python生成器原理剖析
python生成器原理剖析
函数的调用满足“后进先出”的原则,也就是说,最后被调用的函数应该第一个返回,函数的递归调用就是一个经典的例子。显然,内存中以“后进先出”方式处理数据的栈段是最适合用于实现函数调用的载体,在编译型程序语言中,函数被调用后,函数的参数,返回地址,寄存器值等数据会被压入栈,待函数体执行完毕,将上述数据弹出栈。这也意味着,一个被调用的函数一旦执行完毕,它的生命周期就结束了。
在python这样的解释型语言中,函数的调用也是依赖栈的。之前说过,python的标准解释器是用C写的。解释器用一个叫做PyEval_EvalFrameEx的C函数来执行python程序。对于一个python中的函数,解释器接受一个python的栈帧对象,并在这个栈帧的上下文中执行python字节码。
我们来看看这样一个例子:
import dis
def foo():
bar()
def bar():
pass
print(dis.dis(foo))
我们用dis模块可以查看python程序的字节码,下面是函数foo()的字节码:
0 LOAD_GLOBAL 0 (bar)
2 CALL_FUNCTION 0
4 POP_TOP
6 LOAD_CONST 0 (None)
8 RETURN_VALUE
foo函数将bar加载到栈中并调用它,然后从栈中弹出返回值,最后加载并返回None,当PyEval_EvalFrameEx遇到CALL_FUNCTION字节码的时候,它会创建一个新的python栈帧,然后用这个新的帧作为参数递归调用PyEval_EvalFrameEx来执行bar。不过有一点要注意的是,python解释器是个普通的C程序,所以它的堆栈帧就是普通的堆栈。但是它操作的python堆栈帧是分配在堆上的,所以python的栈帧可以在它的调用之外存活。而且可以显式的保存下来。
这是python生成器的技术基础,下面是一个生成器:
def gen():
yield 1
yield 2
g = gen()
next(g)
print(type(g))
返回的结果是:
<class 'generator'>
调用gen()产生的所有生成器都指向同一个代码对象,但是每个都有自己的堆栈帧。这个堆栈帧并不存在于实际的堆栈上,它在堆内存上等待着被使用。
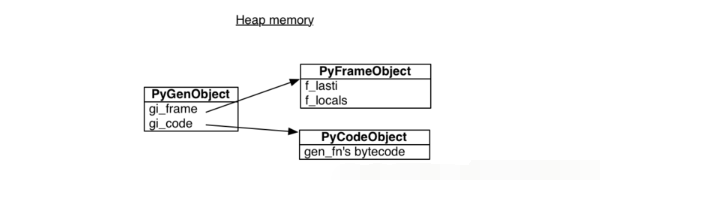
堆栈帧有个“last instruction”指针,指向最近执行的那条指令。刚开始的时候last instruction指针是-1意味着生成器尚未开始,这就是为什么上面的例子中有next(g)这行代码。生成器可以在任何时候被任何函数恢复执行,因为它的栈帧实际上不在栈上而是在堆上。生成器在调用调用层次结构中的位置不是固定的,也不需要遵循常规函数执行时遵循的先进后出顺序。因为这些特性,生成器不仅能用于生成可迭代对象,还可以用于实现多任务协作。
python生成器原理剖析的更多相关文章
- Python字符串原理剖析------万恶的+号
字符串原理剖析pyc文件,执行python代码时,如果导入了其他的.py文件,那么执行过程中会自动生成一个与其同名的.pyc文件,该文件就是python解释器变异之后产生的字节码 PS:代码经过编译可 ...
- 分布式全局ID生成器原理剖析及非常齐全开源方案应用示例
为何需要分布式ID生成器 **本人博客网站 **IT小神 www.itxiaoshen.com **拿我们系统常用Mysql数据库来说,在之前的单体架构基本是单库结构,每个业务表的ID一般从1增,通过 ...
- 【python之路29】python生成器generator与迭代器
一.python生成器 python生成器原理: 只要函数中存在yield,则函数就变为生成器函数 #!usr/bin/env python # -*- coding:utf-8 -*- def xr ...
- 推荐《深入浅出深度学习原理剖析与python实践》PDF+代码
<深入浅出深度学习原理剖析与Python实践>介绍了深度学习相关的原理与应用,全书共分为三大部分,第一部分主要回顾了深度学习的发展历史,以及Theano的使用:第二部分详细讲解了与深度学习 ...
