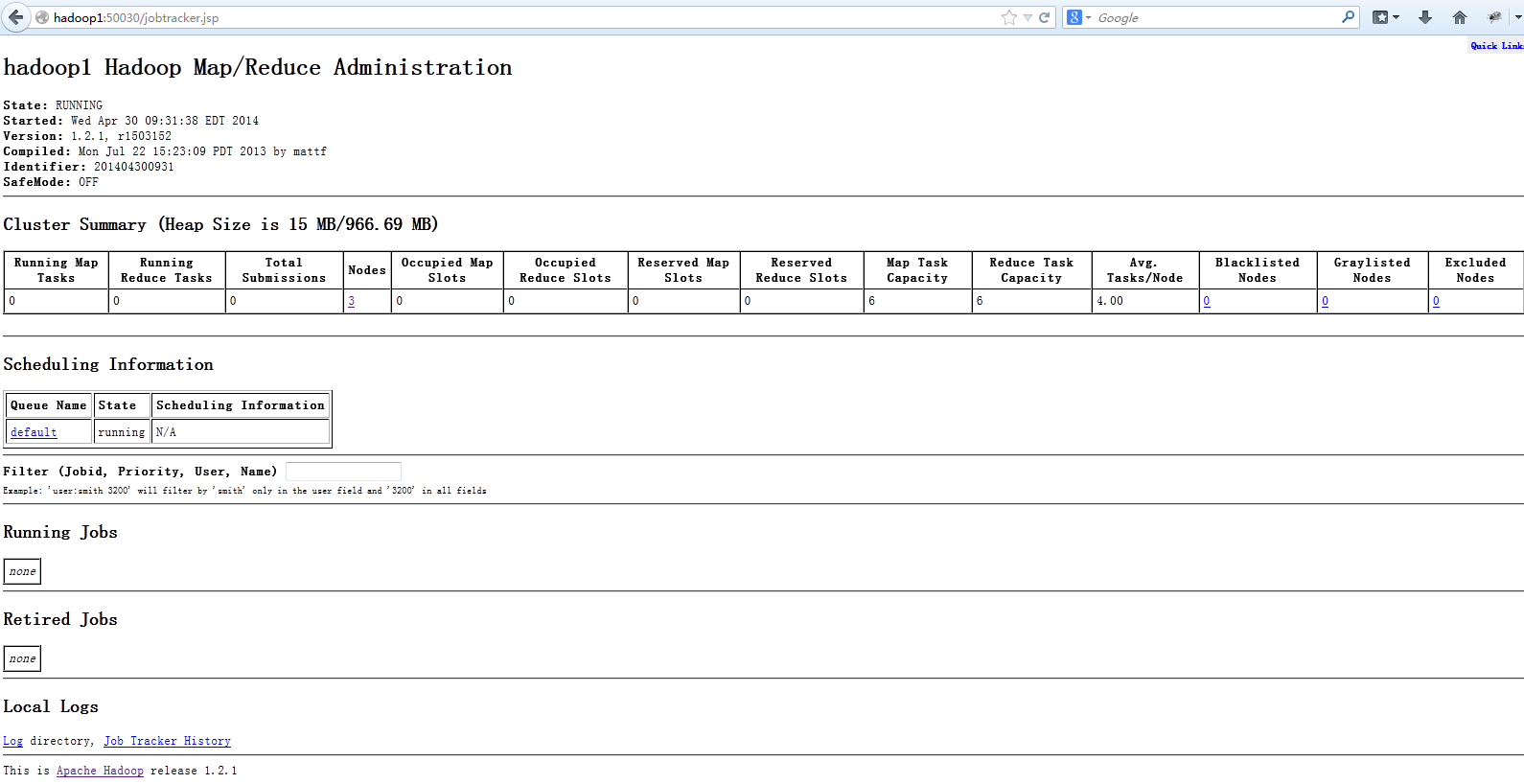
到目前为止hadoop的安装就结束了
测试一下mapred的程序,我们运行hadoop自带的wordcount
创建一个输入目录:
bin/hadoop dfs -mkdir /user/hadoop/input
上传一些文件
bin/hadoop dfs -copyFromLocal conf/* /user/hadoop/input/
看一下文件
bin/hadoop dfs -ls /user/hadoop/input
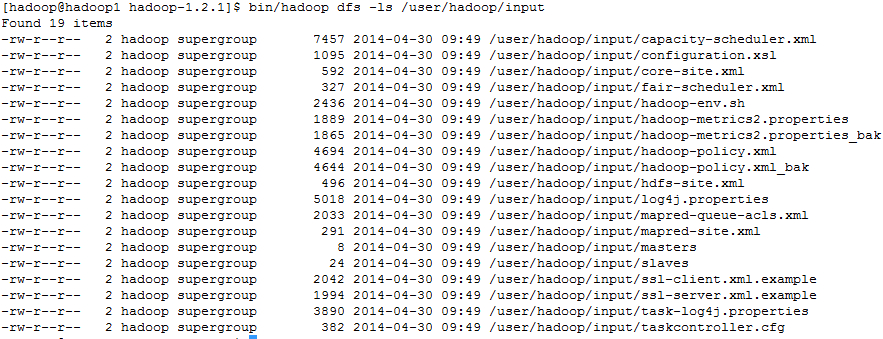
启动mapred程序
