(数据科学学习手札92)利用query()与eval()优化pandas代码
本文示例代码已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
利用pandas进行数据分析的过程,不仅仅是计算出结果那么简单,很多初学者喜欢在计算过程中创建一堆命名随心所欲的中间变量,一方面使得代码读起来费劲,另一方面越多的不必要的中间变量意味着越高的内存占用,越多的计算资源消耗。
因此很多时候为了提升整个数据分析工作流的执行效率以及代码的简洁性,需要配合一些pandas中的高级特性。本文就将带大家学习如何在pandas中化繁为简,利用query()和eval()来实现高效简洁的数据查询与运算。
 图1
图1
2 基于query()的高效查询
query()顾名思义,是pandas中专门执行数据查询的API,其实早在2014年,pandas0.13版本中这个特性就已经出现了,随着后续众多版本的迭代更新,目前pandas中的query()已经进化得非常好用(笔者目前使用的pandas版本为1.1.0)。
首先从一个实际例子认识一下query()的用法,这里我们使用到netflix电影与剧集发行数据集,包含了6234个作品的基本属性信息,你可以在文章开头的Github仓库对应目录下找到它。
 图2
图2
正常读入数据后,我们分别使用传统方法和query()来执行这样的组合条件查询,不同的条件之间用对应的and or或& |连接均可:
找出类型为TV Show且国家不含美国的Kids' TV
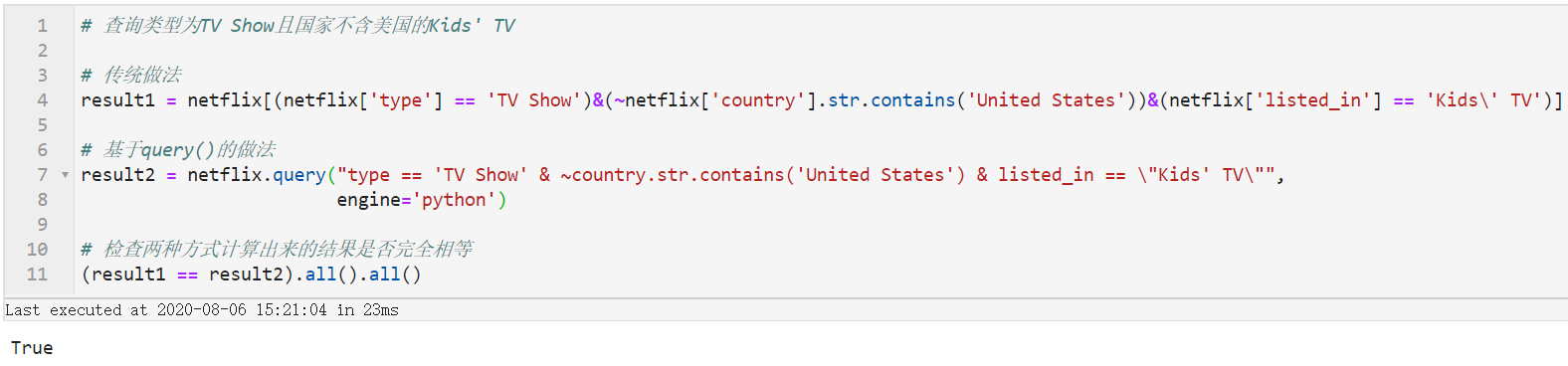 图3
图3
通过比较可以发现在使用query()时我们在不需要重复书写数据框名称[字段名]这样的内容,字段名也直接可以当作变量使用,而且不同条件之间不需要用括号隔开,在条件繁杂的时候简化代码的效果更为明显。
