Zookeeper启动流程分析
前言
之前的Zookeeper协议篇-Paxos算法与ZAB协议通过了解Paoxs算法开始,到Zab协议的两大特性:崩溃恢复和消息广播,学习了Zookeeper是如何通过Zab协议实现高可用,本篇主要解析Zookeeper的启动流程
单机模式启动流程
我们知道,Zookeeper使用中分为单机和集群两种,而这两种最大的不同则是,集群启动下需要进行Leader选举以及Leader和Follower之间的数据同步操作,而单机启动则不需要此操作,Zookeeper单机启动大概分为三个部分,分别为预处理、初始化和注册,接下来我们分别来看看三个流程的步骤
预处理
预处理操作中,将创建服务实例之前需要的数据读取加载准备就绪,大体流程如下:
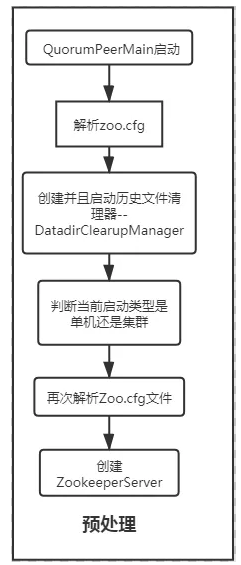
1.首先我们在使用zkServer.sh或者zkServer.cmd这两个脚本启动Zookeeper的时候,默认会启动 org.apache.zookeeper.server.quorum.QuorumPeerMain类,因此无论是Zookeeper的单机还是集群环境下, QuormPeerMain类都是作为默认的入口启动类启动。
2.启动后就会开始解析Zoo.cfg配置文件,从中读取默认配置的tickTime、dataDir和clientPort等
3.当配置读取并解析完毕以后,会创建 DatadirCleanupManager类实例,此类是Zookeeper从3.4版本开始加入的对历史记录文件进行清理以及定时清理日志和快照的管理器
4.从刚刚读取解析的Zoo.cfg配置文件内容中找到clientPort参数内容,通过配置的地址判断是否存在多个地址来确定当前启动的模式是单机版还是集群模式,如果当前启动模式为单机模式,将进入单机的启动流程,并且读取Zoo.cfg剩余的配置信息
5.通过解析Zoo.cfg中的配置信息相关的参数,开始创建ZookeeperServer类实例,完成了这一步后,预处理阶段完成
初始化
初始化阶段,则是开始将Zookeeper中的相关服务管理类进行创建,大体流程如下:
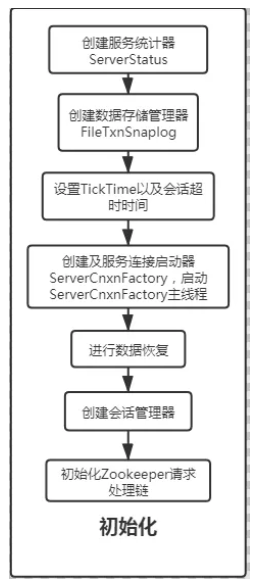

1.创建了ZookeeperServer实例后,Zookeeper会创建一个ServerStats实例,此类用来收集Zookeeper运行过程中的统计信息,例如发送客户端的响应包次数,收到的请求包次数,最近启动后最大的延迟和最小延迟等
2.紧接着会创建Zookeeper中的数据存储管理器--FileTxnSnaplog类,此类作为最上层的,提供了一系列了操作数据文件的接口,其中包括操作事务日志和操作快照的接口,而创建当前类实例会根据zoo.cfg中的dataDir以及dataLogDir参数进行构建
3.同样根据解析出来的zoo.cfg配置文件中的tickTime以及session的会话时间来设置对应参数,并且会根据zookeeper.serverCnxnFactory参数来确定启动Zookeeper的网络连接工厂是基于Netty的还是基于jdk自身的Nio工厂
4.确定工厂类型后,Zookeeper会开始初始化一个Thread,作为整个Zookeeper运行过程中的主线程,并且开始初始化ServerCnxnFactory实例
5.当ServerCnxnFactory实例构建完毕后,开始运行对应的run方法中的业务逻辑,此时由于连接工厂已经创建,端口其实已经对外开放了,但是Zookeeper此时还未完成启动过程,还无法对外处理请求
6.开始恢复Zookeeper的数据,将从事务日志以及之前保存的快照进行数据恢复
