算法学习笔记:最近公共祖先(LCA问题)
当我们处理树上点与点关系的问题时(例如,最简单的,树上两点的距离),常常需要获知树上两点的最近公共祖先(Lowest Common Ancestor,LCA)。如下图所示:

2号点是7号点和9号点的最近公共祖先
我们先来讨论朴素的做法。
首先进行一趟dfs,求出每个点的深度:
int dep[MAXN];
bool vis[MAXN];
void dfs(int cur, int fath = 0)
{
if (vis[cur])
return;
vis[cur] = true;
dep[cur] = dep[fath] + 1; // 每个点的深度等于父节点的深度+1
for (int eg = head[cur]; eg != 0; eg = edges[eg].next)
dfs(edges[eg].to, cur);
}
现在A点的深度比B点深,所以我们先让B点往上“爬”,爬到与A点深度相等为止。然后A点和B点再一起往上爬,直到两点相遇,那一点即为LCA:
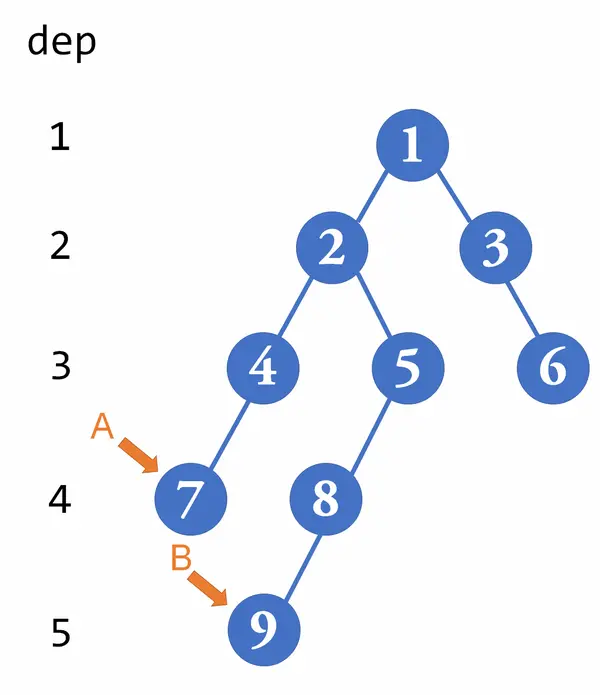
这样下来,每次查询LCA的最坏时间复杂度是 的。
有时候,我们需要进行很多次查询,这时朴素的 复杂度就不够用了。我们考虑空间换时间的倍增算法。
倍增的思想直观体现就在 ST表 中提及过。我们用一个数组fa[i][k]存储 号点的
级祖先。(父节点为1级祖先,祖父结点为2级祖先……以此类推)
那么这可以在dfs途中动态规划得出:
// 在dfs中...
fa[cur][0] = fath;
for (int i = 1; i <= Log2[dep[cur]]; ++i) // Log2的预处理参见ST表的笔记
fa[cur][i] = fa[fa[cur][i - 1]][i - 1]; // 这个DP也参见ST表的笔记
这样,往上爬的次数可以被大大缩短(现在变成“跳”了)。
首先还是先让两点深度相等:
if (dep[a] > dep[b]) // 不妨设a的深度小于等于b
swap(a, b);
while (dep[a] != dep[b]) // 跳到深度相等为止
b = fa[b][Log2[dep[b] - dep[a]]]; // b不断往上跳
例如,a和b本来相差22的深度,现在b不用往上爬22次,只需要依次跳16、4、2个单位,3次便能达到与a相同的距离。
两者深度相等后,如果两个点已经相遇,那么问题就得以解决。如果尚未相遇,我们再让它们一起往上跳。问题在于,如何确定每次要跳多少?正面解决也许不太容易,我们逆向思考:如何在a、b不相遇的情况下跳到尽可能高的位置?如果找到了这个位置,它的父亲就是LCA了。
说来也简单,从可能跳的最大步数Log2[dep[a]](这样至多跳到0号点,不会越界)开始,不断减半步数(不用多次循环):