通过上面的小例子我们认识到query()的强大之处,下面我们就来学习query()的常用特性:
2.1 直接解析字段名
query()最核心的特性就是可以直接根据传入的查询表达式,将字段名解析为对应的列,其中对字段名的命名规范有一定要求:当字段名符合Python中对变量命名规范的要求时,即变量名完全由字母、数字、下划线构成且不以数字开头,这样的字段是可以直接写入query()表达式的。
但大家如果尝试过会发现一些不符合上述规范的变量名也不报错,譬如:
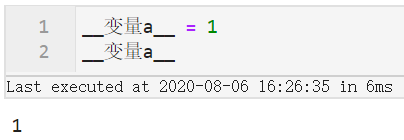 图4
图4
因此可以记住只要在Python里作为变量名不报错,就可以直接填入字段名,否则需要在字段名两边加上`,譬如下面的例子:
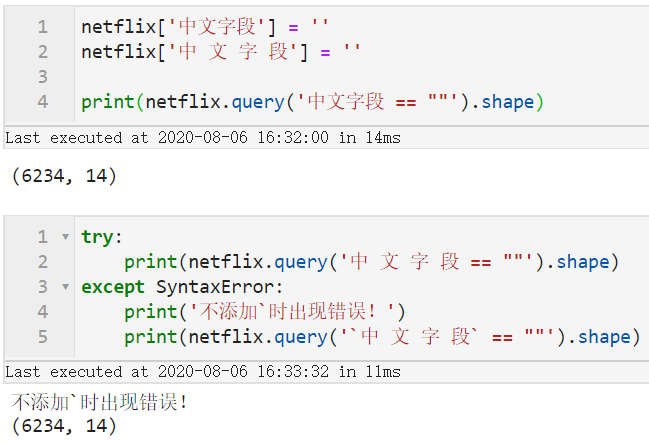 图5
图5
2.2 链式表达式
query()中还支持链式表达式(chained expressions),使得我们可以进一步简化多条件组合时的语法:
demo = pd.DataFrame({
'a': [5, 4, 3, 2, 1],
'b': [1, 2, 3, 4, 5]
})
demo.query("a <= b != 4")
 图6
图6
2.3 支持in与not in判断
query()支持Python原生的in判断以及not in判断,从而简化了多条件判断,比如我们针对netflix数据集想找出release_year等于2018或2019的作品:
netflix.query("release_year in [2018, 2019]")
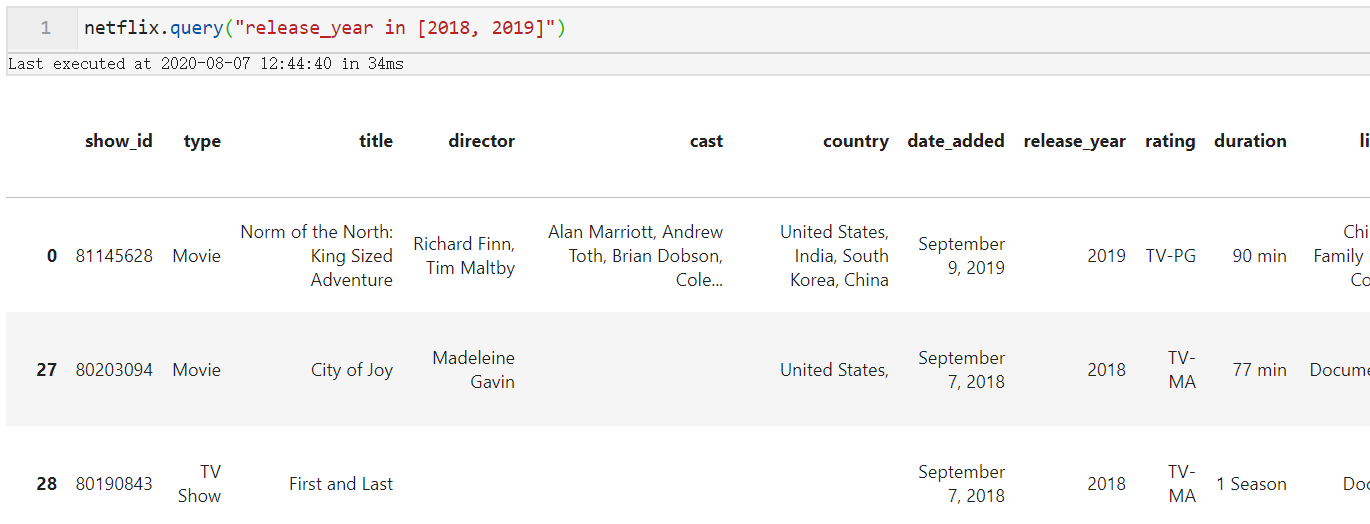 图7
图7
2.4 对外部变量的支持
query()表达式还支持使用外部变量,只需要在外部变量前加上@符号即可:
