分布式ID生成服务,真的有必要搞一个
目录
- 阐述背景
- Leaf snowflake 模式介绍
- Leaf segment 模式介绍
- Leaf 改造支持RPC
阐述背景
不吹嘘,不夸张,项目中用到ID生成的场景确实挺多。比如业务要做幂等的时候,如果没有合适的业务字段去做唯一标识,那就需要单独生成一个唯一的标识,这个场景相信大家不陌生。
很多时候为了涂方便可能就是写一个简单的ID生成工具类,直接开用。做的好点的可能单独出一个Jar包让其他项目依赖,做的不好的很有可能就是Copy了N份一样的代码。
单独搞一个独立的ID生成服务非常有必要,当然我们也没必要自己做造轮子,有现成开源的直接用就是了。如果人手够,不差钱,自研也可以。
今天为大家介绍一款美团开源的ID生成框架Leaf,在Leaf的基础上稍微扩展下,增加RPC服务的暴露和调用,提高ID获取的性能。
Leaf介绍
Leaf 最早期需求是各个业务线的订单ID生成需求。在美团早期,有的业务直接通过DB自增的方式生成ID,有的业务通过redis缓存来生成ID,也有的业务直接用UUID这种方式来生成ID。以上的方式各自有各自的问题,因此我们决定实现一套分布式ID生成服务来满足需求。
具体Leaf 设计文档见:https://tech.meituan.com/2017/04/21/mt-leaf.html
目前Leaf覆盖了美团点评公司内部金融、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。在4C8G VM基础上,通过公司RPC方式调用,QPS压测结果近5w/s,TP999 1ms。
snowflake模式
snowflake是Twitter开源的分布式ID生成算法,被广泛应用于各种生成ID的场景。Leaf中也支持这种方式去生成ID。
使用步骤如下:
修改配置leaf.snowflake.enable=true开启snowflake模式。
修改配置leaf.snowflake.zk.address和leaf.snowflake.port为你自己的Zookeeper地址和端口。
想必大家很好奇,为什么这里依赖了Zookeeper呢?
那是因为snowflake的ID组成中有10bit的workerId,如下图:
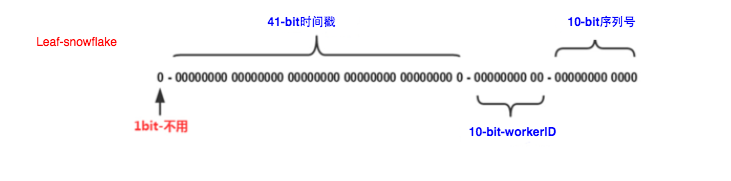
一般如果服务数量不多的话手动设置也没问题,还有一些框架中会采用约定基于配置的方式,比如基于IP生成wokerID,基于hostname最后几位生成wokerID,手动在机器上配置,手动在程序启动时传入等等方式。
Leaf中为了简化wokerID的配置,所以采用了Zookeeper来生成wokerID。就是用了Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。
如果你公司没有用Zookeeper,又不想因为Leaf去单独部署Zookeeper的话,你可以将源码中这块的逻辑改掉,比如自己提供一个生成顺序ID的服务来替代Zookeeper。
segment模式
segment是Leaf基于数据库实现的ID生成方案,如果调用量不大,完全可以用Mysql的自增ID来实现ID的递增。
Leaf虽然也是基于Mysql,但是做了很多的优化,下面简单的介绍下segment模式的原理。
首先我们需要在数据库中新增一张表用于存储ID相关的信息。
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
biz_tag用于区分业务类型,比如下单,支付等。如果以后有性能需求需要对数据库扩容,只需要对biz_tag分库分表就行。
max_id表示该biz_tag目前所被分配的ID号段的最大值。
step表示每次分配的号段长度。
下图是segment的架构图:

从上图我们可以看出,当多个服务同时对Leaf进行ID获取时,会传入对应的biz_tag,biz_tag之间是相互隔离的,互不影响。
比如Leaf有三个节点,当test_tag第一次请求到Leaf1的时候,此时Leaf1的ID范围就是1~1000。
当test_tag第二次请求到Leaf2的时候,此时Leaf2的ID范围就是1001~2000。
当test_tag第三次请求到Leaf3的时候,此时Leaf3的ID范围就是2001~3000。
比如Leaf1已经知道自己的test_tag的ID范围是1~1000,那么后续请求过来获取test_tag对应ID时候,就会从1开始依次递增,这个过程是在内存中进行的,性能高。不用每次获取ID都去访问一次数据库。
问题一
这个时候又有人说了,如果并发量很大的话,1000的号段长度一下就被用完了啊,此时就得去申请下一个范围,这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。
放心,Leaf中已经对这种情况做了优化,不会等到ID消耗完了才去重新申请,会在还没用完之前就去申请下一个范围段。并发量大的问题你可以直接将step调大即可。
问题二
这个时候又有人说了,如果Leaf服务挂掉某个节点会不会有影响呢?