7.数据恢复完成后,Zookeeper开始构建会话管理器--SessionTracker,此类主要负责管理Session,在创建的时候,将e xpirationlnterval, nextExpirationTime和 sessionsWithTimeout进行计算以及配置,并且会计算出每一个Session对应的SessionID,并且在运行过程中会负责Session的会话超时检测等
8.创建完毕后,Zookeeper会初始化对应的请求过滤链,而在Zookeeper中请求的过滤链使用了责任链模式,其中处理的顺序流程主要是PrepRequestProessor->SyncRequestProessor->FinalRequestProessor三个请求处理器,至此Zookeeper的初始化流程已经做完
注册提供服务
当Zookeeper的初始化流程完成后,服务器已经开始到就绪状态了,只需要将对应的信息注册以后即可对外提供服务了,此阶段的流程大概如下:

可以看到此阶段中,Zookeeper只需要将JMX服务注册,以及当前相关实例注册完毕,即可完成单机启动流程,此时的Zookeeper已经正常提供服务了
集群模式启动流程
集群模式的启动过程很多和单机模式是一样的,但是由于集群模式下,会有Leader机器选举以及数据同步的过程,因此Zookeeper的集群模式启动过程要复杂的多,而整个集群的启动过程,大体可以分为五个部分,分别是预处理、初始化、Leader选举、Leader与Follower交互以及Leader与Follower启动,其中预处理过程几乎与单机模式一样,唯一的区别在于解析zoo.cfg中的连接配置,判断启动模式为集群模式,开始进入集群模式的初始化操作流程而已,因此,我们从集群模式的初始化开始
初始化
初始化过程大体和单机模式差不多,如下:
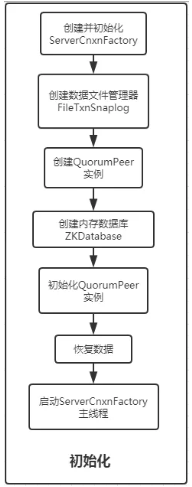
1.创建并初始化ServerCnxnFactory
2.创建Zookeeper中的数据文件管理器FileTxnSnaplog
3.在集群模式下,会去创建QuorumPeer实例,Quorum是集群模式下特有的对象,属于Zookeeper的托管者,此类的作用是在运行期间,会不停的检测当前服务器实例的状态,并且在需要选举的时候发起选举
4.创建Zookeeper中的内存数据库ZKDatabase实例,用来记录会话记录以及DataTree和事物日志
5.QuorumPeer实例作为托管者,会在启动过程中,将核心组件信息注册上去,包括之前创建的ZKDatabase、FileTxnSnaplog以及服务器列表信息,选举算法等
6.开始恢复数据
7.数据恢复完成后,开始启动ServerCnxnFactory中的主线程,运行run方法,开始执行服务器选举相关的操作
Leader选举
选举阶段的流程大概如下:
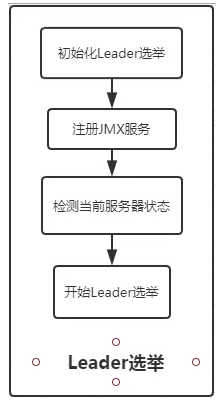
1.Zookeeper解析zoo.cfg配置文件中的 electionAlg属性,来确定进行选举的算法是哪一种,在Zk中有三种选举算法,分别是 LeaderElection 、 AuthFastLeaderElection 和FastLeaderElection,分别对应数值0-3,不过从3.4的版本开始,zk仅支持FastLeaderElection选举算法,其他两种被废弃了。同样的,在选举的初始化阶段,zk会根据自身服务器ID、lastLoggedZxid和当前服务器的epoch初始化一个选举的票据
2.选举初始化准备好以后,开始注册JMX服务
3.前面创建好的QuorumPeer实例会不断检测当前的服务器状态,在正常情况下,QuorumPeer的状态应该是LOOKING,才会开始进行选举操作