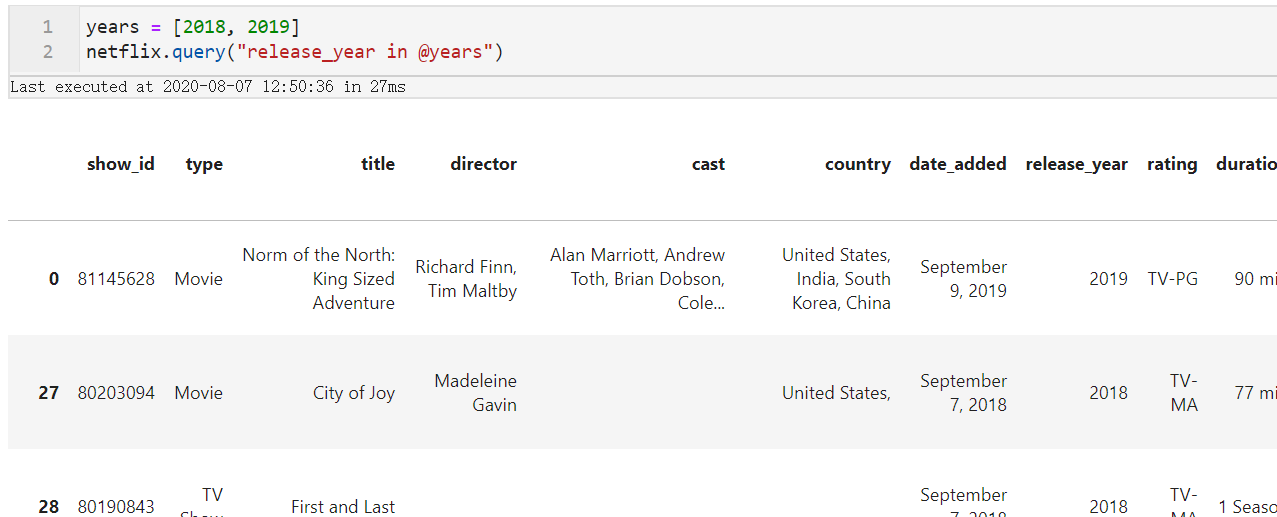 图8
图8
2.5 对常规语句的支持
query()我个人觉得最惊人的功能就是其可以直接解析Python语句,这赋予我们极大的自由度:
def country_count(s):
'''
计算涉及国家数量
'''
return s.split(',').__len__()
# 找出发行年份在2018或2019年且合作国家数量超过5个的剧集
netflix.query("release_year.isin([2018, 2019]) and country.apply(@country_count) > 5")
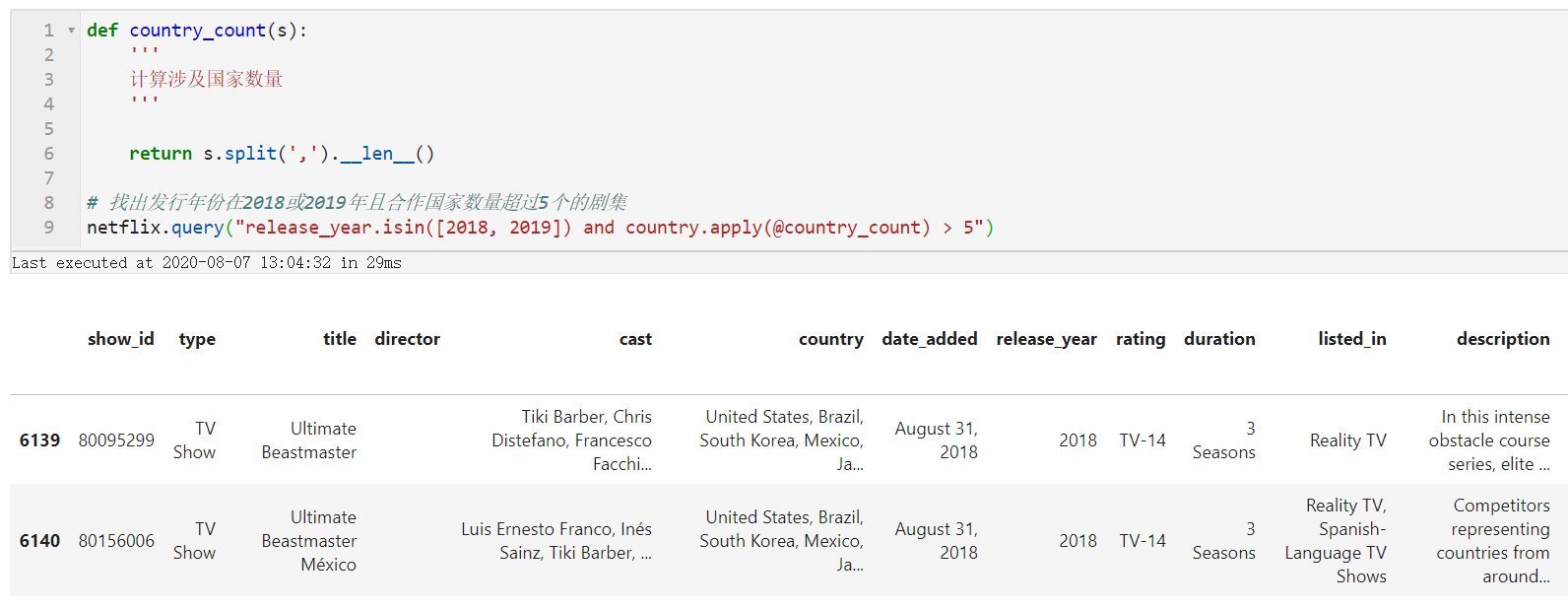 图9
图9
2.6 对Index与MultiIndex的支持
除了对常规字段进行条件筛选,query()还支持对数据框自身的index进行条件筛选,具体可分为三种情况:
- 常规index
对于只具有单列Index的数据框,直接在表达式中使用index:
# 找出索引列中包含king的记录,忽略大小写
netflix.set_index('title').query("index.str.contains('king', case=False)")
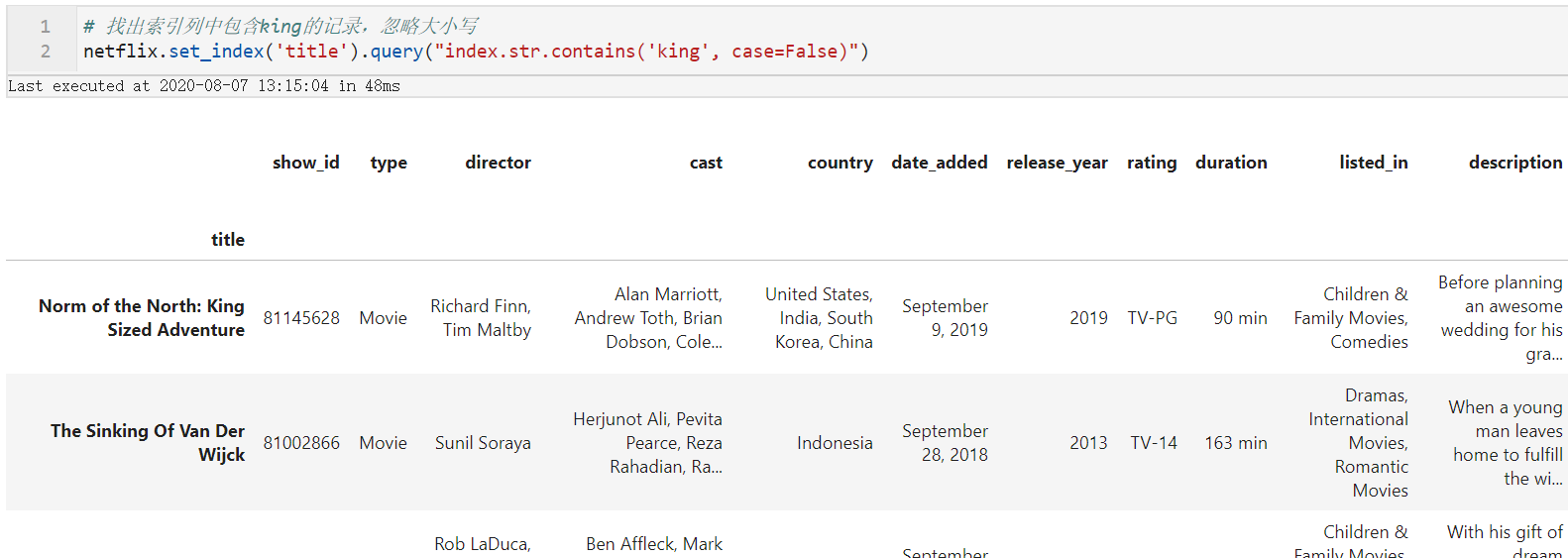 图10
图10
- names为空的MultiIndex
对于MultiIndex的情况,可分为两种,首先我们来看看MultiIndex的names为空的情况,按照顺序,用ilevel_n表示MultiIndex中的第n列index:
# 构造含有MultiIndex的数据框,并重置index的names为None
temp = netflix.set_index(['title', 'type']);temp.index.names = (None, None)
