3. Distributional Reinforcement Learning with Quantile Regression
C51算法理论上用Wasserstein度量衡量两个累积分布函数间的距离证明了价值分布的可行性,但在实际算法中用KL散度对离散支持的概率进行拟合,不能作用于累积分布函数,不能保证Bellman更新收敛;且C51算法使用价值分布的若干个固定离散支持,通过调整它们的概率来构建价值分布。
而分位数回归(quantile regression)的distributional RL对此进行了改进。首先,使用了C51的“转置”,即固定若干个离散支持的均匀概率,调整离散支持的位置;引入分位数回归的思想,近似地实现了Wasserstein距离作为损失函数。
Quantile Distribution
假设\(\mathcal{Z}_Q\)是分位数分布空间,可以将它的累积概率函数均匀分为\(N\)等分,即\(\tau_0,\tau_1...,\tau_N(\tau_i=\frac{i}{N},i=0,1,..,N)\)。使用模型\(\theta:\mathcal{S}\times \mathcal{A}\to \mathbb{R}^N\)来预测分位数分布\(Z_\theta \in \mathcal{Z}_Q\),即模型\(\{\theta_i (s,a)\}\)将状态-动作对\((s,a)\)映射到均匀概率分布上。\(Z_\theta (s,a)\)的定义如下
\]
其中,\(\delta_z\)表示在\(z\in\mathbb{R}\)处的Dirac函数
与C51算法相比,这种做法的好处:
- 不再受预设定的支持限制,当回报的变化范围很大时,预测更精确
- 取消了C51的投影步骤,避免了一些先验知识
- 使用分位数回归,可以近似最小化Wassertein损失,梯度下降不再有偏
Quantile Approximation
Quantile Projection
使用1-Wassertein距离对随机价值分布\(Z\in \mathcal{Z}\)到\(\mathcal{Z}_Q\)的投影进行量化:
\]
假设\(Z_\theta\)的支持集为\(\{\theta_1,...,\theta_N \}\),那么
\]
其中,\(\tau_i,\tau_{i-1}\in[0,1]\)论文指出,当\(F_Z^{-1}\)是逆累积分布函数时,\(F_Z^{-1}((\tau_{i-1}+\tau_i)/2)\)最小。因此,量化中点为\(\mathcal{\hat\tau_i}=\frac{\tau_{i-1}+\tau_i}{2}(1\le i\le N)\),且最小化\(W_1\)的支持\(\theta_i=F_Z^{-1}(\mathcal{\hat\tau_i})\)。如下图
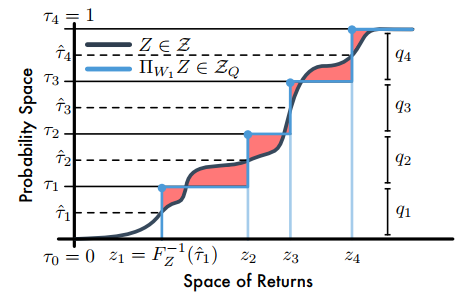
【注】C51是将回报空间(横轴)均分为若干个支持,然后求Bellman算子更新后回报落在每个支持上的概率,而分位数投影是将累积概率(纵轴)分为若干个支持(图中是4个支持),然后求出对应每个支持的回报值;图中阴影部分的面积和就是1-Wasserstein误差。
Quantile Regression
建立分位数投影后,需要去近似分布的分位数函数,需要引入分位数回归损失。对于分布\(Z\)和一个给定的分位数\(\tau\),分位数函数\(F_Z^{-1}(\tau)\)的值可以通过最小化分位数回归损失得到
\]
最终,整体的损失函数为
\]
但是,分位数回归损失在0处不平滑。论文进一步提出了quantile Huber loss:
\begin{cases}
& \frac{1}{2}u^2,\quad\quad\quad\quad \text{if} |u|\le \mathcal{K} \\
& \mathcal{K}(|u|-\frac{1}{2}\mathcal{K}),\,\, \text{otherwise}
\end{cases}
\]
\]
Implement
QR TD-Learning
QRTD算法(quantile regression temporal difference learning algorithm)的更新
\]
\(a\sim\pi (\cdot|s),r\sim R(s,a),s^\prime\sim P(\cdot|s,a),z^\prime\sim Z_\theta(s^\prime)\)
其中,\(Z_\theta\)是由公式(1)给出的分位数分布,\(\theta_i (s)\)是状态\(s\)下\(F_{Z^\pi (s)}^{-1}(\mathcal{\hat \tau}_i)\)的估计值。
QR-DQN
QR-DQN算法伪代码

Append
1. Dirac Delta Function
\]
References
Will Dabney, Mark Rowland, Marc G. Bellemare, Rémi Munos. Distributional Reinforcement Learning with Quantile Regression. 2017.