- 深入浅出深度学习:原理剖析与python实践_黄安埠(著) pdf
深入浅出深度学习:原理剖析与python实践 目录: 第1 部分 概要 1 1 绪论 2 1.1 人工智能.机器学习与深度学习的关系 3 1.1.1 人工智能——机器推理 4 1.1.2 机器学习—— ...
- python——生成器
python——生成器 通过列表生成式,我们可以直接创建一个列表.但是,受到内存限制,列表容量肯定是有限的.而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个 ...
- MapReduce/Hbase进阶提升(原理剖析、实战演练)
什么是MapReduce? MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)",和他们 ...
- 开源 serverless 产品原理剖析 - Kubeless
背景 Serverless 架构的出现让开发者不用过多地考虑传统的服务器采购.硬件运维.网络拓扑.资源扩容等问题,可以将更多的精力放在业务的拓展和创新上. 随着 serverless 概念的深入人心, ...
- ARouter原理剖析及手动实现
ARouter原理剖析及手动实现 前言 路由跳转在项目中用了一段时间了,最近对Android中的ARouter路由原理也是研究了一番,于是就给大家分享一下自己的心得体会,并教大家如何实现一款简易的路由 ...
随机推荐
- SQL中游标的使用示例
declare @email_source varchar(MAX); --1.原始发件人字段 declare @key_name varchar(50); --2.我方卷号或客户代码 declare ...
- navicat 出现 mysql远程连接问题 Lost connection to MySQL server at ‘reading initial communication packet', system error: 0
今天做服务器上的东西需要看数据库时,突然发现有这个报错,然后自己也查了很多资料 我最后找到一个在my,cnf配置文件中mysqld下加入一条 max_allowed_packet = 500M 也就是 ...
- CODING DevOps 系列第三课:云计算、云原生模式下 DevOps 的建设
本文首先会和大家分享当前整个应用生命周期的演变历程,然后讲解云计算模式下 DevOps 建设包含的过程.流程规范和标准,最后讲解云原生时代到来会带来哪些改变,以及标准化的建设会有哪些改变和突破. 应用 ...
- WeChair项目Beta冲刺(10/10)
团队项目进行情况 1.昨日进展 Beta冲刺第十天 昨日进展: 项目完工 2.今日安排 对小程序进行测试,同时对项目进行总结,并整理博客材料等 3.燃尽图 4.展示Git当日代码记录 详情 ...
- VMware Workstation 15密钥
在打开的VMware Workstation 15输入许可证密钥对话框里直接输入25位密钥,然后点击确定,如下图所示. 这里提供一个密钥: CG392-4PX5J-H816Z-HYZNG-PQRG2
- 5、struct2使用登陆的时候重定向功能,如果没有登陆,重定向到登陆页面
1.实现这样一份功能,列如用户在进行某些操作的时候,如果没有登陆重定向到登陆页面 首先:我们创建一个功能操作页面,用户准备在该页面执行某些操作 在index.jsp中 <%@ page lang ...
- 重学 Java 设计模式:实战迭代器模式「模拟公司组织架构树结构关系,深度迭代遍历人员信息输出场景」
作者:小傅哥 博客:https://bugstack.cn - 原创系列专题文章 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 相信相信的力量! 从懵懂的少年,到拿起键盘,可以写一个Hell ...
- Spring IoC component-scan 节点详解
前言 我们在了解 Spring 容器的扩展功能 (ApplicationContext) 之前,先介绍下 context:component-scan 标签的解析过程,其作用很大是注解能生效的关键所在 ...
- Codeforces Round #652 (Div. 2) 总结
A:问正n边形的一条边和x轴平行的时候有没有一条边和y轴重合,直接判断n是否是4的倍数 #include <iostream> #include <cstdio> #inclu ...
- Android 错误异常之Error:Unable to resolve dependency for ':app@debug/compileClasspath': Could。。。。
这个错误一般出现在导入别人的项目的时候出现的, 我出错原因是,as版本3.5.2用了几个月感觉不如3.0.1的带劲,so 该到了3.0.1 ,出现了这个错, 之前也遇到过,基本都是gradle版本的错 ...