Python之 爬虫(二十三)Scrapy分布式部署
按照上一篇文章中我们将代码放到远程主机是通过拷贝或者git的方式,但是如果考虑到我们又多台远程主机的情况,这种方式就比较麻烦,那有没有好用的方法呢?这里其实可以通过scrapyd,下面是这个scrapyd的github地址:https://github.com/scrapy/scrapyd
当在远程主机上安装了scrapyd并启动之后,就会再远程主机上启动一个web服务,默认是6800端口,这样我们就可以通过http请求的方式,通过接口的方式管理我们scrapy项目,这样就不需要在一个一个电脑连接拷贝过着通过git,关于scrapyd官方文档地址:http://scrapyd.readthedocs.io/en/stable/
安装scrapyd
安装scrapyd:pip install scrapyd
这里我在另外一台ubuntu linux虚拟机中同样安装scrapy以及scrapyd等包,保证所要运行的爬虫需要的包都完成安装,这样我们就有了两台linux,包括上篇文章中我们已经有的linux环境
在这里有个小问题需要注意,默认scrapyd启动是通过scrapyd就可以直接启动,这里bind绑定的ip地址是127.0.0.1端口是:6800,这里为了其他虚拟机访问讲ip地址设置为0.0.0.0
scrapyd的配置文件:/usr/local/lib/python3.5/dist-packages/scrapyd/default_scrapyd.conf
这样我们就可以通过浏览器访问:

关于部署
如何通过scrapyd部署项目,这里官方文档提供一个地址:https://github.com/scrapy/scrapyd-client,即通过scrapyd-client进行操作
这里的scrapyd-client主要实现以下内容:
- 把我们本地代码打包生成egg文件
- 根据我们配置的url上传到远程服务器上
我们将我们本地的scrapy项目中scrapy.cfg配置文件进行配置:

我们其实还可以设置用户名和密码,不过这里没什么必要,只设置了url
这里设置url一定要注意:url = http://192.168.1.9:6800/addversion.json
最后的addversion.json不能少
我们在本地安装pip install scrapy_client,安装完成后执行:scrapyd-deploy
zhaofandeMBP:zhihu_user zhaofan$ scrapyd-deploy
Packing version 1502177138
Deploying to project "zhihu_user" in http://192.168.1.9:6800/addversion.json
Server response (200):
{"node_name": "fan-VirtualBox", "status": "ok", "version": "1502177138", "spiders": 1, "project": "zhihu_user"} zhaofandeMBP:zhihu_user zhaofan$
看到status:200表示已经成功
关于常用操作API
listprojects.json列出上传的项目列表
zhaofandeMBP:zhihu_user zhaofan$ curl http://192.168.1.9:6800/listprojects.json
