实例学习Bloom Filter
0. 科普
1. 为什么需要Bloom Filter
2. 基本原理
3. 如何设计Bloom Filter
4. 实例操作
5. 扩展
0. 科普
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
1. 为什么需要Bloom Filter
举例说明:假设有2000万个url,现在判断一个新的url是否在这2000万个之中。可以有的思路:
- 将访问过的URL保存到数据库。
- 用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。
- URL经过MD5等单向哈希后再保存到HashSet或数据库。
- Bit-Map方法。建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。
分析
思路1:当数据量很大时,查询数据库变得效率底下
思路2:太消耗内存,还得把字符串全部储存起来
思路3:字符串经过MD5处理后有128个bit,比思路2省了很多空间
思路4:一个字符串仅用一位来表示,比思路3还节省空间
当然前提是会出现误判(哈希后表示相同),为了继承这么好的思路,同时减少误判的情况,可以来个折衷:一个哈希函数生成一个位,用多个哈希函数生成多个位来存储一个字符串。这样比Bit-Map多用了些空间,但是减少了误判率。
2. 基本原理
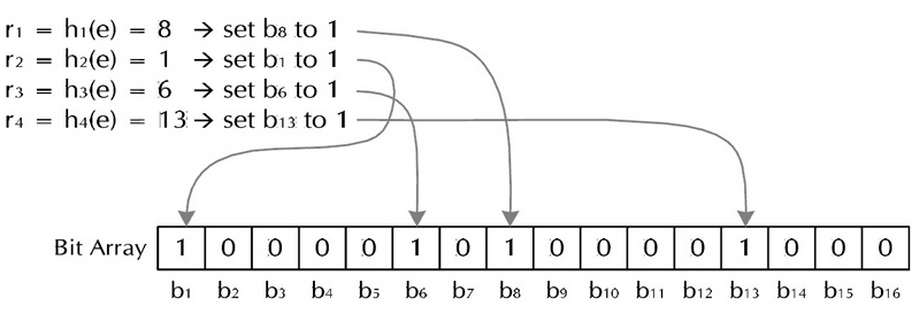
这样把大量的字符串存起来。查找时,用同样的哈希处理待查串,如果对应的各位上都为1,说明该字符串可能在这些字符串中,否则一定不在其中。
3. 如何设计Bloom Filter
如何降低误判率是关键,这需要
- 选取区分度高的哈希函数
- 根据存储数组、哈希函数个数、误判率之间的关系,分配空间、个数
直接利用前人的结论:
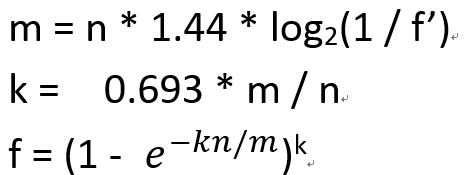
其中f'是自己期望的误判率,m是总共开辟的存储空间位数,n是待存储字符串的个数,k是哈希函数的个数,f是真正的误判率。
4. 实例操作
需求:2000万个已知url,100个待查url
设计:
1. 设定误判率为0.1, n=2000万,计算
m = n * 1.44 * math.log(/f)/math.log()=
k = 0.693 * m / n=
f = ( - math.exp(- * k * n / m)) ** k = 0.00101298781512
哈希函数的选取看这里
参考代码(c++)
makefile
objects = main.o hash.o bloomfilter.o main : $(objects)
g++ -o main $(objects) main.o : hash.h bloomfilter.h
bloomfilter.o : bloomfilter.h
hash.o : hash.h clean:
rm *.o main
main.cc
#include <iostream>
#include <fstream>
#include <sstream>
#include <cstring>
#include <string>
#include "bloomfilter.h"
using namespace std; const int MAXSIZE = ;
int main(int argc, char **argv)
{
char *poolfile = argv[];
char *testfile = argv[];
cout << poolfile << endl;
ifstream fpool(poolfile);
ifstream ftest(testfile);
if(!fpool)
{
cout << "cannot open the file:" << poolfile << endl;
return ;
}
if(!ftest)
{
cout << "cannot open the file:" << testfile << endl;
return ;
}
BloomFilter bf(MAXSIZE);
bf.setBit(fpool);
cout << "Store OK" << endl;
bf.checkBit(ftest);
cout << "Check OK" << endl;
fpool.close();
ftest.close();
}
bloomfilter.h
#include <iostream>
#include <string>
#include <fstream>
#include <vector>
#include "hash.h"
using namespace std;
class BloomFilter
{
public:
BloomFilter(int size) : SIZE(size) { vec.resize(size); };
void setBit(ifstream &f);
void setBit(const string &s);
void setBit(unsigned int count); bool checkBit(ifstream &f);
bool checkBit(const string &s);
bool checkBit(unsigned int count);
private:
vector<char> vec;
const unsigned int SIZE;
};
bloomfilter.cc
#include "bloomfilter.h" void BloomFilter::setBit(ifstream &f)
{
string line;
while(f >> line)
{
setBit(line);
}
} bool BloomFilter::checkBit(ifstream &f)
{
string line;
while(f >> line)
{
if(!checkBit(line))
cout << line << endl;
}
} void BloomFilter::setBit(const string &s)
{
unsigned int bitpos = ;
const char *str = s.c_str();
int len = s.size(); bitpos = RSHash(str, len);
setBit(bitpos);
bitpos = JSHash(str, len);
setBit(bitpos);
bitpos = PJWHash(str, len);
setBit(bitpos);
bitpos = ELFHash(str, len);
setBit(bitpos);
bitpos = BKDRHash(str, len);
setBit(bitpos);