for (int k = Log2[dep[a]]; k >= 0; k--)
if (fa[a][k] != fa[b][k])
a = fa[a][k], b = fa[b][k];
以刚刚那棵树为例,先尝试Log2[4]=2,A、B点的 级祖先都是0(图中未画出),所以不跳。然后尝试1,A、B的
祖先都是2,也不跳。最后尝试0,A、B的1级祖先分别是4和5,跳。结束。
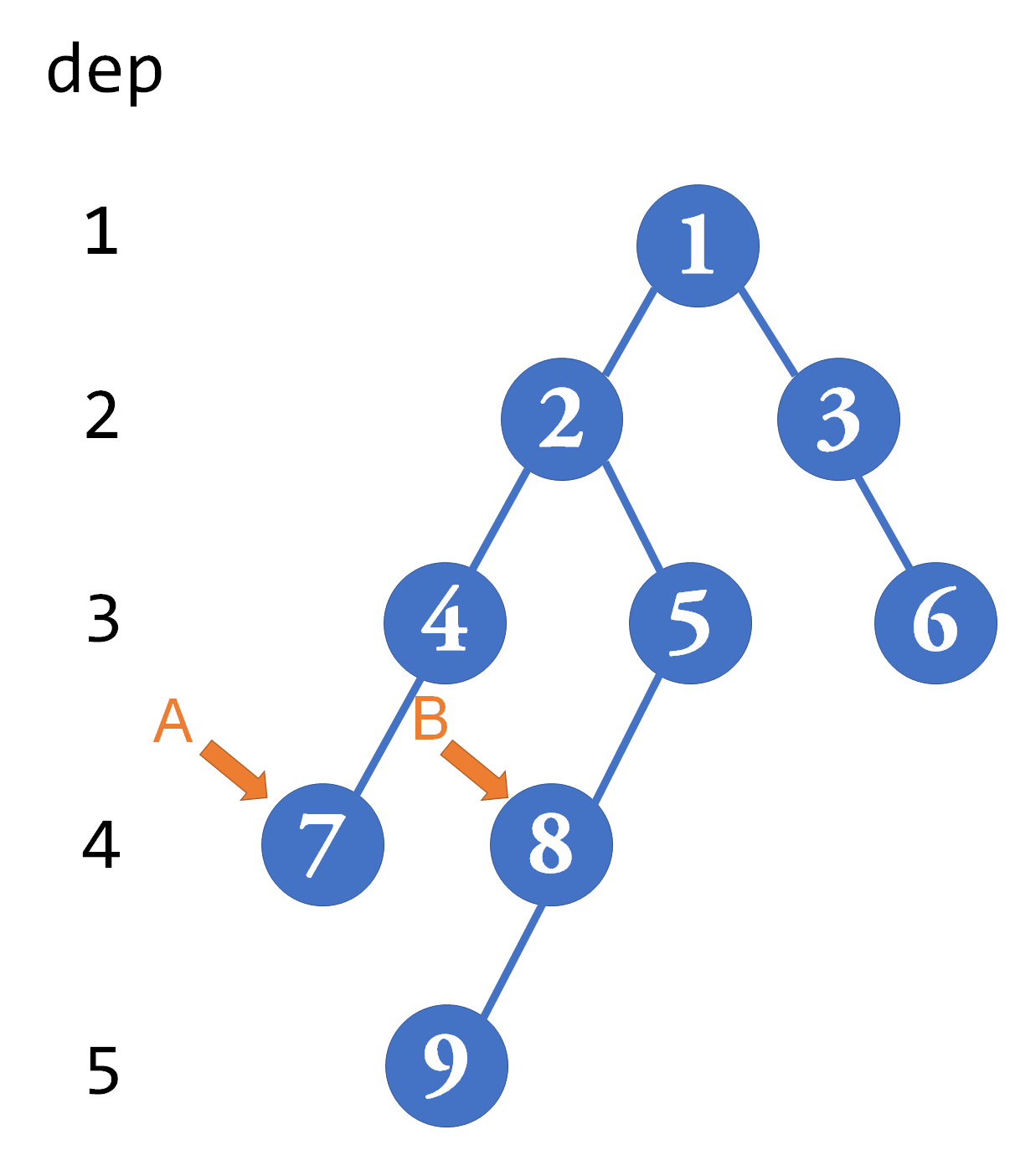
这样下来,再往上一格所得到的2号点就是所求的最近公共祖先。
主要代码如下:
int Log2[MAXN], fa[MAXN][20], dep[MAXN]; // fa的第二维大小不应小于log2(MAXN)
bool vis[MAXN];
void dfs(int cur, int fath = 0)
{
if (vis[cur])
return;
vis[cur] = true;
dep[cur] = dep[fath] + 1;
fa[cur][0] = fath;
for (int i = 1; i <= Log2[dep[cur]]; ++i)
fa[cur][i] = fa[fa[cur][i - 1]][i - 1];
for (int eg = head[cur]; eg != 0; eg = edges[eg].next)
dfs(edges[eg].to, cur);
}
int lca(int a, int b)
{
if (dep[a] > dep[b])
swap(a, b);
while (dep[a] != dep[b])
b = fa[b][Log2[dep[b] - dep[a]]];
if (a == b)
return a;
for (int k = Log2[dep[a]]; k >= 0; k--)
if (fa[a][k] != fa[b][k])
a = fa[a][k], b = fa[b][k];
return fa[a][0];
}
int main()
{
// ...
for (int i = 2; i <= n; ++i)
Log2[i] = Log2[i / 2] + 1;
// ...
dfs(s); // 无根树可以随意选一点为根
// ...
return 0;
}
至于树上两点 的距离,有公式
(很好推)。
预处理,
查询,空间复杂度为
。
当然,以上都是针对无权树的,如果有权值,可以额外记录一下每个点到根的距离,然后用几乎相同的公式求出。
算法学习笔记:最近公共祖先(LCA问题)的更多相关文章
- 学习笔记--最近公共祖先(LCA)的几种求法
前言: 给定一个有根树,若节点\(z\)是两节点\(x,y\)所有公共祖先深度最大的那一个,则称\(z\)是\(x,y\)的最近公共祖先(\(Least Common Ancestors\)),简称\ ...