{"node_name": "fan-VirtualBox", "status": "ok", "projects": ["zhihu_user"]}
zhaofandeMBP:zhihu_user zhaofan$
listversions.json列出有某个上传项目的版本
zhaofandeMBP:zhihu_user zhaofan$ curl http://192.168.1.9:6800/listversions.json\?project\=zhihu_user
{"node_name": "fan-VirtualBox", "status": "ok", "versions": ["1502177138"]}
zhaofandeMBP:zhihu_user zhaofan$
schedule.json远程任务的启动
下面我们启动的三次就表示我们启动了三个任务,也就是三个调度任务来运行zhihu这个爬虫
zhaofandeMBP:zhihu_user zhaofan$ curl http://192.168.1.9:6800/schedule.json -d project=zhihu_user -d spider=zhihu
{"node_name": "fan-VirtualBox", "status": "ok", "jobid": "97f1b5027c0e11e7b07a080027bbde73"}
zhaofandeMBP:zhihu_user zhaofan$ curl http://192.168.1.9:6800/schedule.json -d project=zhihu_user -d spider=zhihu
{"node_name": "fan-VirtualBox", "status": "ok", "jobid": "99595aa87c0e11e7b07a080027bbde73"}
zhaofandeMBP:zhihu_user zhaofan$ curl http://192.168.1.9:6800/schedule.json -d project=zhihu_user -d spider=zhihu
{"node_name": "fan-VirtualBox", "status": "ok", "jobid": "9abb1ba27c0e11e7b07a080027bbde73"}
zhaofandeMBP:zhihu_user zhaofan$
同时当启动完成后,我们可以通过页面查看jobs,这里因为我远端服务器并没有安装scrapy_redis,所以显示任务是完成了,我点开日志并能看到详细的日志情况:

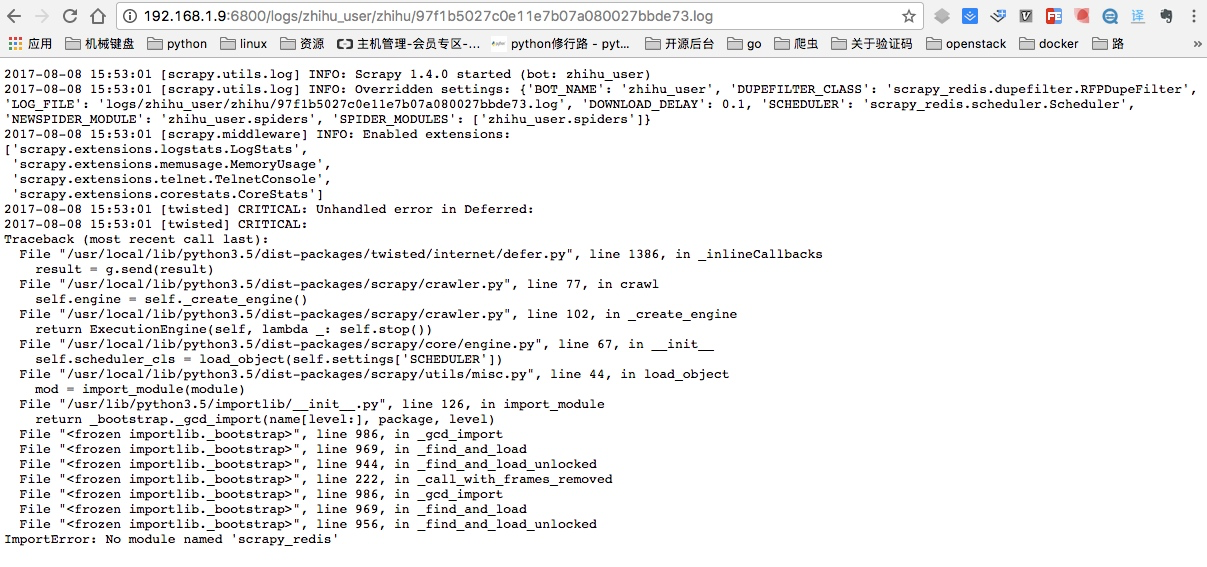
这里出错的原因就是我上面忘记在ubuntu虚拟机安装scrapy_redis以及pymongo模块,进行
pip install scrapy_redis pymongo安装后重新启动,就可以看到已经在运行的任务,同时点开Log日志也能看到爬取到的内容:
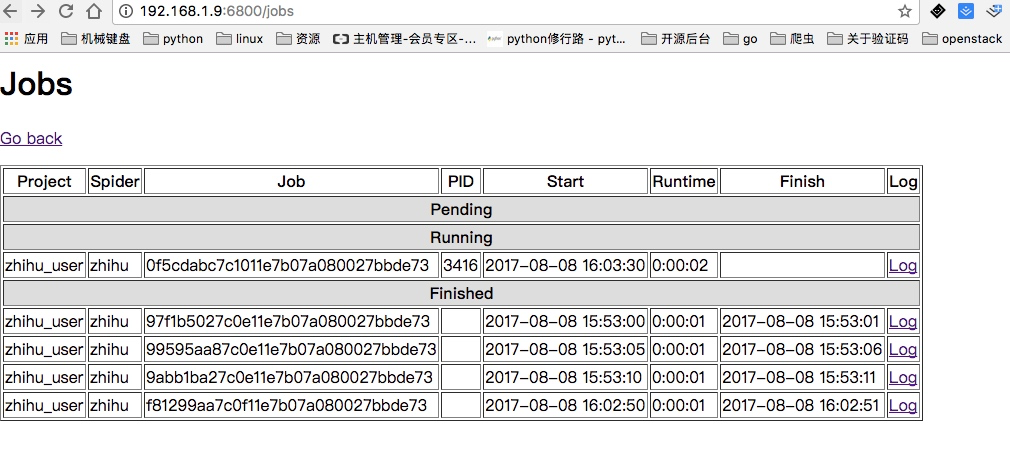
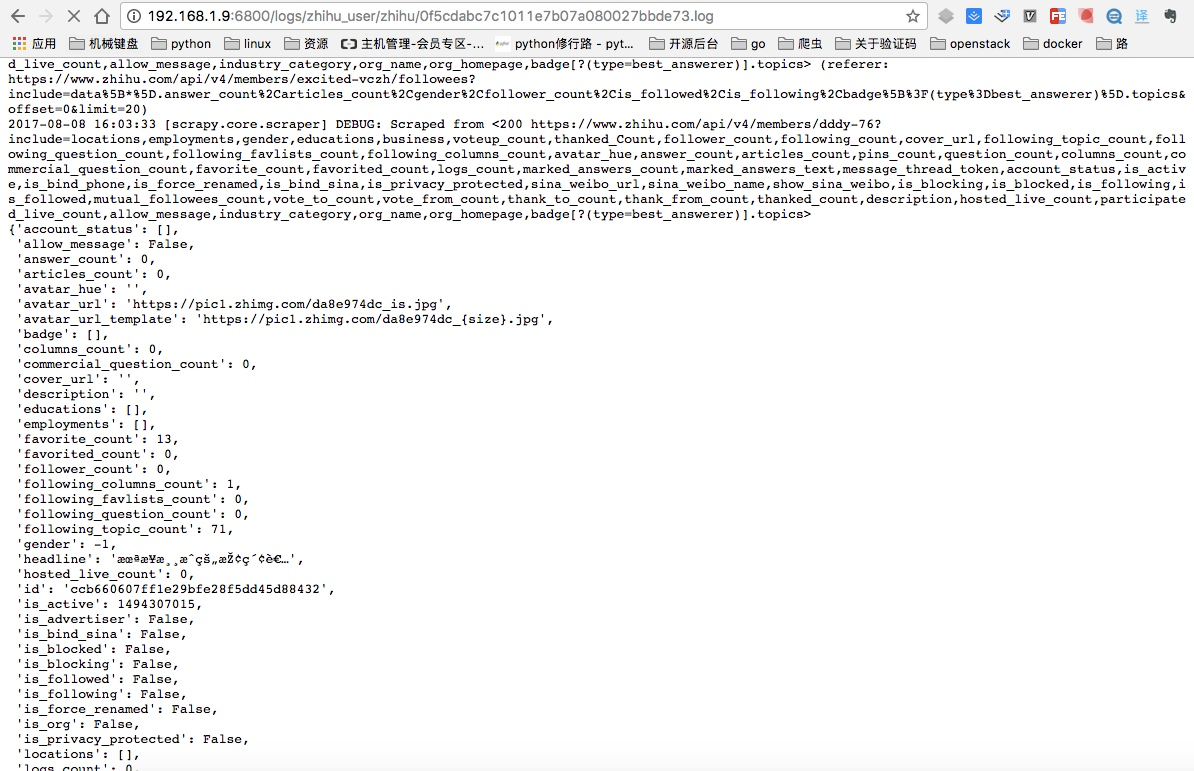
listjobs.json列出所有的jobs任务
上面是通过页面显示所有的任务,这里是通过命令获取结果
