大数据框架-Mapreduce过程
1、Shuffle
[从mapTask到reduceTask: Mapper -> Partitioner ->Combiner -> Sort ->Reducer]
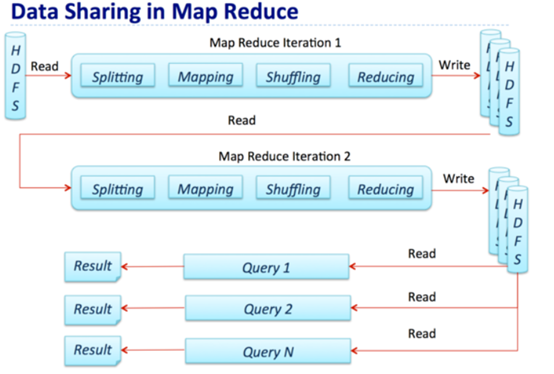
mapper对job任务进行键值对构建并写入环形内存缓冲区[缓冲区满了,map停止直到全写入磁盘],大小100MB(io.sort.mb),一旦达到0.8(io.sort.spill.percent)读入量,即将内存内容经过partitioner分区和sort排序,和combiner合并写入到磁盘一个溢写出文件目录下(mapred.local.dir)。当数据读取完成,将磁盘所有溢出文件合并成一个大文件(同样是经过分区和排序后的文件)。将映射关系提交给AppMaster。
reducer通过心跳机制到AppMaster获取映射关系,再通过Http方式得到文件分区,不同区号文件进入不同reducer,再合并排序进行reduce处理。
Mapper:输出键值对集合(函数setup、map、cleanup、run);
Partitioner:分区,并确保分区号大于或等于reducer的个数。对Mapper结果进行计算确定交给哪个reducer来计算;
Combiner:在map端执行减少传输到reducer的数据量,看作本地的reducer,实现本地key的归并;但combiner不能改变key/value的类型,适用于不影响最终结果场景(累加、最大值);
Sort:按照key值排序。
2、hadoop序列化类型(全都继承Writable)
Text:类似于java中的String
基础Writable对象(IntWritable\LongWritable\ BooleanWritable\ ByteWritable\...)
自定义序列化对象
(实现writable接口;
同时实现序列化函数write和反序列化函数readFiles,但写和读顺序和类型要一致;
重写tostring方法,否则输出结果为类全名+hascode值
需要无参构造方法)
3、MapReduce任务实现流程
Client将JAR包信息发送到RM(PRC通信)
RM返回一个jar包存储路径(固定)和一个jobID
Client对路径进行拼接,通过FileSystem将jar包写入到hdfs中(默认情况下jar包写10份)
Client再将jobID,jar包地址,其他配置发送给RM
RM将任务放入调度器(默认先进先出),NM通过心跳机制获取Mapreduce任务,在HDFS上下载JAR包,启动子进程运行任务
(1)、具体执行过程如下:

函数中主体为submit(),先进行connect(),再使用submitter进行任务调度。
A.
初始化Job持有的cluster对象引用(cluster引用中持有ClientProtocol对象引用)。
Ps: ClientProtocol:RPCserver的代理对象,也可以理解为RM进程对象)。定义了客户端与nameNode间的接口,客户端对文件系统的所有操作都需要通过这个接口,同时客户端读、写文件等操作也需要先通过这个接口与NamenodeRPC通信后后,再进行数据块的读出和写入操作。
B.
通过提交器提交job任务,返回一个PATH
也返回一个Job的ID
拼接上述PATH和JobID
将jar包信息拷贝到HDFS中 job信息,存放job地址和副本数量
提交到服务端RM jobid、jar包地址,其他配置信息,通过RPC通信
大数据框架-Mapreduce过程的更多相关文章
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
转自:https://www.cnblogs.com/reed/p/7730329.html 今天看到一篇讲得比较清晰的框架对比,这几个框架的选择对于初学分布式运算的人来说确实有点迷茫,相信看完这篇文 ...
