彻底搞懂MySQL为什么要使用B+树索引
搞懂这个问题之前,我们首先来看一下,MySQL表的存储结构
MySQL的存储结构
表存储结构
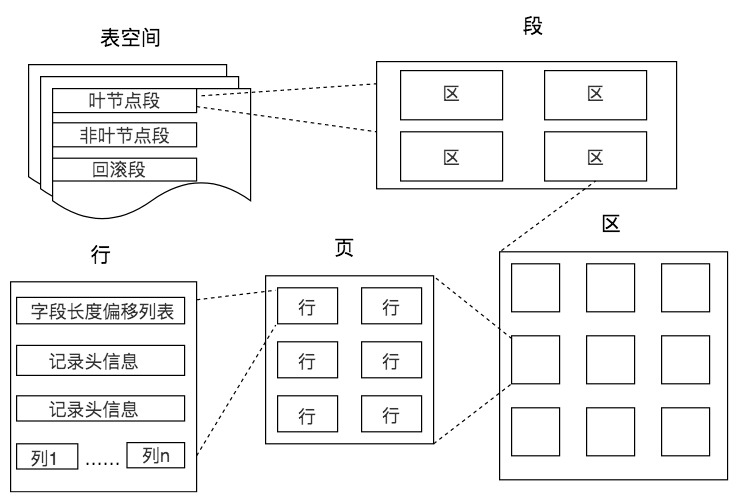
单位:表>段>区>页>行
在数据库中, 不论读一行,还是读多行,都是将这些行所在的页进行加载。也就是说存储空间的基本单位是页。
一个页就是一棵树B+树的节点,数据库I/O操作的最小单位是页,与数据库相关的内容都会存储在页的结构里。
B+树索引结构
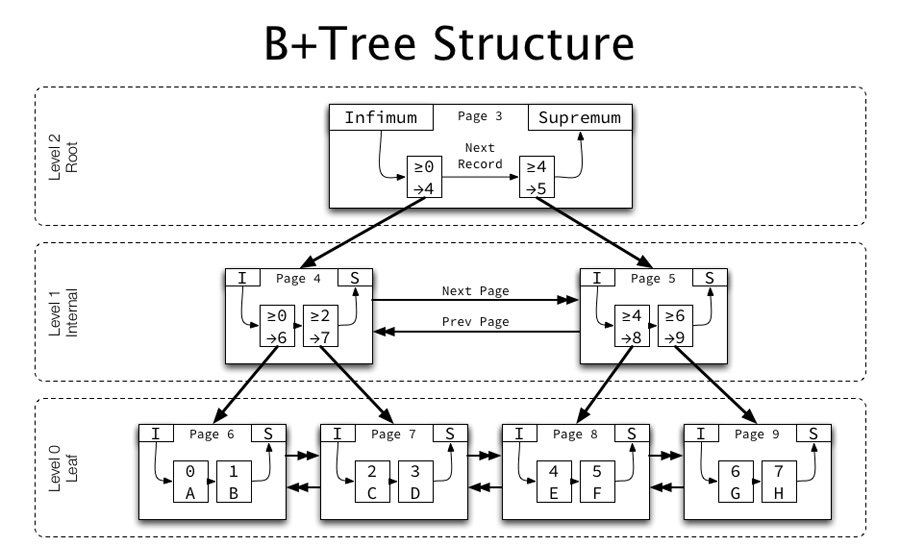
- 在一棵B+树中,每个节点为都是一个页,每次新建节点的时候,就会申请一个页空间
- 同一层的节点为之间,通过页的结构构成了一个双向链表
- 非叶子节点为,包括了多个索引行,每个索引行里存储索引键和指向下一层页面的指针
- 叶子节点为,存储了关键字和行记录,在节点内部(也就是页结构的内部)记录之间是一个单向的表
B+树页节点结构
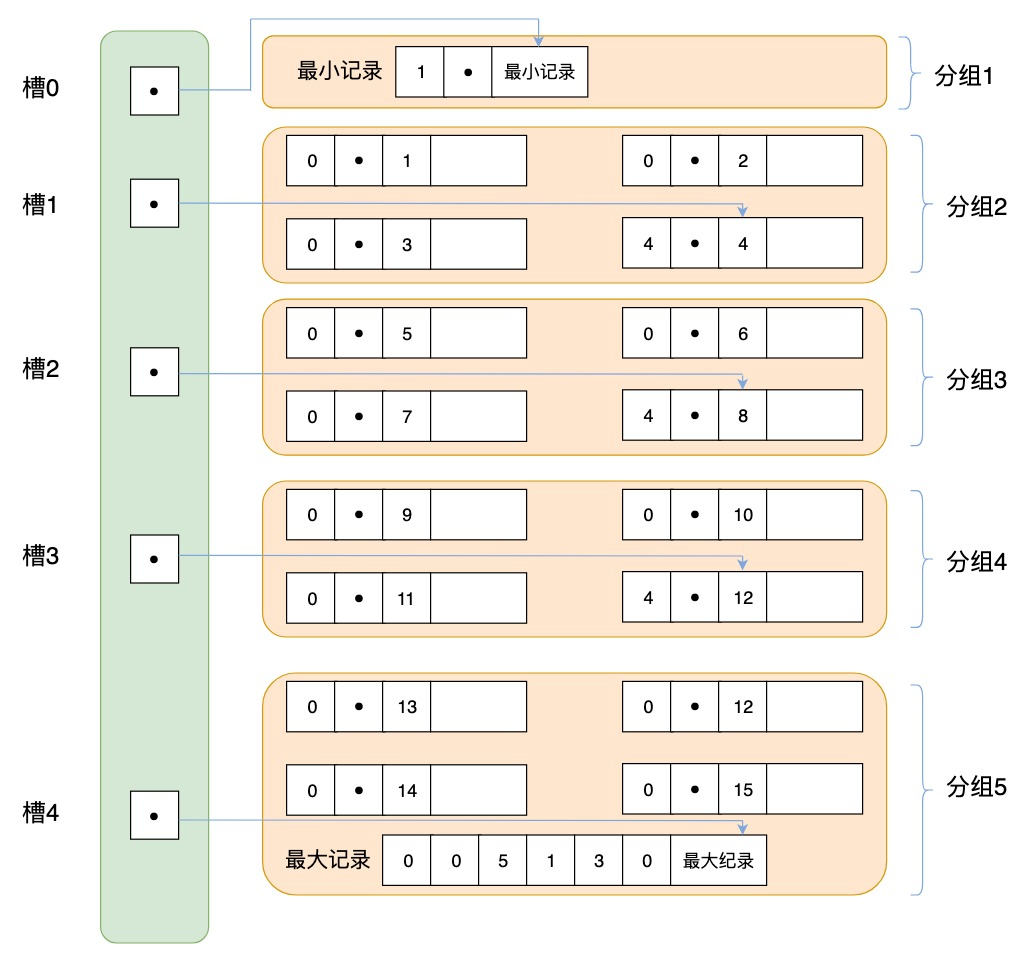