zhaofandeMBP:zhihu_user zhaofan$ curl http://192.168.1.9:6800/listjobs.json\?project\=zhihu_user
{"node_name": "fan-VirtualBox", "status": "ok", "running": [], "pending": [], "finished": [{"start_time": "2017-08-08 15:53:00.510050", "spider": "zhihu", "id": "97f1b5027c0e11e7b07a080027bbde73", "end_time": "2017-08-08 15:53:01.416139"}, {"start_time": "2017-08-08 15:53:05.509337", "spider": "zhihu", "id": "99595aa87c0e11e7b07a080027bbde73", "end_time": "2017-08-08 15:53:06.627125"}, {"start_time": "2017-08-08 15:53:10.509978", "spider": "zhihu", "id": "9abb1ba27c0e11e7b07a080027bbde73", "end_time": "2017-08-08 15:53:11.542001"}]}
zhaofandeMBP:zhihu_user zhaofan$
cancel.json取消所有运行的任务
这里可以将上面启动的所有jobs都可以取消:
zhaofandeMBP:zhihu_user zhaofan$ curl http://192.168.1.9:6800/cancel.json -d project=zhihu_user -d job=0f5cdabc7c1011e7b07a080027bbde73
{"node_name": "fan-VirtualBox", "status": "ok", "prevstate": "running"}
zhaofandeMBP:zhihu_user zhaofan$ curl http://192.168.1.9:6800/cancel.json -d project=zhihu_user -d job=63f8e12e7c1011e7b07a080027bbde73
{"node_name": "fan-VirtualBox", "status": "ok", "prevstate": "running"}
zhaofandeMBP:zhihu_user zhaofan$ curl http://192.168.1.9:6800/cancel.json -d project=zhihu_user -d job=63f8e12f7c1011e7b07a080027bbde73
{"node_name": "fan-VirtualBox", "status": "ok", "prevstate": "running"}
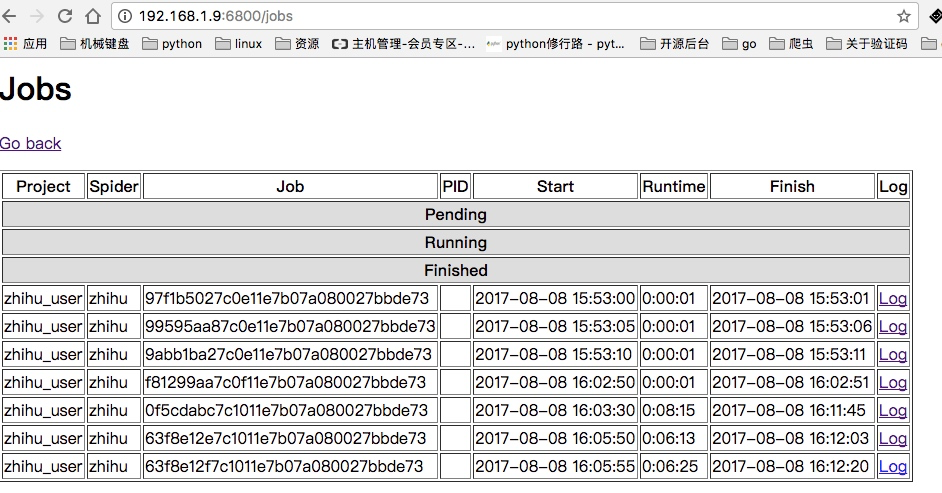
这样当我们再次通过页面查看,就可以看到所有的任务都是finshed状态:
我相信看了上面这几个方法你一定会觉得真不方便还需要输入那么长,所以有人替你干了件好事把这些API进行的再次封装:https://github.com/djm/python-scrapyd-api