# 找出第一个index包含king(忽略大小写),第二个index等于Movie的记录
temp.query("ilevel_0.str.contains('king', case=False) and ilevel_1 == 'Movie'")
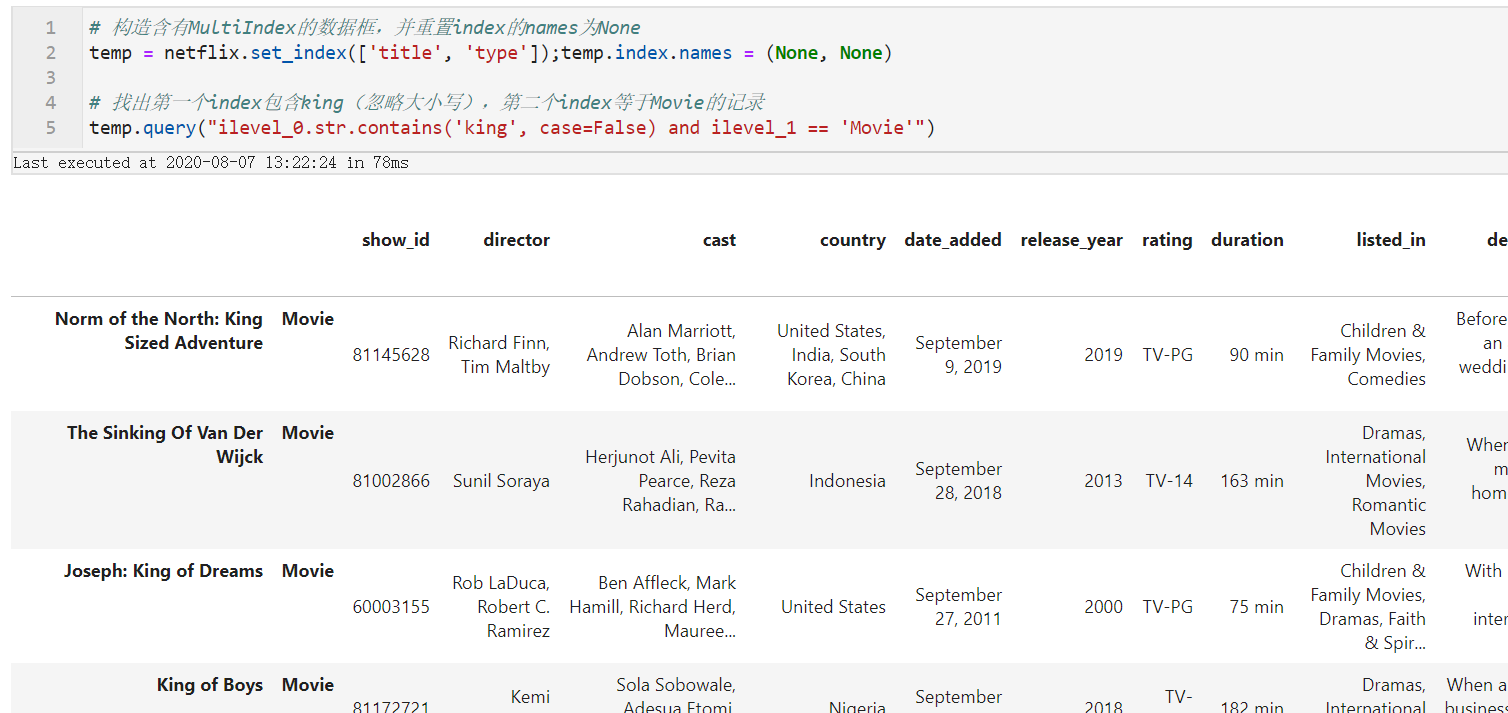 图11
图11
- names不为空的MultiIndex
而对于MultiIndex的names有内容的情况,直接用对应的名称传入表达式即可:
# 构造含有MultiIndex的数据框,并重置index的names为None
temp = netflix.set_index(['title', 'type'])
# 找出第一个index包含king(忽略大小写),第二个index等于Movie的记录
temp.query("title.str.contains('king', case=False) and type == 'Movie'")
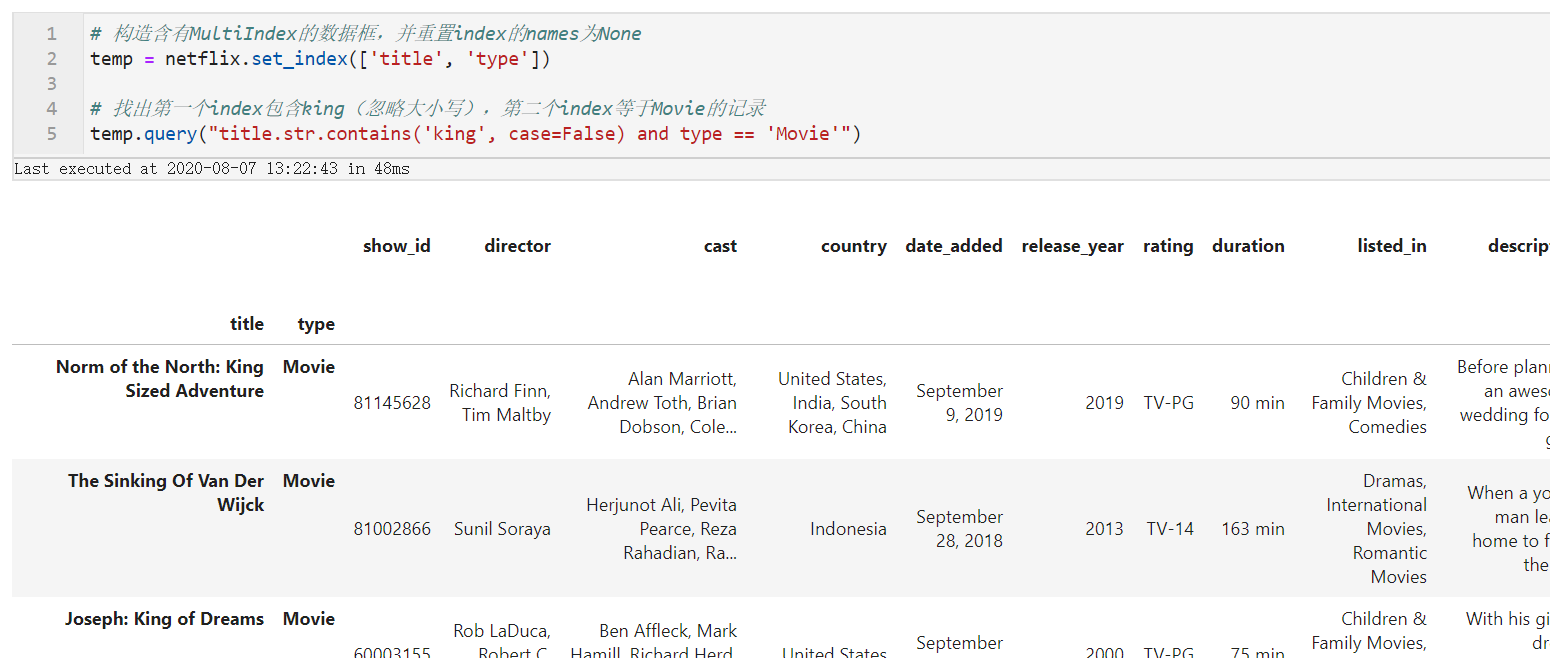 图12
图12
3 基于eval()的高效运算
而eval()类似Python的eval()函数,可以将字符串形式的命令直接解析并执行。
而pandas中的eval()有两种,一种是top-level级别的eval()函数,而另一种是针对数据框的DataFrame.eval(),我们接下来要介绍的是后者,其与query()有很多相同之处,下面只介绍其独有特点。
同样从实际例子出发,同样针对netflix数据,我们按照一定的计算方法为其新增两列数据,对基于assign()的方式和基于eval()的方式进行比较,其中最后一列是False是因为日期转换使用coerce策略之后无法被解析的日期会填充pd.NAT,而缺失值之间是无法进行相等比较的:
# 利用assign进行新增字段计算并保存为新数据框
result1 = netflix.assign(years_to_now=2020 - netflix['release_year'],
new_date_added=pd.to_datetime(netflix['date_added'].str.strip(),
format='%B %d, %Y', errors='coerce'))
# 利用eval()进行新增字段计算并保存为新数据框
result2 = netflix.eval('''
years_to_now = 2020 - release_year
new_date_added = @pd.to_datetime(date_added.str.strip(), format='%B %d, %Y', errors='coerce')''')
(result1 == result2).all()
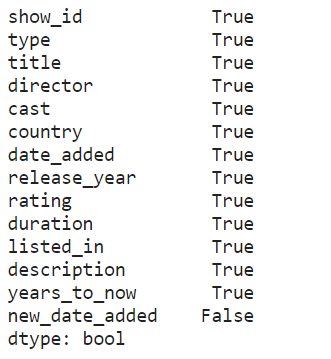 图13
图13
虽然assign()已经算是pandas中简化代码的很好用的API了,但面对eval(),还是逊色不少
DataFrame.eval()通过传入多行表达式,每行作为独立的赋值语句,其中对应前面数据框中数据字段可以像query()一样直接书写字段名,亦可像query()那样直接执行Python语句。
但要注意的是eval()中每个新字段的赋值必须写在同一行,否则会出错:
netflix.eval('''
years_to_now = 2020 - release_year
new_date_added = @pd.to_datetime(date_added.str.strip(),
format='%B %d, %Y',
errors='coerce')''')