- 大数据框架:Spark vs Hadoop vs Storm
大数据时代,TB级甚至PB级数据已经超过单机尺度的数据处理,分布式处理系统应运而生. 知识预热 「专治不明觉厉」之“大数据”: 大数据生态圈及其技术栈: 关于大数据的四大特征(4V) 海量的数据规模( ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink——flink支持SQL,待看
简介 大数据是收集.整理.处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称.虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性.规模,以及价值在最近几年才 ...
- YARN之上的大数据框架REEF:微软出品,是否值得期待?
YARN之上的大数据框架REEF:微软出品,是否值得期待? 摘要:微软即将开源大数据框架REEF,REEF运行于Hadoop新一代资源管理器YARN的上层.对于机器学习等在数据传输.任务监控和结果 ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- 老李分享:大数据框架Hadoop和Spark的异同
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-845052 ...
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
- [转载] 2 分钟读懂大数据框架 Hadoop 和 Spark 的异同
转载自https://www.oschina.net/news/73939/hadoop-spark-%20difference 谈到大数据,相信大家对Hadoop和Apache Spark这两个名字 ...
- 2分钟读懂大数据框架Hadoop和Spark的异同
转自:https://www.cnblogs.com/reed/p/7730313.html 谈到大数据,相信大家对Hadoop和Apache Spark这两个名字并不陌生.但我们往往对它们的理解只是 ...
随机推荐
- 定时器实现方式之TimerTask、Timer
在未来某个指定的时间点或者经过一段时间延迟后执行某个事件,这时候就需要用到定时器了.定时器的实现方式有很多种,今天总结最简单的实现方式.java 1.3引入了定时器框架,用于在定时器上下文中控制线程的 ...
- 配置centos7 网卡
进入root模式,输入 cd /etc/sysconfig/network-scripts/ 按Tab键查看网卡配置文件名称,然后进入编辑: 如: cd /etc/sysconfig/network- ...
- 洛谷P2196 挖地雷(dp)
题意 题目链接 Sol 早年NOIP的题锅好多啊.. 这题连有向边还是无向边都没说(害的我wa了一遍) 直接\(f[i]\)表示到第\(i\)个点的贡献 转移的时候枚举从哪个点转移而来 然后我就用一个 ...
- var a =10 与 a = 10的区别
学习文章------汤姆大叔-变量对象 总结笔记 变量特点: ①变量声明可以存储在变量对象中.②变量不能直接用delete删除. var a =10 与 a = 10的区别: ①a = 10只是为全局 ...
- JS如何使用Math.atan2获取两点之间角度的实践案例
本文主要介绍使用如何实现手动拖拽旋转元素的效果. 1.简述 最近在研究如何实现手动控制元素的旋转效果,在网上找了很多,都没有找出类似的实现,因此经过一些调研和计算,最终完美实现效果,在这里记录下来. ...
- 用CSS隐藏页面元素的5种方法
1.opacity设置一个元素的透明度只是从视觉上隐藏元素,对页面布局还是有影响,读屏软件会原样读出 2.visibility设置为hidden将隐藏我们的元素,对网页布局还是起作用,子元素也会被隐藏 ...
- 【小记录】关于dojo中的on事件
今天碰到一个现象,若是一个函数中存在一个on事件(例如点击事件),在该函数连续触发两次之后在去触发里面的on事件,会发现改时间所对应的函数被调用了两次,若父函数被连续触发N次后再取触发on事件,其对应 ...
- 记重回IT行业的面试
问点: 0,梳理一个前端知识框架 1,jQuery的理解 2,仿某网站首页,除了download,显示新优化地方 3,文档模型(DOM) 事件流 事件处理程序 事件类型 例如阻止冒泡的方法 4,前端跟 ...
- Azure 中 Linux 虚拟机的大小
本文介绍可用于运行 Linux 应用和工作负荷的 Azure 虚拟机的可用大小与选项. 此外,还提供在计划使用这些资源时要考虑的部署注意事项. 本文也适用于 Windows 虚拟机. 类型 大小 说明 ...
- order by注入点利用方式分析
漏洞分析 使用sqli-lab中的lesson-52作为测试目标.关键代码为: error_reporting(0); $id=$_GET['sort']; if(isset($id)) { //lo ...