Distributional RL
3. Distributional Reinforcement Learning with Quantile Regression的更多相关文章
- Distributional Reinforcement Learning with Quantile Regression
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1710.10044v1 [cs.AI] 27 Oct 2017 In AAAI Conference on Artifici ...
- Statistics and Samples in Distributional Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1902.08102v1 [stat.ML] 21 Feb 2019 Abstract 我们通过递归估计回报分布的统计量,提供 ...
- 2. A Distributional Perspective on Reinforcement Learning
本文主要研究了分布式强化学习,利用价值分布(value distribution)的思想,求出回报\(Z\)的概率分布,从而取代期望值(即\(Q\)值). Q-Learning Q-Learning的 ...
- [转]Introduction to Learning to Trade with Reinforcement Learning
Introduction to Learning to Trade with Reinforcement Learning http://www.wildml.com/2018/02/introduc ...
- Introduction to Learning to Trade with Reinforcement Learning
http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/ The academic ...
- Rainbow: Combining Improvements in Deep Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1710.02298v1 [cs.AI] 6 Oct 2017 (AAAI 2018) Abstract 深度强化学习社区对D ...
- Machine Learning Algorithms Study Notes(5)—Reinforcement Learning
Reinforcement Learning 对于控制决策问题的解决思路:设计一个回报函数(reward function),如果learning agent(如上面的四足机器人.象棋AI程序)在决定 ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
随机推荐
- 安装Linux的CentOS操作系统 - 初学者系列 - 学习者系列文章
Linux系统对于一些熟悉Windows操作系统的用户来说可能比较陌生,但是它也是一种多用户.多任务的操作系统,现在也发展成为了多种版本的操作系统了.如果想对该系统进行学习,请下载这个学习文档:htt ...
- 1.10HDFS 回收站机制
- Unity3d 游戏设计(一)井字棋
3D游戏设计(一)井字棋 运行效果: 实现过程 声明变量: public Texture2D O; public Texture2D X; GUIStyle myStyle; private int ...
- C++解析XML的通用库
工作中,经常和XML打交道,最近抽空实现了一个通用解析XML的库,已归档在GitHub,详情点击:ComXmlLib.如果您无法访问GitHub,点击此处下载(链接是初版,无法和GitHub同步,如需 ...
- Java JVM启动参数
转载于:https://www.cnblogs.com/w-wfy/p/6415856.html java启动参数共分为三类其一是标准参数(-),所有的JVM实现都必须实现这些参数的功能,而且向后兼容 ...
- [De1CTF 2019]Giftbox 分析&&TPOP学习
[De1CTF 2019]Giftbox 刚进来我以为是直接给了shell,恐怖如斯. 随便扔了个命令,之后就没然后了,hhh,截包发现可能存在sql注入. 然后我就不会了... what i lea ...
- mac电脑,charles,安卓手机如何配置代理,以及配置代理之后无法上网。已解决
设备: 电脑:mac book pro 手机:小米10 charles:4.5.6 方法一: 步骤: 首先确保电脑,手机在同一局域网, 1. charles设置代理:proxy -> proxy ...
- (转载)什么是B树?
本文转载自网络. 如有侵权,请联系处理!
- arduino中SCoop库的简单应用案例
转载:https://www.csdn.net/gather_27/MtTaggzsMDExMS1ibG9n.html arduino中SCoop库的简单应用案例首先这篇文章来在视频https://v ...
- Dockerfile常用指令及使用
Dockerfile常用指令及使用 1. dockerfile介绍 2. Dockerfile常用指令 指令 描述 FROM 构建新镜像是基于哪个镜像 MAINTAINER 进行维护者姓名或邮箱地址 ...