3. Distributional Reinforcement Learning with Quantile Regression
C51算法理论上用Wasserstein度量衡量两个累积分布函数间的距离证明了价值分布的可行性,但在实际算法中用KL散度对离散支持的概率进行拟合,不能作用于累积分布函数,不能保证Bellman更新收敛;且C51算法使用价值分布的若干个固定离散支持,通过调整它们的概率来构建价值分布。
而分位数回归(quantile regression)的distributional RL对此进行了改进。首先,使用了C51的“转置”,即固定若干个离散支持的均匀概率,调整离散支持的位置;引入分位数回归的思想,近似地实现了Wasserstein距离作为损失函数。
Quantile Distribution
假设\(\mathcal{Z}_Q\)是分位数分布空间,可以将它的累积概率函数均匀分为\(N\)等分,即\(\tau_0,\tau_1...,\tau_N(\tau_i=\frac{i}{N},i=0,1,..,N)\)。使用模型\(\theta:\mathcal{S}\times \mathcal{A}\to \mathbb{R}^N\)来预测分位数分布\(Z_\theta \in \mathcal{Z}_Q\),即模型\(\{\theta_i (s,a)\}\)将状态-动作对\((s,a)\)映射到均匀概率分布上。\(Z_\theta (s,a)\)的定义如下
\]
其中,\(\delta_z\)表示在\(z\in\mathbb{R}\)处的Dirac函数
与C51算法相比,这种做法的好处:
- 不再受预设定的支持限制,当回报的变化范围很大时,预测更精确
- 取消了C51的投影步骤,避免了一些先验知识
- 使用分位数回归,可以近似最小化Wassertein损失,梯度下降不再有偏
Quantile Approximation
Quantile Projection
使用1-Wassertein距离对随机价值分布\(Z\in \mathcal{Z}\)到\(\mathcal{Z}_Q\)的投影进行量化:
\]
假设\(Z_\theta\)的支持集为\(\{\theta_1,...,\theta_N \}\),那么
\]
其中,\(\tau_i,\tau_{i-1}\in[0,1]\)论文指出,当\(F_Z^{-1}\)是逆累积分布函数时,\(F_Z^{-1}((\tau_{i-1}+\tau_i)/2)\)最小。因此,量化中点为\(\mathcal{\hat\tau_i}=\frac{\tau_{i-1}+\tau_i}{2}(1\le i\le N)\),且最小化\(W_1\)的支持\(\theta_i=F_Z^{-1}(\mathcal{\hat\tau_i})\)。如下图
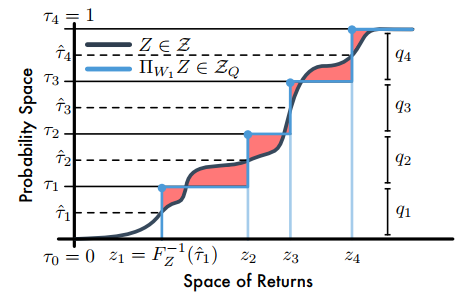
【注】C51是将回报空间(横轴)均分为若干个支持,然后求Bellman算子更新后回报落在每个支持上的概率,而分位数投影是将累积概率(纵轴)分为若干个支持(图中是4个支持),然后求出对应每个支持的回报值;图中阴影部分的面积和就是1-Wasserstein误差。
Quantile Regression
建立分位数投影后,需要去近似分布的分位数函数,需要引入分位数回归损失。对于分布\(Z\)和一个给定的分位数\(\tau\),分位数函数\(F_Z^{-1}(\tau)\)的值可以通过最小化分位数回归损失得到
\]
最终,整体的损失函数为
\]
但是,分位数回归损失在0处不平滑。论文进一步提出了quantile Huber loss:
\begin{cases}
& \frac{1}{2}u^2,\quad\quad\quad\quad \text{if} |u|\le \mathcal{K} \\
& \mathcal{K}(|u|-\frac{1}{2}\mathcal{K}),\,\, \text{otherwise}
\end{cases}
\]
\]
Implement
QR TD-Learning
QRTD算法(quantile regression temporal difference learning algorithm)的更新
\]
\(a\sim\pi (\cdot|s),r\sim R(s,a),s^\prime\sim P(\cdot|s,a),z^\prime\sim Z_\theta(s^\prime)\)
其中,\(Z_\theta\)是由公式(1)给出的分位数分布,\(\theta_i (s)\)是状态\(s\)下\(F_{Z^\pi (s)}^{-1}(\mathcal{\hat \tau}_i)\)的估计值。
QR-DQN
QR-DQN算法伪代码

Append
1. Dirac Delta Function
\]
References
Will Dabney, Mark Rowland, Marc G. Bellemare, Rémi Munos. Distributional Reinforcement Learning with Quantile Regression. 2017.