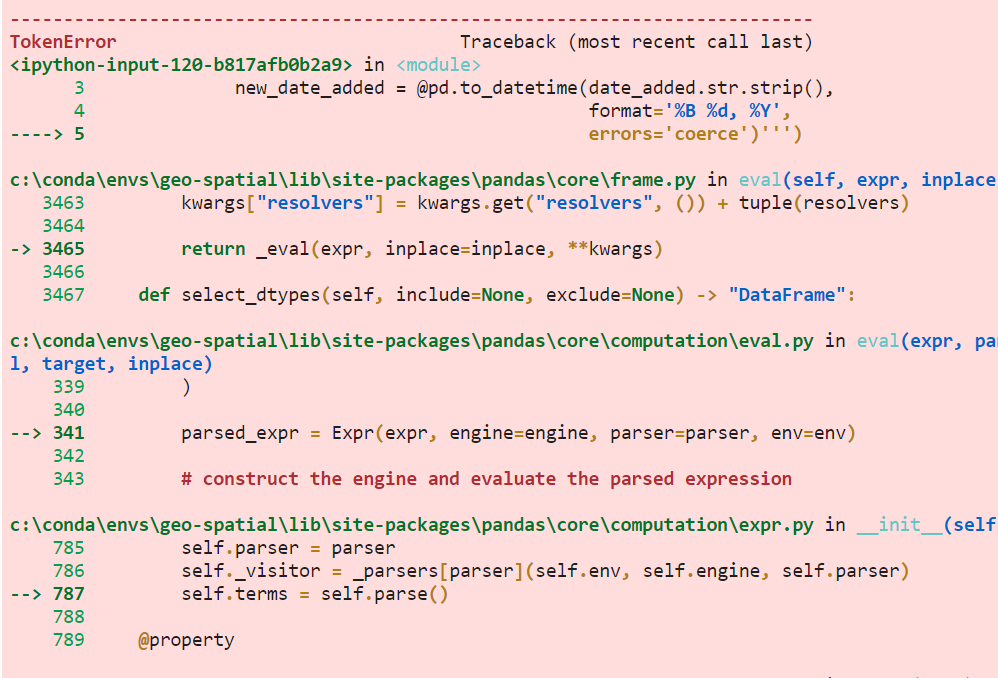 图14
图14
因此如果你要使用到的函数参数很多,可以利用functools中的partial将一些参数固化并保存,从而达到简化eval()表达式的目的:
from functools import partial
# 利用partial固化指定参数
func = partial(pd.to_datetime, format='%B %d, %Y', errors='coerce')
netflix.eval('''
years_to_now = 2020 - release_year
new_date_added = @func(date_added.str.strip())''')
而我最喜欢DataFrame.eval()的地方在于配合他,我可以在很多数据分析场景中实现0中间变量,一直链式下去,延续上面的例子,当我们新增了这两列数据之后,接下来我们按顺序进行按月统计影片数量、字段重命名、新增当月数量在全部记录排名字段、排序,其中关键的是新增当月数量在全部记录排名字段,如果不用eval(),你是无法在不创建中间变量的前提下如此简洁地完成需求的:
netflix.eval('''
years_to_now = 2020 - release_year
new_date_added = @func(date_added.str.strip())''') \
.resample('M', on='new_date_added') \
.agg({'new_date_added': 'count'}) \
.rename(columns={'new_date_added': '月度发行数量'}) \
.eval('''月度发行数量排名 = 月度发行数量.rank(ascending=False).astype('int')''') \