首先Leaf服务是集群部署,一般都会注册到注册中心让其他服务发现。挂掉一个没关系,还有其他的N个服务。问题是对ID的获取有问题吗? 会不会出现重复的ID呢?
答案是没问题的,如果Leaf1挂了的话,它的范围是11000,假如它当前正获取到了100这个阶段,然后服务挂了。服务重启后,就会去申请下一个范围段了,不会再使用11000。所以不会有重复ID出现。
Leaf改造支持RPC
如果你们的调用量很大,为了追求更高的性能,可以自己扩展一下,将Leaf改造成Rpc协议暴露出去。
首先将Leaf的Spring版本升级到5.1.8.RELEASE,修改父pom.xml即可。
<spring.version>5.1.8.RELEASE</spring.version>
然后将Spring Boot的版本升级到2.1.6.RELEASE,修改leaf-server的pom.xml。
<spring-boot-dependencies.version>2.1.6.RELEASE</spring-boot-dependencies.version>
还需要在leaf-server的pom中增加nacos相关的依赖,因为我们kitty-cloud是用的nacos。同时还需要依赖dubbo,才可以暴露rpc服务。
<dependency>
<groupId>com.cxytiandi</groupId>
<artifactId>kitty-spring-cloud-starter-nacos</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.cxytiandi</groupId>
<artifactId>kitty-spring-cloud-starter-dubbo</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
</dependency>
在resource下创建bootstrap.properties文件,增加nacos相关的配置信息。
spring.application.name=LeafSnowflake
dubbo.scan.base-packages=com.sankuai.inf.leaf.server.controller
dubbo.protocol.name=dubbo
dubbo.protocol.port=20086
dubbo.registry.address=spring-cloud://localhost
spring.cloud.nacos.discovery.server-addr=47.105.66.210:8848
spring.cloud.nacos.config.server-addr=${spring.cloud.nacos.discovery.server-addr}
Leaf默认暴露的Rest服务是LeafController中,现在的需求是既要暴露Rest又要暴露RPC服务,所以我们抽出两个接口。一个是Segment模式,一个是Snowflake模式。
Segment模式调用客户端
/**
* 分布式ID服务客户端-Segment模式
*
* @作者 尹吉欢
* @个人微信 jihuan900
* @微信公众号 猿天地
* @GitHub https://github.com/yinjihuan
* @作者介绍 http://cxytiandi.com/about
* @时间 2020-04-06 16:20
*/
@FeignClient("${kitty.id.segment.name:LeafSegment}")
public interface DistributedIdLeafSegmentRemoteService {
@RequestMapping(value = "/api/segment/get/{key}")
String getSegmentId(@PathVariable("key") String key);
}
Snowflake模式调用客户端
/**
* 分布式ID服务客户端-Snowflake模式
*
* @作者 尹吉欢
* @个人微信 jihuan900
* @微信公众号 猿天地
* @GitHub https://github.com/yinjihuan
* @作者介绍 http://cxytiandi.com/about
* @时间 2020-04-06 16:20
*/
@FeignClient("${kitty.id.snowflake.name:LeafSnowflake}")
public interface DistributedIdLeafSnowflakeRemoteService {
@RequestMapping(value = "/api/snowflake/get/{key}")
String getSnowflakeId(@PathVariable("key") String key);
}
使用方可以根据使用场景来决定用RPC还是Http进行调用,如果用RPC就@Reference注入Client,如果要用Http就用@Autowired注入Client。
最后改造LeafController同时暴露两种协议即可。
@Service(version = "1.0.0", group = "default")
@RestController
public class LeafController implements DistributedIdLeafSnowflakeRemoteService, DistributedIdLeafSegmentRemoteService {
private Logger logger = LoggerFactory.getLogger(LeafController.class);
@Autowired
private SegmentService segmentService;
@Autowired
private SnowflakeService snowflakeService;
@Override
public String getSegmentId(@PathVariable("key") String key) {
return get(key, segmentService.getId(key));
}
@Override
public String getSnowflakeId(@PathVariable("key") String key) {
return get(key, snowflakeService.getId(key));
}
private String get(@PathVariable("key") String key, Result id) {
Result result;
if (key == null || key.isEmpty()) {
throw new NoKeyException();
}
result = id;
if (result.getStatus().equals(Status.EXCEPTION)) {
throw new LeafServerException(result.toString());
}
return String.valueOf(result.getId());
}
}
扩展后的源码参考:https://github.com/yinjihuan/Leaf/tree/rpc_support
感兴趣的Star下呗:https://github.com/yinjihuan/kitty
关于作者:尹吉欢,简单的技术爱好者,《Spring Cloud微服务-全栈技术与案例解析》, 《Spring Cloud微服务 入门 实战与进阶》作者, 公众号 猿天地 发起人。个人微信 jihuan900,欢迎勾搭。
分布式ID生成服务,真的有必要搞一个的更多相关文章
- spring boot / cloud (十六) 分布式ID生成服务
spring boot / cloud (十六) 分布式ID生成服务 在几乎所有的分布式系统或者采用了分库/分表设计的系统中,几乎都会需要生成数据的唯一标识ID的需求, 常规做法,是使用数据库中的自动 ...