有以下几个特点
- 将所有的记录分成几个组, 每组会存储多条记录,
- 页目录存储的是槽(slot),槽相当于分组记录的索引,每个槽指针指向了不同组的最后一个记录
- 我们通过槽定位到组,再查看组中的记录
页的主要作用是存储记录,在页中记录以单链表的形式进行存储。
单链表优点是插入、删除方便,缺点是检索效率不高,最坏的情况要遍历链表所有的节点。因此页目录中提供了二分查找的方式,来提高记录的检索效率。
为什么要用B+树索引
数据库访问数据要通过页,一个页就是一个B+树节点,访问一个节点相当于一次I/O操作,所以越快能找到节点,查找性能越好。
B+树的特点就是够矮够胖,能有效地减少访问节点次数从而提高性能。
下面,我们来对比一个二叉树、多叉树、B树和B+树。
二叉树
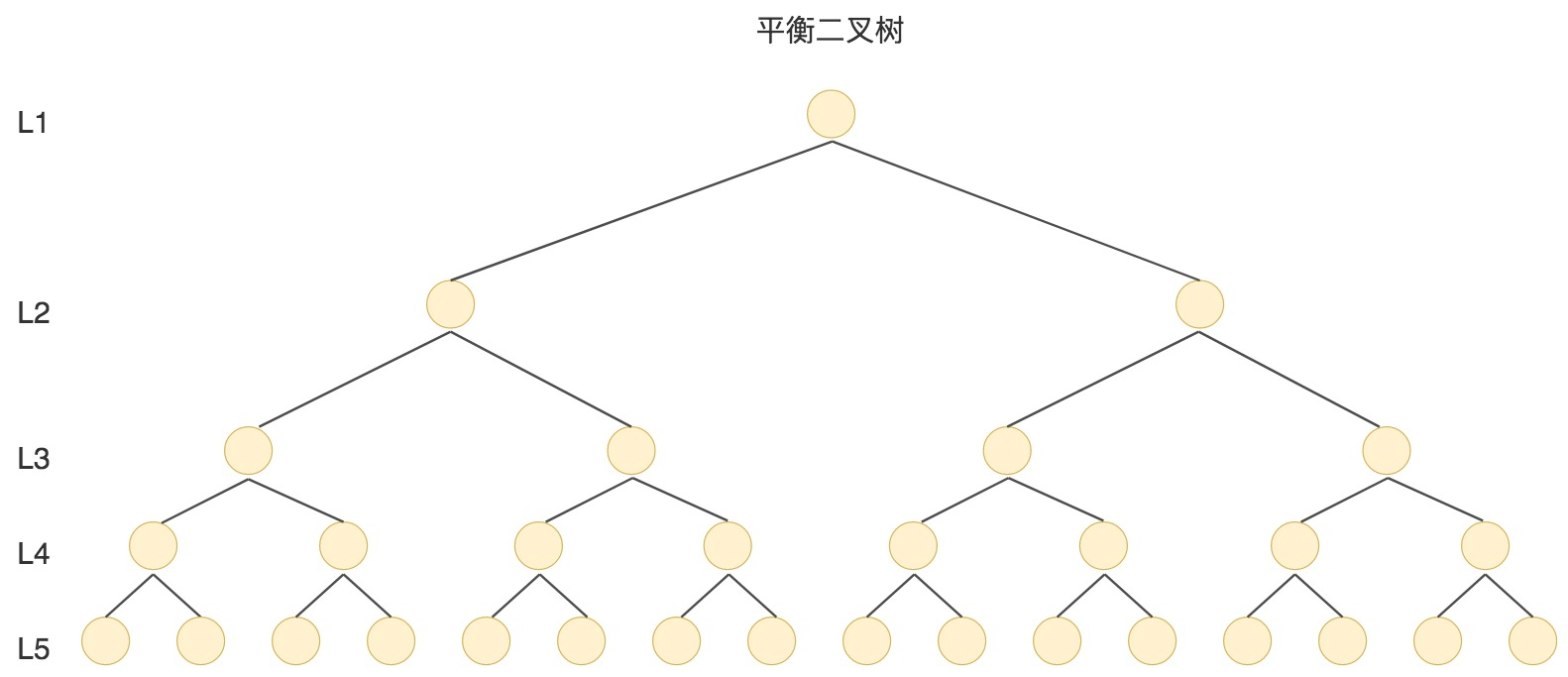
二叉树是一种二分查找树,有很好的查找性能,相当于二分查找。
但是当N比较大的时候,树的深度比较高。数据查询的时间主要依赖于磁盘IO的次数,二叉树深度越大,查找的次数越多,性能越差。
最坏的情况是退化成了链表,如下图