- [一本通学习笔记] 最近公共祖先LCA
本节内容过于暴力没什么好说的.借着这个专题改掉写倍增的陋习,虽然写链剖代码长了点不过常数小还是很香. 10130. 「一本通 4.4 例 1」点的距离 #include <bits/stdc++ ...
- Luogu 2245 星际导航(最小生成树,最近公共祖先LCA,并查集)
Luogu 2245 星际导航(最小生成树,最近公共祖先LCA,并查集) Description sideman做好了回到Gliese 星球的硬件准备,但是sideman的导航系统还没有完全设计好.为 ...
- POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA)
POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA) Description A ...
- [模板] 最近公共祖先/lca
简介 最近公共祖先 \(lca(a,b)\) 指的是a到根的路径和b到n的路径的深度最大的公共点. 定理. 以 \(r\) 为根的树上的路径 \((a,b) = (r,a) + (r,b) - 2 * ...
- [知识点]最近公共祖先LCA
UPDATE(20180822):重写部分代码. 1.前言 最近公共祖先(LCA),作为树上问题,应用非常广泛,而求解的方式也非常多,复杂度各有不同,这里对几种常用的方法汇一下总. 2.基本概念和暴力 ...
- 【lhyaaa】最近公共祖先LCA——倍增!!!
高级的算法——倍增!!! 根据LCA的定义,我们可以知道假如有两个节点x和y,则LCA(x,y)是 x 到根的路 径与 y 到根的路径的交汇点,同时也是 x 和 y 之间所有路径中深度最小的节 点,所 ...
- C / C++算法学习笔记(8)-SHELL排序
原始地址:C / C++算法学习笔记(8)-SHELL排序 基本思想 先取一个小于n的整数d1作为第一个增量(gap),把文件的全部记录分成d1个组.所有距离为dl的倍数的记录放在同一个组中.先在各组 ...
- POJ 1470 Closest Common Ancestors(最近公共祖先 LCA)
POJ 1470 Closest Common Ancestors(最近公共祖先 LCA) Description Write a program that takes as input a root ...
- Manacher算法学习笔记 | LeetCode#5
Manacher算法学习笔记 DECLARATION 引用来源:https://www.cnblogs.com/grandyang/p/4475985.html CONTENT 用途:寻找一个字符串的 ...
随机推荐
- Azure Web App (二)使用部署槽切换部署环境
一,引言 前天我们将到使用Azure的 Pass 服务 “Web App” 去部署我们的.NET Core Web项目,也同时有介绍到如何在VS中配置登陆中国区的Azure账号,今天接着讲,我们部署完 ...
- Web For Pentester靶场(xss部分)
配置 官网:https://pentesterlab.com/ 下载地址:https://isos.pentesterlab.com/web_for_pentester_i386.iso 安装方法:虚 ...
- 使用Python进行自动化测试
目前大家对Python都有一个共识,就是他对测试非常有用,自动化测试里Python用途也很广,但是Python到底怎么进行自动化测试呢?今天就简单的向大家介绍一下怎么使用Python进行自动化测试,本 ...
- Ethical Hacking - Web Penetration Testing(1)
How to hack a website? An application installed on a computer. ->web application pen-testing A co ...
- django.core.exceptions.ImproperlyConfigured: mysqlclient 1.3.13 or newer is required; you have 0.9.3.解决办法
"E:\API_Manager_PlatForm\venv\lib\site-packages\django\db\backends\mysql\base.py"在这个路径里件把b ...
- Oracle修改表类型方法
有一个表名为tb,字段段名为name,数据类型nchar(20). 1.假设字段数据为空,则不管改为什么字段类型,可以直接执行:alter table tb modify (name nvarchar ...
- ZYNQ PS端IIC接口使用-笔记
ZYNQ7000系列FPGA的PS自带两个IIC接口,接口PIN IO可扩展为EMIO形式即将IO约束到PL端符合电平标准的IO(BANK12.BANK13.BANK34.BANK35): SDK中需 ...
- java基础(11)--封装
一.java面向对象三大特别: 1.封装 2.继承 3.多态 二.封装的作用 1.属性私有化(private) 2.对外提供简单的入口 如公开的set()与get()方法,并且都不带static ...
- Bug--时区问题导致IDEA连接数据库失败
打开cmd进入mysql,设置 set global time_zone='+8:00';
- adb常用命令大全
1. 显示系统中全部Android平台: android list targets2. 显示系统中全部AVD(模拟器): 启动制定模拟器:emulator -avd 模拟器名字 andr ...