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount /user/hadoop/input /user/hadoop/output
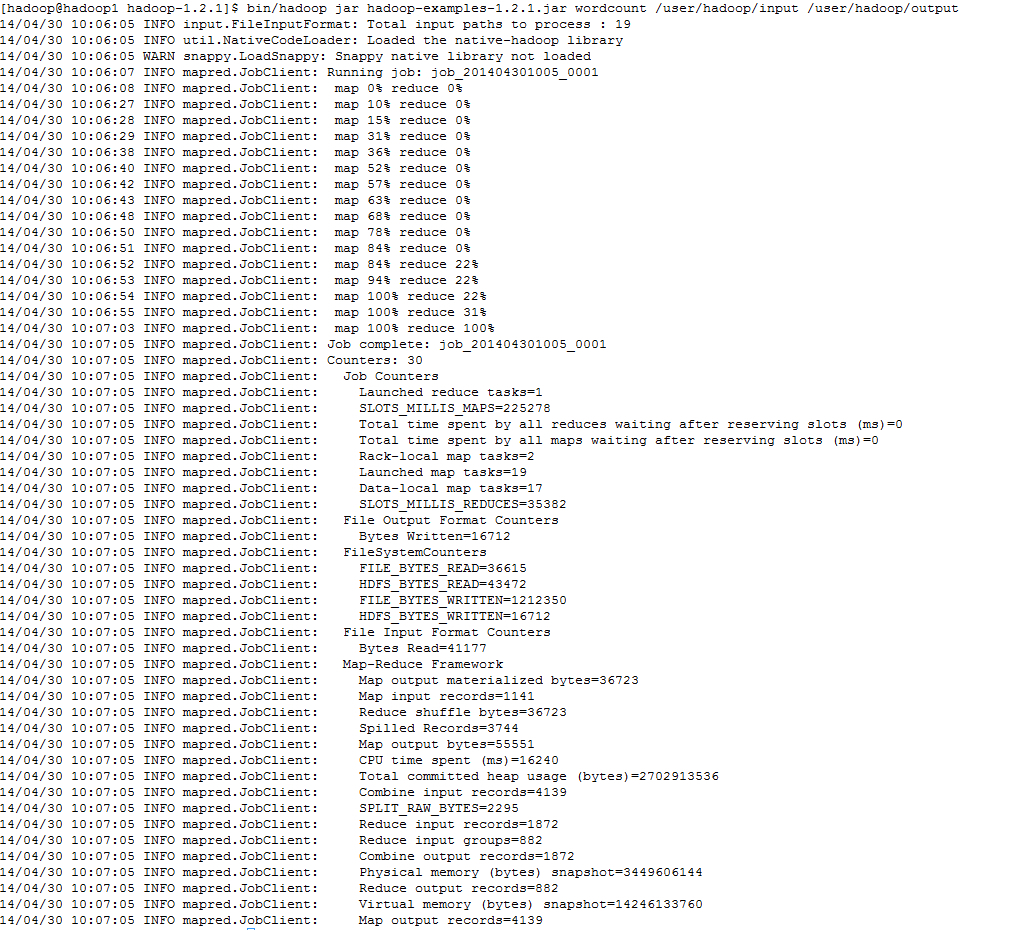
自此,hadoop-1.2.1已经成功安装了,hadoop安装的难点在于要非常熟悉linux系统,了解ssh的配置,防火墙,用户和组。希望大家都能安装好自己的hadoop系统。
Hadoop1的安装的更多相关文章
- hadoop1.X安装
1. 配置主机的名称 master,slave1,slave2 2. 安装JDK: 3. 配置IP与主机名称的映射: 192.168.0.100 master 192.1 ...