Distributional RL
3. Distributional Reinforcement Learning with Quantile Regression的更多相关文章
- Distributional Reinforcement Learning with Quantile Regression
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1710.10044v1 [cs.AI] 27 Oct 2017 In AAAI Conference on Artifici ...
- Statistics and Samples in Distributional Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1902.08102v1 [stat.ML] 21 Feb 2019 Abstract 我们通过递归估计回报分布的统计量,提供 ...
- 2. A Distributional Perspective on Reinforcement Learning
本文主要研究了分布式强化学习,利用价值分布(value distribution)的思想,求出回报\(Z\)的概率分布,从而取代期望值(即\(Q\)值). Q-Learning Q-Learning的 ...
- [转]Introduction to Learning to Trade with Reinforcement Learning
Introduction to Learning to Trade with Reinforcement Learning http://www.wildml.com/2018/02/introduc ...
- Introduction to Learning to Trade with Reinforcement Learning
http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/ The academic ...
- Rainbow: Combining Improvements in Deep Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1710.02298v1 [cs.AI] 6 Oct 2017 (AAAI 2018) Abstract 深度强化学习社区对D ...
- Machine Learning Algorithms Study Notes(5)—Reinforcement Learning
Reinforcement Learning 对于控制决策问题的解决思路:设计一个回报函数(reward function),如果learning agent(如上面的四足机器人.象棋AI程序)在决定 ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
随机推荐
- 云计算openstack——维护(15)
- 关于JSON的零碎小知识
1.ali的fastjson在将实体类转成jsonString的时候,一些首字母大写的字段会自动修改为小字母,这种字段加 @JsonProperty(value = "DL_id" ...
- 你还在寻找Navicat的破解版本?你应该了解开源免费的DBeaver
前言 你是否还在各个"免费绿色"的下载网站上寻找navicat的破解版本,或者已经通过某些方式破解了navicat的特定版本.你或者是在一家对安全和软件著作权比较看重的公司,明令禁 ...
- Go 里的函数
1. 关于函数 函数是基于功能或 逻辑进行封装的可复用的代码结构.将一段功能复杂.很长的一段代码封装成多个代码片段(即函数),有助于提高代码可读性和可维护性. 在 Go 语言中,函数可以分为两种: 带 ...
- 二分类问题 - 【老鱼学tensorflow2】
什么是二分类问题? 二分类问题就是最终的结果只有好或坏这样的一个输出. 比如,这是好的,那是坏的.这个就是二分类的问题. 我们以一个电影评论作为例子来进行.我们对某部电影评论的文字内容为好评和差评. ...
- 20行代码实现,使用Tarjan算法求解强连通分量
今天是算法数据结构专题的第36篇文章,我们一起来继续聊聊强连通分量分解的算法. 在上一篇文章当中我们分享了强连通分量分解的一个经典算法Kosaraju算法,它的核心原理是通过将图翻转,以及两次递归来实 ...
- 记一次磁盘UUID不能识别故障处理
早上zabbix报警,磁盘满了,登录服务器查看信息,一顿操作,突然发现最后lvextend命令不能扩容,查看LVM信息 报错信息"Couldn't find device with uuid ...
- vsCode 搭建Java开发环境
1.安装扩展 Java Extension Pack Spring Boot Extension Pack 2.配置Maven 打开设置 搜索maven 找到并打开 在 settings.json ...
- java安全编码指南之:异常处理
目录 简介 异常简介 不要忽略checked exceptions 不要在异常中暴露敏感信息 在处理捕获的异常时,需要恢复对象的初始状态 不要手动完成finally block 不要捕获NullPoi ...
- training set, validation set, test set的区别
training set: 用来训练模型 validation set : 用来做model selection test set : 用来评估所选出来的model的实际性能 我们知道,在做模型训练之 ...