Recurrent Neural Networks vs LSTM
Recurrent Neural Network
RNN擅长处理序列问题。下面我们就来看看RNN的原理。
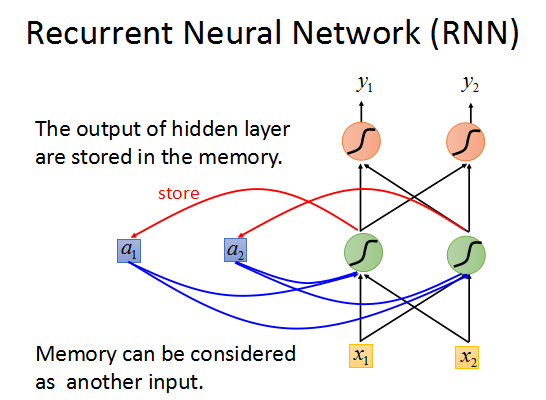
可以这样描述:如上图所述,网络的每一个output都会对应一个memory单元用于存储这一时刻网络的输出值,
然后这个memory会作为下一时刻输入的一部分传入RNN,如此循环下去。
下面来看一个例子。
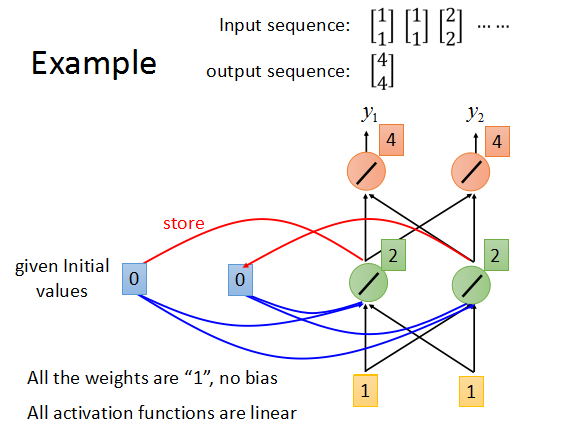
假设所有神经元的weight都为1,没有bias,所有激励函数都是linear,memory的初始值为0.
输入序列[1,1],[1,1],[2,2].....,来以此计算输出。
对输入[1,1],output为1×1+1×1 + 0×1 = 2->2*1+2*1 = 4,最后输出为[4,4],然后将[4,4]存入memory单元,作为下一时刻的部分输入。
最后得到的输出序列是这样的。
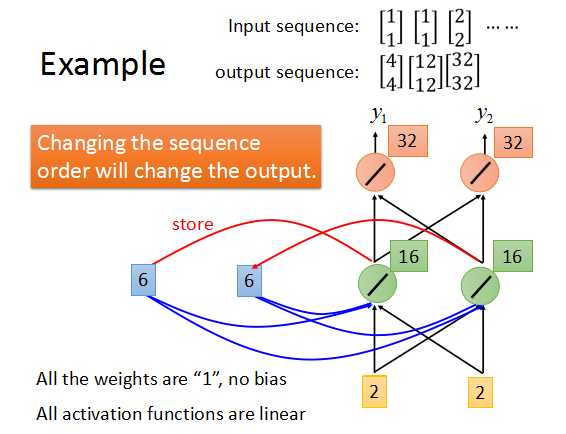
而如果每次输入的序列不同,最后的输出序列也会不一样。
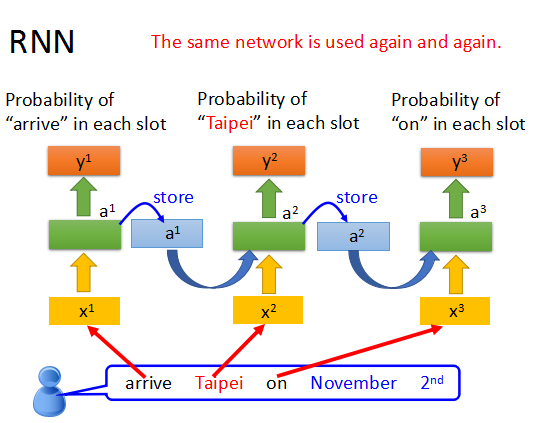
在RNN中,每次都是使用相同的网络结构,只是每次的输入和memory会不同。
这样就使我们在句子分析中,能够辨别同一个词出现在不同位置的时候的不同意思。

当然RNN也可以是深层的网络。这里会有两种不同的RNN类型Elman和Jordan。
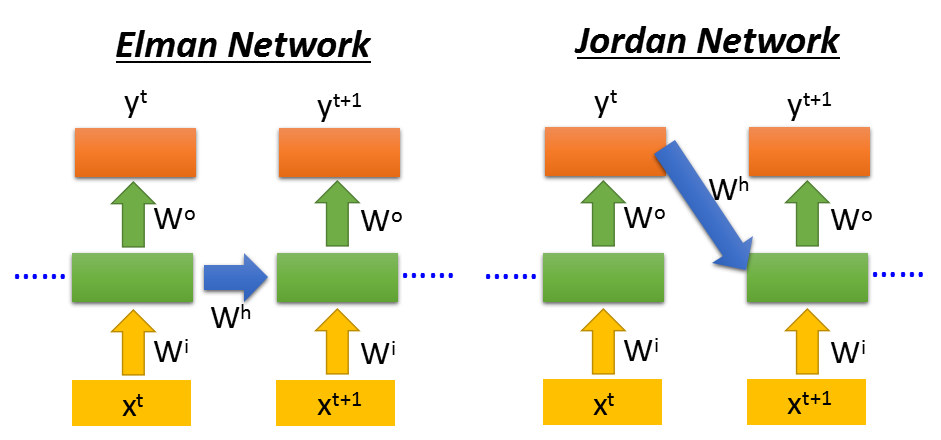