为了让二叉树不至于退化成链表,人们发明了AVL树(平衡二叉搜索树):任何结点的左子树和右子树高度最多相差1
多叉树
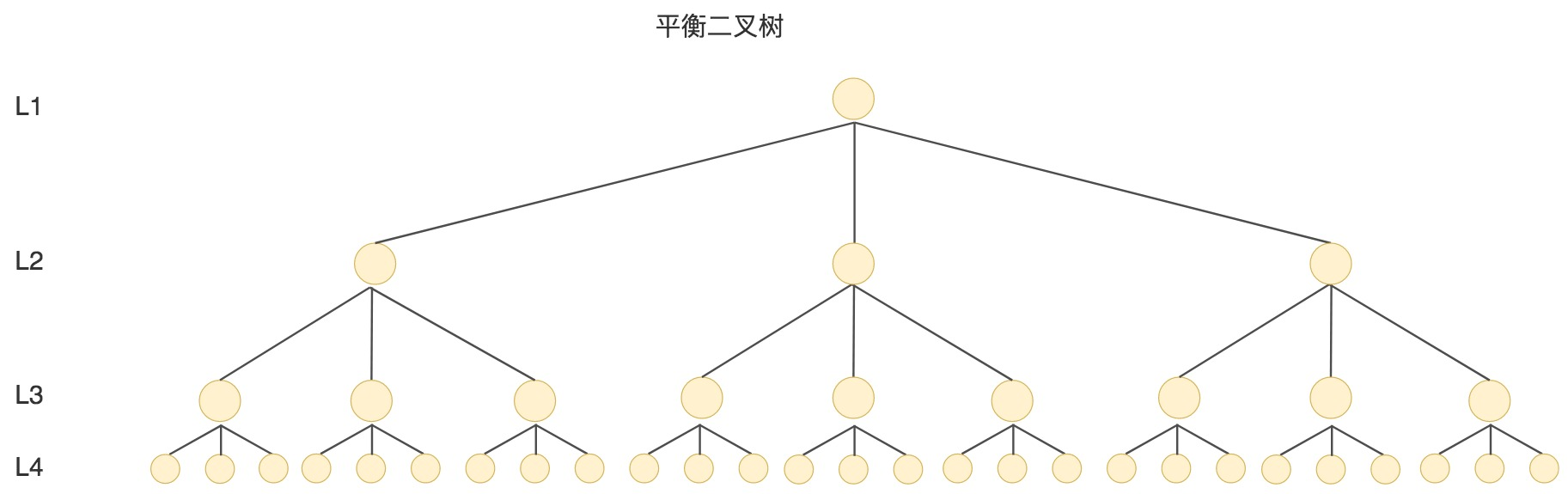
多叉树就是节点可以是M个,能有效地减少高度,高度变小后,节点变少I/O自然少,性能比二叉树好了
B树
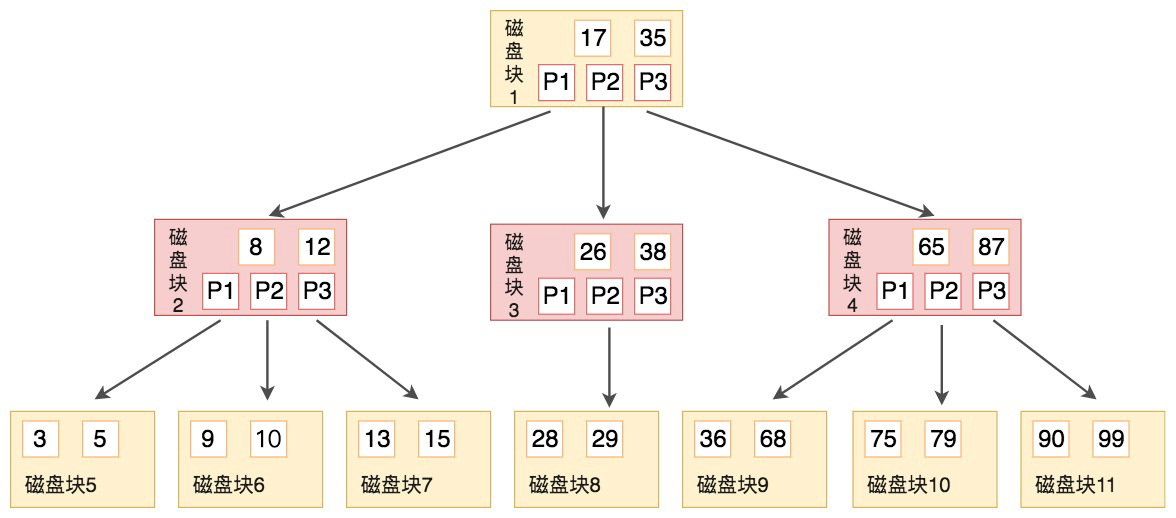
B树简单地说就是多叉树,每个叶子会存储数据,和指向下一个节点的指针。
例如要查找9,步骤如下
- 我们与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;
- 按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;
- 按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。
B+树

B+树是B树的改进,简单地说是:只有叶子节点才存数据,非叶子节点是存储的指针;所有叶子节点构成一个有序链表