.sort_values('月度发行数量排名')
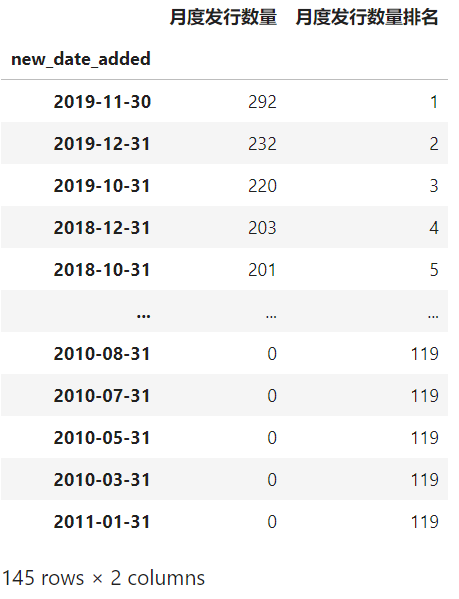 图15
图15
使用query()+eval(),升华pandas数据分析操作。
以上就是本文的全部内容,欢迎在评论区与我讨论~
(数据科学学习手札92)利用query()与eval()优化pandas代码的更多相关文章
- (数据科学学习手札86)全平台支持的pandas运算加速神器
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 随着其功能的不断优化与扩充,pandas已然成为 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
随机推荐
- Django框架12 /同源、跨域、CORS
Django框架12 /同源.跨域.CORS 目录 Django框架12 /同源.跨域.CORS 1. 同源策略 2. 跨域 3. 解决跨域:CORS/跨域资源共享 1. 同源策略 同源策略(Same ...
- Django框架01 / http协议、web框架本质
Django框架01 / http协议.web框架本质 目录 Django框架01 / http协议.web框架本质 1.http协议 1.1 http协议简介 1.2 什么是http协议 1.3 H ...
- Iphone上对于动态生成的html元素绑定点击事件$(document).click()失效解决办法
在Iphone上,新生成的DOM元素不支持$(document).click的绑定方法,该怎么办呢? 百度了N久都没找到解决办法,在快要走投无路之时,试了试Google,我去,还真找到了,歪国人就是牛 ...
- 使用QtCreator遇到的一些问题