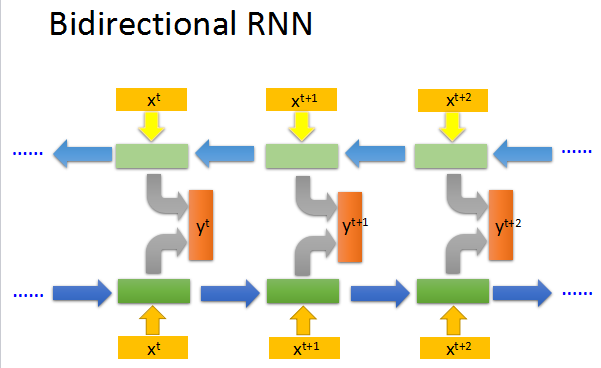
还有双向的RNN,可以兼顾句子的前后部分。
Long Short-term Memory (LSTM)

上面就是一个LSTM的cell的结构,每个cell有4个input, 和1个output。
其中3个input是3个gate。input gate 控制真的的input是否输入网络;
forget gate 控制memory是否要记得之前的时序信息;
output gate 控制是否输出当前的得到的output。

RNN cell的3个gate输入分别是zi,zf,zo,都是标量数据scalar,都需要通过一个激励函数f,f通常是sigmoid,可以将正负无穷的区间压缩到0~1,
模拟gate的开关。input z也是一个scalar,通过g(z)与f(zi)相乘,如果input gate关闭,就是f(zi)=0,那么输入g(z)就没有进入到cell中。
然后继续往下走,有c' = g(x)*f(zi) + c*f(zf), 如果forget gate的f(zf)为1,就相当于记得memory的值,可以加上c,然后将c‘存入到memory中。
真正的输出会是a = h(c')*f(zo),若f(zo)=0,则不输出当前值。
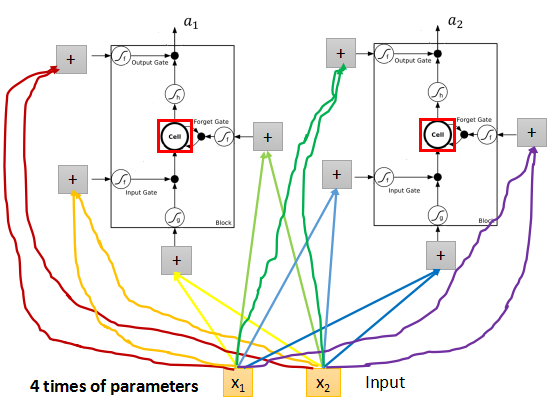
因为在RNN中需要处理4个input,所以参数会是传统前向传播网络的4倍。
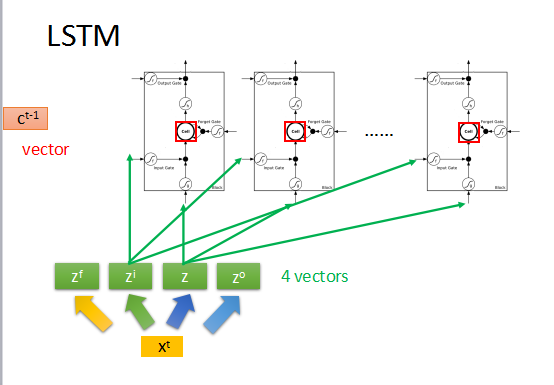