例如要查找关键字16,步骤如下
- 与根节点的关键字 (1,18,35) 进行比较,16 在 1 和 18 之间,得到指针 P1(指向磁盘块 2)
- 找到磁盘块 2,关键字为(1,8,14),因为 16 大于 14,所以得到指针 P3(指向磁盘块 7)
- 找到磁盘块 7,关键字为(14,16,17),然后我们找到了关键字 16,所以可以找到关键字 16 所对应的数据。
B+树与B树的不同:
- B+树非叶子节点不存在数据只存索引,B树非叶子节点存储数据
- B+树使用双向链表串连所有叶子节点,区间查询效率更高,因为所有数据都在B+树的叶子节点,但是B树则需要通过中序遍历才能完成查询范围的查找。
- B+树每次都必须查询到叶子节点才能找到数据,而B树查询的数据可能不在叶子节点,也可能在,这样就会造成查询的效率的不稳定
- B+树查询效率更高,因为B+树矮更胖,高度小,查询产生的I/O最少。
这就是MySQL使用B+树的原因,就是这么简单!
彻底搞懂MySQL为什么要使用B+树索引的更多相关文章
- 搞懂MySQL InnoDB B+树索引
一.InnoDB索引 InnoDB支持以下几种索引: B+树索引 全文索引 哈希索引 本文将着重介绍B+树索引.其他两个全文索引和哈希索引只是做简单介绍一笔带过. 哈希索引是自适应的,也就是说这个不能 ...
- 一本彻底搞懂MySQL索引优化EXPLAIN百科全书
1.MySQL逻辑架构 日常在CURD的过程中,都避免不了跟数据库打交道,大多数业务都离不开数据库表的设计和SQL的编写,那如何让你编写的SQL语句性能更优呢? 先来整体看下MySQL逻辑架构图: M ...
- 程序员必须了解的知识点——你搞懂mysql索引机制了吗?
一.索引是什么 MySQL官方对索引的定义为:索引(Index)是帮助MySQL 高效 获取数据的数据结构,而MYSQL使用的数据结构是:B+树 在这里推荐大家看一本书,<深入理解计算机系统的书 ...
- 一文搞懂MySQL体系架构!!
写在前面 很多小伙伴工作很长时间了,对于MySQL的掌握程度却仅仅停留在表面的CRUD,对于MySQL深层次的原理和技术知识了解的少之又少,随着工作年限的不断增长,职场竞争力却是不断降低的.很多时候, ...