4.开始进行选举操作,简单来说,zk中一般是ZXID最大的机器成为Leader,如果ZXID一样,SID越大的则成为Leader。(zk的详细选举流程,则在后续的文章中分析)
Leader与Follower交互
当选举出Leader机器以后,其他的机器则会开始与Leader进行交互,进行数据同步等操作,此阶段的流程大致如下:

1.不同角色(Leader和Follower)的zookeeper服务器在选举完毕后,会开始进入各自角色的主流程
2.在Zookeeper集群运行期间,Leader服务器需要和其他的服务器保持连接确定集群的机器存活情况,zk创建LearnerCnxAcceptor实例用来负责处理所有的非Leader机器的连接请求
3.非Leader服务器在启动完毕后,会从选举的结果中找到集群的Leader,并且尝试进行连接
4.Leader的LearnerCnxAcceptor实例在接受到非Leader机器的请求后,会创建LearnerCnxHandler实例,每个实例会对应一个Leader与非Leader机器的连接,负责对应服务器之间的消息通信处理以及数据同步操作
5.当非Leader机器与Leader服务器建立连接后,非Leader机器就会将自己的信息发送给Leader,此过程的数据称之为LearnerInfo,其中包括了当前服务器的SID以及最大的ZXID
6.Leader收到LearnerInfo消息后,从中解析出SID和ZXID,然后根据ZXID解析出epochoflearner,和Leader自身的epochofleader进行比较,如果发现Leader的epochofleader比较小,则会更新Leader的epoch:
epoch_of_leader = epoch_of_learner + 1
然后继续等待其他机器的LearnerInfo消息,直到半数以上,即可确定整个集群中的epoch值了
7.在确定了epoch以后,Leader将该信息发送给所有的非Leader机器,此消息称之为LEADERINFO
8.Follower机器在收到Leader发送的LEADERINFO消息后,解析出消息中的epoch和ZXID,然后响应给Leader一个ack
9.Leader收到ack以后,就可以开始与该Follower机器进行数据同步过程了
10.整个集群中如果超过半数的Follower机器完成了和Leader之间的数据同步过程,这个时候集群实例就已经可以提前启动对外提供服务
Leader和Follower启动
集群模式下的Zookeeper在完成了Leader与Follower服务器之间的交互流程后,也开始进入到了启动注册的阶段,此阶段和单机模式流程几乎相同,首先是创建并且启动会话管理器,然后初始化Zookeeper中的请求处理链,接着Zookeeper开始注册JMX服务,当注册完毕后,整个集群的启动完成,此时Zookeeper的集群也可以对外开始提供服务了
Zookeeper启动流程分析的更多相关文章
- Storm集群启动流程分析
Storm集群启动流程分析 程序员 1.客户端运行storm nimbus时,会调用storm的python脚本,该脚本中为每个命令编写了一个方法,每个方法都可以生成一条相应的Java命令. 命令格式 ...
- u-boot启动流程分析(2)_板级(board)部分
转自:http://www.wowotech.net/u-boot/boot_flow_2.html 目录: 1. 前言 2. Generic Board 3. _main 4. global dat ...
- u-boot启动流程分析(1)_平台相关部分
转自:http://www.wowotech.net/u-boot/boot_flow_1.html 1. 前言 本文将结合u-boot的“board—>machine—>arch—> ...