0. 背景 最近在学习QtCreator(版本:4.8.1:编译器:MSVC 2017 64-bit),遇到了一些问题,特记录如下.( 1. 引用库 QtCreator可以直接包含Windows.h, ...
- 如果你每次面试前都要去背一篇Spring中Bean的生命周期,请看完这篇文章
前言 当你准备去复习Spring中Bean的生命周期的时候,这个时候你开始上网找资料,很大概率会看到下面这张图: 先不论这张图上是否全面,但是就说这张图吧,你是不是背了又忘,忘了又背? 究其原因在于, ...
- python+requests实现接口自动化
1. 前言 今年2月调去支持项目接口测试,测试过程中使用过postman.jmeter工具,基本能满足使用,但是部分情况下使用较为麻烦.比如:部分字段存在唯一性校验或字段间有业务性校验,每次请求均需手 ...
- react实战 : react 与 svg
有一个需求是这样的. 一个组件里若干个区块.区块数量不定. 区块里面是一个波浪效果组件,而这个一般用 SVG 做. 所以就变成了在 react 中使用 SVG 的问题. 首先是波浪效果需要的样式. . ...
- 重磅分享:美团点评架构师私藏的内部Linux运维笔记
最近不少小伙伴后台联系,希望能弄一些大厂的学习资料,我这边费了很大劲,联系到老朋友,原美团点评架构师张sir,问他要了些美团点评架构的内部资料. 这份资料含金量非常高,包含整个美团点评架构架构图,Li ...
- iconfont - 好用免费的图标库
某里出品 打开首页???????搜索框在哪里 网站:点我
- 设计模式:mediator模式
目的:解决多组件之间的通信问题,使得组件之间的通信变得简单 核心:提供一个管理类,用来处理组件之间的通信,所有的组件只和管理类通信,组件彼此之间不在单独通信 例子: class Mediator { ...