- Leaf:美团分布式ID生成服务开源
Leaf是美团基础研发平台推出的一个分布式ID生成服务,名字取自德国哲学家.数学家莱布尼茨的一句话:“There are no two identical leaves in the world.”L ...
- 9种分布式ID生成之 美团(Leaf)实战
整理了一些Java方面的架构.面试资料(微服务.集群.分布式.中间件等),有需要的小伙伴可以关注公众号[程序员内点事],无套路自行领取 更多优选 一口气说出 9种 分布式ID生成方式,面试官有点懵了 ...
- 搞懂分布式技术12:分布式ID生成方案
搞懂分布式技术12:分布式ID生成方案 ## 转自: 58沈剑 架构师之路 2017-06-25 一.需求缘起 几乎所有的业务系统,都有生成一个唯一记录标识的需求,例如: 消息标识:message-i ...
- 分布式唯一ID生成服务
SNService是一款基于分布式的唯一ID生成服务,主要用于提供大数量业务数据建立唯一ID的需要;服务提供最低10K/s的唯一ID请求处理.如果你部署服务的CPU资源达到4核的情况下那该服务最低可以 ...
- 图解Janusgraph系列-分布式id生成策略分析
JanusGraph - 分布式id的生成策略 大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 本次更新时间:2020-9-1 文章为作者跟踪源码和查看官方文档整理,如有任何问题,请联 ...
- 细聊分布式ID生成方法
细聊分布式ID生成方法 https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=403837240&idx=1&sn=ae9 ...
- 分布式ID生成方法-趋势有序的全局唯一ID
一.需求缘起 几乎所有的业务系统,都有生成一个记录标识的需求,例如: (1)消息标识:message-id (2)订单标识:order-id (3)帖子标识:tiezi-id 这个记录标识往往就是数据 ...
- 【58沈剑架构系列】细聊分布式ID生成方法
一.需求缘起 几乎所有的业务系统,都有生成一个记录标识的需求,例如: (1)消息标识:message-id (2)订单标识:order-id (3)帖子标识:tiezi-id 这个记录标识往往就是数据 ...
随机推荐
- xutils工具上传日志文件--使用https并且带进度条显示
package logback.ecmapplication.cetcs.com.myapplication; import android.app.Activity; import android. ...
- Docker Playgrounds
上级:https://www.cnblogs.com/hackerxiaoyon/p/12747387.html Flink Operations Playground flink的操作场地,从这一小 ...
- Win8.1卸载64位Oracle Database 11g的详细图文步骤记录
Oracle Database 11g在Win8 上的卸载过程记录. Step1停用oracle服务:进入计算机管理/任务管理器,在服务中,找到oracle开头的所有服务,右击选择停止: Step2 ...
- 基于flink和drools的实时日志处理
1.背景 日志系统接入的日志种类多.格式复杂多样,主流的有以下几种日志: filebeat采集到的文本日志,格式多样 winbeat采集到的操作系统日志 设备上报到logstash的syslog日志 ...
- 使用迭代器模式批量获得数据(C#实现)
先说一下项目的背景,以前曾经做过一个项目,根据Excel中的数据批量的到网页上抓取数据,将抓取到的数据批量的回填到Excel中.这个Excel中有很多行的记录(多的时候会有好几千行),每一行数据存储能 ...
- 深入解读Dictionary
Dictionary<TKey,TValue>是日常.net开发中最常用的数据类型之一,基本上遇到键值对类型的数据时第一反应就是使用这种散列表.散列表特别适合快速查找操作,查找的效率是常数 ...
- tableau入门学习笔记--分页功能
最近在使用tableau来制作报表,对于tableau也是第一次接触并使用,每天学习些新的功能来记录在博客里,给他人方便,也给自己方便 tableau分页功能 很多时候由于工作表过长而出现拖拽条,如果 ...
- 内存疯狂换页!CPU怒批操作系统
内存访问瓶颈 我是CPU一号车间的阿Q,前一阵子我们厂里发生了一件大喜事,老板拉到了一笔投资,准备扩大生产规模. 不过老板挺抠门的,拉到了投资也不给我们涨点工资,就知道让我们拼命干活,压榨我们的劳动力 ...
- Selenium之浏览器驱动下载和配置使用
浏览器驱动下载 Chrome浏览器驱动:chromedriver , taobao备用地址 Firefox浏览器驱动:geckodriver Edge浏览器驱动:MicrosoftWebDriver ...
- Netty 中的内存分配浅析-数据容器
本篇接续前一篇继续讲 Netty 中的内存分配.上一篇 先简单做一下回顾: Netty 为了更高效的管理内存,自己实现了一套内存管理的逻辑,借鉴 jemalloc 的思想实现了一套池化内存管理的思路: ...