- 一分钟掌握MySQL的InnoDB引擎B+树索引
MySQL的InnoDB索引结构采用B+树,B+树什么概念呢,二叉树大家都知道,我们都清楚随着叶子结点的不断增加,二叉树的高度不断增加,查找某一个节点耗时就会增加,性能就会不断降低,B+树就是解决这个 ...
- 搞懂MySQL GTID原理
从MySQL 5.6.5 开始新增了一种基于 GTID 的复制方式.通过 GTID 保证了每个在主库上提交的事务在集群中有一个唯一的ID.这种方式强化了数据库的主备一致性,故障恢复以及容错能力. GT ...
- 五分钟搞懂MySQL索引下推
大家好,我是老三,今天分享一个小知识点--索引下推. 如果你在面试中,听到MySQL5.6"."索引优化" 之类的词语,你就要立马get到,这个问的是"索引下推 ...
- 一文彻底搞懂MySQL分区
一个执着于技术的公众号 一.InnoDB逻辑存储结构 首先要先介绍一下InnoDB逻辑存储结构和区的概念,它的所有数据都被逻辑地存放在表空间,表空间又由段,区,页组成. 段 段就是上图的segment ...
- 一文搞懂mysql索引底层逻辑,干货满满!
一.什么是索引 在mysql中,索引是一种特殊的数据库结构,由数据表中的一列或多列组合而成,可以用来快速查询数据表中有某一特定值的记录.通过索引,查询数据时不用读完记录的所有信息,而只是查询索引列即可 ...
随机推荐
- Day2 之 元组tuple
tuple 元组 也是有序列表 ,与list非常相似,但是tuple一旦初始化就不能修改. name = ('a','b',1,2,3,True) tuple ...
- sql 语句使用和转换json数据
1 连接mysql import pymysql import concurrent coon=pymysql.connect(host='localhost',user='root',passwor ...
- Unity 3D里相机的平滑跟随(转)
1 using System.Collections; 2 using System.Collections.Generic; 3 using UnityEngine; 4 public class ...
- 网络 IO 模型简单介绍
一.同步阻塞 IO(BIO) 当用户线程调用了 read 系统调用,内核(kernel)就开始了 IO 的第一个阶段:准备数据.很多时候,数据在一开始还没有到达(比如,还没有收到一个完整的Socket ...
- oracle 常用语句3
- oracle 函数 select sign(-3),sign(3), sign(0) from dual; select ceil(3.7) from dual; select floor(3.7 ...
- CMake将生成的可执行文件保存到其他目录
在运行一些程序的时候,我们一般会把数据文件放在其他位置.而当在修改程序时,需要不断的修改代码,编译,执行.每次编译之后,都得将可执行文件复制到数据文件的目录. 这一问题有两种解决方法,一是直接在数据目 ...
- 网站开发学习Python实现-Django学习-介绍(6.1.1)
@ 目录 1.MVT 2.ORM 关于作者 1.MVT 主要的目的是为了快速,简便的开发数据库驱动的网站,强调代码的复用,多个组件可以很方便以插件的方式服务于整个框架,采用的是MVT设计模式(差不多的 ...
- 【学习笔记】分布式追踪Tracing
在软件工程中,Tracing指使用特定的日志记录程序的执行信息,与之相近的还有两个概念,它们分别是Logging和Metrics. Logging:用于记录离散的事件,包含程序执行到某一点或某一阶段的 ...
- BST和DST简单的matlab程序(图的广度和深度遍历)
图的广度和深度遍历,具体内容教材有 clc;clear all;close all; %初始化邻接压缩表compressTable=[1 2;1 3;1 4;2 4;2 5;3 6;4 6;4 7]; ...
- DateUtils 时间工具类
首先,定义`时间枚举值` public enum TimeEnum { /** * 时间格式 */ YYYY_MM_DD("yyyy-MM-dd"), YYYY_MM_DD_HH_ ...