假如上一时刻memory的值为ct-1,是一个vector,输入为xt,然后转化为4个input向量。

首先zi通过activation function与z相乘,zf通过activation function与memory中的ct-1相乘,然后把这两个结果相加,得到新的memory中的值ct,
zo通过activation function与刚刚的输出相乘得到最终的输出yt。
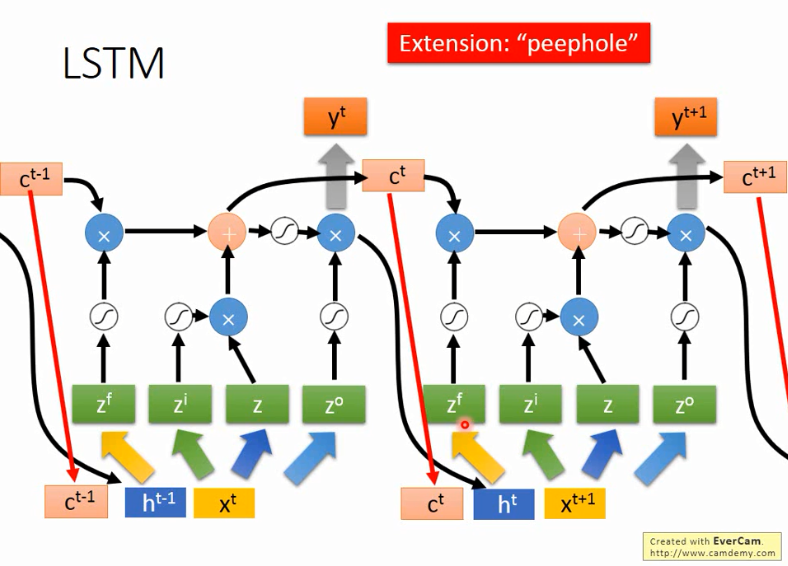
但是通常RNN还会将上一时刻的输出ht和memory中的值ct,再加上输入xt一起作为输入来操控RNN。如上图所示。
以上就是RNN和LSTM的基本原理。
RNN的训练
DNN和CNN都可以使用gradient decent 来训练,RNN也可以。
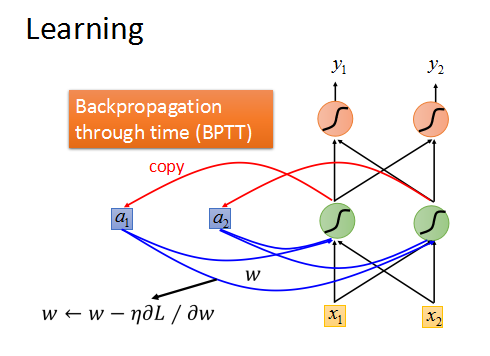
RNN是基于时间序列的Backpropagation through time(BPTT)。
但是训练结果通常是这样的:

RNN的total loss会发生剧烈的震荡,相当不稳定,无法收敛。

这是因为RNN的error surface 很崎岖,有平坦的地方,也有梯度很陡的地方。
这样就是梯度的变化很大,有时候参数w很小的更新就会造成很大的梯度变化,导致loss剧烈震荡。(clipping)
但是造成这种情况的原因并不是我们使用了sigmoid,而且在RNN上使用Relu往往会得到更坏的结果。
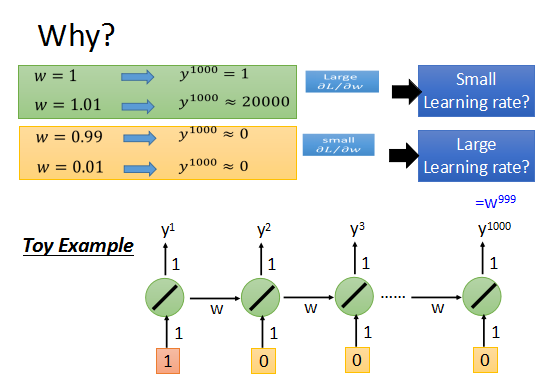
来看一个简单的例子,一个最简单的RNN。
参数w=1时,输出为1;参数w=1.01时,输出为20000.