- Cocos2d-x3.3RC0的Android编译Activity启动流程分析
本文将从引擎源代码Jni分析Cocos2d-x3.3RC0的Android Activity的启动流程,以下是具体分析. 1.引擎源代码Jni.部分Java层和C++层代码分析 watermark/2 ...
- Netty 拆包粘包和服务启动流程分析
Netty 拆包粘包和服务启动流程分析 通过本章学习,笔者希望你能掌握EventLoopGroup的工作流程,ServerBootstrap的启动流程,ChannelPipeline是如何操作管理Ch ...
- Uboot启动流程分析(转载)
最近一段时间一直在做uboot移植相关的工作,需要将uboot-2016-7移植到单位设计的ARMv7的处理器上.正好元旦放假三天闲来无事,有段完整的时间来整理下最近的工作成果.之前在学习uboot时 ...
- 【转】Netty 拆包粘包和服务启动流程分析
原文:https://www.cnblogs.com/itdragon/archive/2018/01/29/8365694.html Netty 拆包粘包和服务启动流程分析 通过本章学习,笔者希望你 ...
- ubuntu为什么没有/etc/inittab文件? 深究ubuntu的启动流程分析
Linux 内核启动 init ,init进程ID是1,是所有进程的父进程,所有进程由它控制. Ubuntu 的启动由upstart控制,自9.10后不再使用/etc/event.d目录的配置文件,改 ...
- imx6 uboot启动流程分析
参考http://blog.csdn.net/skyflying2012/article/details/25804209 这里以imx6平台为例,分析uboot启动流程对于任何程序,入口函数是在链接 ...
随机推荐
- java_String类、StringBuilder类、Arrays类、Math类的使用
String类 java.lang.String 类代表字符串.Java程序中所有的字符串文字(例如 “abc” )都可以被看作是实现此类的实例 构造方法 java.lang.String :此类不需 ...
- HTML 命名规范!
HTML基础设施 (1)文件应以<!DOCTYPE.....>首行顶格开始,这句话告诉浏览器这是一个什么文件,我们推荐使用<!DOCTYPE html>. (2)必须在head ...
- 93复原IP地址。
from typing import List# 这道题不是很难,但是限制条件有很多.# 用递归的方法可以很容易的想到.只需要四层递归就好了.# 每次进行加上限制条件.过滤每一层就好了..class ...
- C++二分查找:lower_bound( )和upper_bound( )
#include<algorithm>//头文件 //标准形式 lower_bound(int* first,int* last,val); upper_bound(int* first, ...
- C#LeetCode刷题-动态规划
动态规划篇 # 题名 刷题 通过率 难度 5 最长回文子串 22.4% 中等 10 正则表达式匹配 18.8% 困难 32 最长有效括号 23.3% 困难 44 通配符匹配 17.7% ...
- Linux学习日志第一天——基础命令①
文章目录 前言 命令的作用及基本构成 关于路径 命令 ls (list) 命令 pwd (print working directory) 命令cd (change directory) 命令 mkd ...
- go微服务系列(四) - gRPC入门
1. 前言 2. gRPC与Protobuf简介 3. 安装 4. 中间文件演示 4.1 编写中间文件 4.2 运行protoc命令编译成go中间文件 5. 创建gRPC服务端 5.1 新建Produ ...
- 关于Dapper实现读写分离的个人思考
概念相关 为了确保多线上环境数据库的稳定性和可用性,大部分情况下都使用了双机热备的技术.一般是一个主库+一个从库或者多个从库的结构,从库的数据来自于主库的同步.在此基础上我们可以通过数据库反向 ...
- CSS动画实例:旋转的圆角正方形
在页面中放置一个类名为container的层作为效果呈现容器,在该层中再定义十个名为shape的层层嵌套的子层,HTML代码描述如下: <div class="container&qu ...
- shell bash配置
bash主要可以分为两种方式启动(login,no-login) 两种方式所读取的配置文件不同,所以环境不同 login形式启动如下图所示: no-login形式启动: 从 ~/.bashrc开始.