- Hadoop1.x安装配置文件及参数说明
一.常用文件及参数说明Core-site.xml 配置Common组件的属性 hdfs-site.xml 配置hdfs参数,比如备份数目,镜像存放路径 Mapred-sit ...
- Hadoop第1~2周练习—Hadoop1.X和2.X安装
练习题目 Hadoop1.X安装 2.1 准备工作 2.1.1 硬软件环境 2.1.2 集群网络环境 2.1.3 安装使用工具 2.2 环境搭建 2.2.1 安 ...
- Coudera-Manager/CDH的安装和部署
由于之前部署的集群采用的是用apache hadoop的方式来实现,但是考虑到运维的成本问题,下面将apache hadoop转换成cloudera cdh.下面主要讲解一下cloudera cdh的 ...
- Hadoop2的简单安装
前面花了很多时间来介绍hadoop1的安装,随着hadoop的发展,hadoop2的应用也越来越普及,hadoop2解决了hadoop1中的很多问题,比如单点故障,namenode容量小的问题. 我们 ...
- hive1.2.1安装步骤(在hadoop2.6.4集群上)
hive1.2.1在hadoop2.6.4集群上的安装 hive只需在一个节点上安装即可,这里再hadoop1上安装 1.上传hive安装包到/usr/local/目录下 2.解压 tar -zxvf ...
- Hadoop安装与配置
Hadoop介绍 上面是官方介绍,翻一下来总结一句话就是:Hadoop是一个高可用,用于分布式处理大规模计算的工具. Hadoop1.2 下载 . Hadoop1.2 安装 1. 安装jDK 2. 配 ...
- 【HIVE】hive的安装与使用教程
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行. 其优点是学习成本低,可以通过 ...
- 八、hive3.1.2 安装及其配置(本地模式和远程模式)
目录 前文 hive3.1.2 安装及其配置(本地模式和远程模式) 1.下载hive包 2.修改其环境变量 3.MySQL配置 Centos7 MySQL安装步骤: 1.设置MySQL源 2.安装My ...
随机推荐
- IntelliJ IDEA15,PhpStorm10,WebStorm11激活破解
此方法可用于激活IntelliJ IDEA15,PhpStorm10,WebStorm11等系列JetBrains产品.仅供参考,请支持正版. 最新方法:http://15.idea.lanyus.c ...
- nginx做正向代理(Centos7,支持http和https)
默认的情况下,使用nginx做正向代理可以解析http请求, 对于诸如baidu.com这样的https请求,nginx默认并不支持,不过我们可以借助第三方模块来实现. 1.先说默认情况下的代理配置 ...
- C# 取时间段年、月、日、季度
DateTime dt = DateTime.Now; //当前时间 DateTime startWeek = dt.AddDays(1 - Convert.ToInt32( ...
- DDD~大话目录
来自:http://www.cnblogs.com/lori/p/3472789.html DDD~DDD从零起步架构说明 DDD~概念中的DDD DDD~microsoft NLayerApp项目中 ...
- MOS管基本构造和工作原理
(一)http://v.youku.com/v_show/id_XMTM2NzcwMjE5Ng==.html (二)http://v.youku.com/v_show/id_XMTM2NzcwMjMw ...
- Lintcode---区间最小数
给定一个整数数组(下标由 0 到 n-1,其中 n 表示数组的规模),以及一个查询列表.每一个查询列表有两个整数 [start, end]. 对于每个查询,计算出数组中从下标 start 到 end ...
- python安装scrapy小问题总结
AttributeError: 'module' object has no attribute 'OP_NO_TLSv1_1'
- Linux 基础学习(第一节)
IP地址的配置 配置临时IP地址 ifconfig etho 192.168.0.91 255.255.255.0 图形化下面配置IP地址: 重启网卡服务: shell环境配置网卡信息 必备的参数 关 ...
- FreeSWITCH小结:呼叫的发起与跟踪
需求描述 虽然现有的FreeSWITCH功能已经很强大,但是很多情况下,为了配合业务上的功能,还需要做一些定制开发. 有一个基本需求是:如何控制fs外呼,并跟踪外呼后的一系列状态. 解决方案 下面我就 ...
- Vivado Logic Analyzer的使用
chipscope中,通常有两种方法设置需要捕获的信号.1.添加cdc文件,然后在网表中寻找并添加信号2.添加ICON.ILA和VIO的IP Core 第一种方法,代码的修改量小,适当的保留设计的层级 ...