w的变化对输出值有不同程度的影响,致使learning rate不好选择。
综上所述,RNN的训练很困难。
RNN很难训练,那有什么解决办法吗?那就是LSTM。
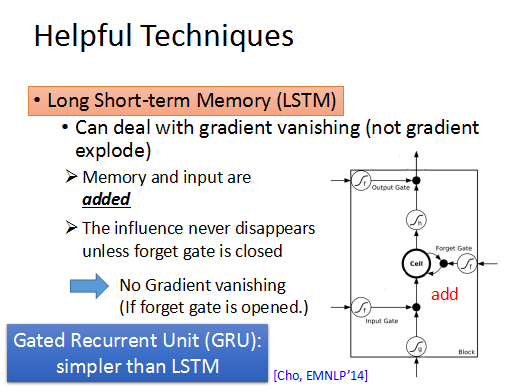
LSTM可以去掉error surface上“平坦”的地方,使梯度不至于特别小,这样可以解决梯度弥散的问题。
训练LSTM的时候,需要将learning rate 调整到很小。
简单的RNN每次训练后都会将memory中的信息覆盖,放入当前结果到memory中。
而LSTM是不一样的,它每次都将memory中的值乘上forget gate的值再加上input,放入cell,所以如果当前的w对memory有影响,那么这个影响将持续存在,在RNN中每个时刻的memory都会被覆盖,w的影响都不再存在。所以只要forget gate 一直打开,memory中的值都会被加到新的input中,而不会消失,这样就解决了gradient valish的问题。
Recurrent Neural Networks vs LSTM的更多相关文章
- Pixel Recurrent Neural Networks翻译
Pixel Recurrent Neural Networks 目前主要在用的文档存放: https://www.yuque.com/lart/papers/prnn github存档: https: ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- Attention and Augmented Recurrent Neural Networks
Attention and Augmented Recurrent Neural Networks CHRIS OLAHGoogle Brain SHAN CARTERGoogle Brain Sep ...
- 第十四章——循环神经网络(Recurrent Neural Networks)(第二部分)
本章共两部分,这是第二部分: 第十四章--循环神经网络(Recurrent Neural Networks)(第一部分) 第十四章--循环神经网络(Recurrent Neural Networks) ...
- 循环神经网络(Recurrent Neural Networks, RNN)介绍
目录 1 什么是RNNs 2 RNNs能干什么 2.1 语言模型与文本生成Language Modeling and Generating Text 2.2 机器翻译Machine Translati ...
- 《转》循环神经网络(RNN, Recurrent Neural Networks)学习笔记:基础理论
转自 http://blog.csdn.net/xingzhedai/article/details/53144126 更多参考:http://blog.csdn.net/mafeiyu80/arti ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- (zhuan) Attention in Long Short-Term Memory Recurrent Neural Networks
Attention in Long Short-Term Memory Recurrent Neural Networks by Jason Brownlee on June 30, 2017 in ...
- 转:RNN(Recurrent Neural Networks)
RNN(Recurrent Neural Networks)公式推导和实现 http://x-algo.cn/index.php/2016/04/25/rnn-recurrent-neural-net ...
随机推荐
- 更轻更快的Vue.js 2.0与其他框架对比(转)
更轻更快的Vue.js 2.0 崭露头角的JavaScript框架Vue.js 2.0版本已经发布,在狂热的JavaScript世界里带来了让人耳目一新的变化. Vue创建者尤雨溪称,Vue 2.0 ...
- Poj1426
Find The Multiple Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 25721 Accepted: 106 ...
- sql 存储过程,最简单的添加和修改
数据库表结构 <1>新增数据,并且按照"name" 字段查询,如果重复返回“error”=-100 ,如果成功返回ID,如果失败ID=0 USE [数据库]GOSET ...
- k8s更新Pod镜像
实际使用k8s中,如果使用RC启动pod可以直接使用滚动更新进行pod版本的升级,但是我们使用的情况是在pod里面启动有状态的mysql服务,没有和RC进行关联,这样更新的时候只能通过 更新pod的配 ...
- 我的Android进阶之旅------>解决Android Studio全局搜索搜不到结果的问题
1.问题描述 今天使用Android Studio时,想通过使用快捷键Ctrl+Shift+F来进行全局搜索指定字符串,如下图所示:想搜索字符串"码农偷懒了", 打开string. ...
- subprocess 模块 与终端相互交互
import subprocess ''' sh-3.2# ls /Users/egon/Desktop |grep txt$ mysql.txt tt.txt 事物.txt ''' #1 Linux ...
- App doesn't auto-start an app when booting the device in Android
From Android 3.1, newly installed apps are always put into a "stopped" state and the only ...
- python代码编辑器PyCharm快捷键补充
个人觉得特别有用的: 替换:Ctrl+R 删除当前行 CTRY Y: 复制当前行:Ctrl+D ALT F7: 查找哪些地方使用了选中的方法. ALT UP: 移到上一个方法 ALT DOWN: 移到 ...
- I2C通信
项目之前研究了I2C通信协议的实现,完成FPGA对视频解码芯片SAA7111A的初始化配置,设计实现了I2C主机对从机(SAA7111A)32个寄存器的写操作,因此只简单实现了I2C的写时序. 这次重 ...
- lamp中的Oracle数据库链接
lamp一键安装包: https://lnmp.org/install.html 在CentOS 6.7 64位安装PHP的PDO_OCI扩展 Installing PDO_OCI extension ...