关于python-scrapyd-api
该模块可以让我们直接在python代码中进行上述那些api的操作
首先先安装该模块:pip install python-scrapyd-api
使用方法如下,这里只演示了简单的例子,其他方法其实使用很简单按照规则写就行:
from scrapyd_api import ScrapydAPI
scrapyd = ScrapydAPI('http://192.168.1.9:6800')
res = scrapyd.list_projects()
res2 = scrapyd.list_jobs('zhihu_user')
print(res)
print(res2)
Cancel a scheduled job
scrapyd.cancel('project_name', '14a6599ef67111e38a0e080027880ca6')
Delete a project and all sibling versions
scrapyd.delete_project('project_name')
Delete a version of a project
scrapyd.delete_version('project_name', 'version_name')
Request status of a job
scrapyd.job_status('project_name', '14a6599ef67111e38a0e080027880ca6')
List all jobs registered
scrapyd.list_jobs('project_name')
List all projects registered
scrapyd.list_projects()
List all spiders available to a given project
scrapyd.list_spiders('project_name')
List all versions registered to a given project
scrapyd.list_versions('project_name')
Schedule a job to run with a specific spider
scrapyd.schedule('project_name', 'spider_name')
Schedule a job to run while passing override settings
settings = {'DOWNLOAD_DELAY': 2}
Schedule a job to run while passing extra attributes to spider initialisation
scrapyd.schedule('project_name', 'spider_name', extra_attribute='value')
Python之 爬虫(二十三)Scrapy分布式部署的更多相关文章
- Python之爬虫(二十二) Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- 【python 网络爬虫】之scrapy系列
网络爬虫之scripy系列 [scrapy网络爬虫]之0 爬虫与反扒 [scrapy网络爬虫]之一 scrapy框架简介和基础应用 [scrapy网络爬虫]之二 持久化操作 [scrapy网络爬虫]之 ...
- 爬虫(二)之scrapy框架
01-scrapy介绍 02-项目的目录结构: scrapy.cfg 项目的主配置信息.(真正爬虫相关的配置信息在settings.py 文件中) items.py 设置数据存储模板,用于结构化数据, ...
- Python爬虫从入门到放弃(二十一)之 Scrapy分布式部署
按照上一篇文章中我们将代码放到远程主机是通过拷贝或者git的方式,但是如果考虑到我们又多台远程主机的情况,这种方式就比较麻烦,那有没有好用的方法呢?这里其实可以通过scrapyd,下面是这个scrap ...
- 爬虫(十八):scrapy分布式部署
scrapy部署神器-scrapyd -->GitHub地址 -->官方文档 一:安装scrapyd 安装:pip3 install scrapyd 这里我在另外一台ubuntu lin ...
- Python爬虫(二十三)_selenium案例:动态模拟页面点击
本篇主要介绍使用selenium模拟点击下一页,更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import unittest from selenium impor ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
- python简单爬虫(二)
上一篇简单的实现了获取url返回的内容,在这一篇就要第返回的内容进行提取,并将结果保存到html中. 一 . 需求: 抓取主页面:百度百科Python词条 https://baike.baidu. ...
- python网络爬虫(10)分布式爬虫爬取静态数据
目的意义 爬虫应该能够快速高效的完成数据爬取和分析任务.使用多个进程协同完成一个任务,提高了数据爬取的效率. 以百度百科的一条为起点,抓取百度百科2000左右词条数据. 说明 参阅模仿了:https: ...
随机推荐
- Node.js环境安装
为其他使用先小小的接触这个环境,如不出意外,未来的一些时候抽时间会系统的学习element-ui, JavaScript, vue, node.js, 稍后也做个简易的ACE Editor体验一下 1 ...
- 4a-c++ primer宽字符wchar_t显示设置与输出代码示例
.. #include <iostream> #include <windows.h> #include <locale> //#include<wchar. ...
- 3.kubernetes的CNI网络插件-Flannel
目录 1.1.K8S的CNI网络插件-Flannel 1.1.1.集群规划 1.1.2.下载软件.解压.软链接 1.1.3.最终目录结构 1.1.4.拷贝证书 1.1.5.创建配置 1.1.6.创建启 ...
- vue 框架,入门必看
vue 的 入门 el 的挂载点: el 是用来设置vue实例挂载,(管理)的元素 vue会管理el选项命中的元素以及内部的后代元素 可以使用其他的选择器,但是不建议使用ID选择器 可以使用其他的双标 ...
- JAVA设计模式 2【创建型】原型模式的理解与使用
在本节中,我们将学习和使用原型模式:这一节学习的原型模式也是创建型 模式的其中之一.再次复习一下:创建型 模式就是描述如何去更好的创建一个对象. 我们都知道,在JAVA 语言中.使用new 关键字创建 ...
- opencv C++构造并访问单通道和多通道Mat。
一:构造并访问单通道. int main(){ cv::Mat m=(cv::Mat_<int>(3,2)<<1,2,3,4,5,6); for(int i=0;i<m. ...
- 从零开始手把手教你使用原生JS+CSS3实现幸运水果机游戏
项目体验地址 免费视频教程 游戏介绍 幸运水果机是一款街机游戏,游戏界面由24个方格拼接成一个正方形,每个方格中都有一个不同的水果图形,方格下都有一个小灯.玩家使用游戏币选择希望押注的目标,按下开始后 ...
- EnvironmentPostProcessor
概览 SpringBoot支持动态的读取文件,留下的扩展接口 org.springframework.boot.env.EnvironmentPostProcessor,进行配置文件的集中管理,从而避 ...
- webpack4.*入门笔记
全是跟着示例做的.看下面文章 入门 1.nodejs基础 http://www.runoob.com/nodejs/nodejs-tutorial.html 2.NPM 学习笔记整理 https:// ...
- ajax前后端交互原理(5)
5.ajax简介 5.1.什么是ajax Asynchronous JavaScript and XML ,异步的javascript和XML 5.2.使用ajax有什么用 数据交互,可以从服务器获取 ...