bitpos = SDBMHash(str, len);
setBit(bitpos);
bitpos = DJBHash(str, len);
setBit(bitpos);
bitpos = DEKHash(str, len);
setBit(bitpos);
bitpos = BPHash(str, len);
setBit(bitpos);
bitpos = FNVHash(str, len);
setBit(bitpos);
} bool BloomFilter::checkBit(const string &s)
{
unsigned int bitpos = ;
const char *str = s.c_str();
int len = s.size();
bool rev = true; bitpos = RSHash(str, len);
rev &= checkBit(bitpos);
bitpos = JSHash(str, len);
rev &= checkBit(bitpos);
bitpos = PJWHash(str, len);
rev &= checkBit(bitpos);
bitpos = ELFHash(str, len);
rev &= checkBit(bitpos);
bitpos = BKDRHash(str, len);
rev &= checkBit(bitpos);
bitpos = SDBMHash(str, len);
rev &= checkBit(bitpos);
bitpos = DJBHash(str, len);
rev &= checkBit(bitpos);
bitpos = DEKHash(str, len);
rev &= checkBit(bitpos);
bitpos = BPHash(str, len);
rev &= checkBit(bitpos);
bitpos = FNVHash(str, len);
rev &= checkBit(bitpos);
return rev;
} void BloomFilter::setBit(unsigned int count)
{
count = count % (SIZE * );
vec[count / ] |= ( << (count % ));
} bool BloomFilter::checkBit(unsigned int count)
{
count = count % (SIZE * );
return vec[count / ] &= ( << (count % ));
}
hash.h
unsigned int RSHash(const char* str, unsigned int len);
unsigned int JSHash(const char* str, unsigned int len);
unsigned int PJWHash(const char* str, unsigned int len);
unsigned int ELFHash(const char* str, unsigned int len);
unsigned int BKDRHash(const char* str, unsigned int len);
unsigned int SDBMHash(const char* str, unsigned int len);
unsigned int DJBHash(const char* str, unsigned int len);
unsigned int DEKHash(const char* str, unsigned int len);
unsigned int BPHash(const char* str, unsigned int len);
unsigned int FNVHash(const char* str, unsigned int len);
hash.cc
#include "hash.h"
unsigned int RSHash(const char* str, unsigned int len)
{
unsigned int b = ;
unsigned int a = ;
unsigned int hash = ;
unsigned int i = ; for(i=; i<len; str++, i++)
{
hash = hash*a + (*str);
a = a*b;
} return hash;
}
/* End Of RS Hash Function */ unsigned int JSHash(const char* str, unsigned int len)
{
unsigned int hash = ;
unsigned int i = ; for(i=; i<len; str++, i++)
{
hash ^= ((hash<<) + (*str) + (hash>>));
} return hash;
}
/* End Of JS Hash Function */ unsigned int PJWHash(const char* str, unsigned int len)
{
const unsigned int BitsInUnsignedInt = (unsigned int)(sizeof(unsigned int) * );
const unsigned int ThreeQuarters = (unsigned int)((BitsInUnsignedInt * ) / );
const unsigned int OneEighth = (unsigned int)(BitsInUnsignedInt / );
const unsigned int HighBits = (unsigned int)(0xFFFFFFFF) << (BitsInUnsignedInt - OneEighth);
unsigned int hash = ;
unsigned int test = ;
unsigned int i = ; for(i=;i<len; str++, i++)
{
hash = (hash<<OneEighth) + (*str); if((test = hash & HighBits) != )
{
hash = ((hash ^(test >> ThreeQuarters)) & (~HighBits));
}
} return hash;
}
/* End Of P. J. Weinberger Hash Function */ unsigned int ELFHash(const char* str, unsigned int len)
{
unsigned int hash = ;
unsigned int x = ;
unsigned int i = ; for(i = ; i < len; str++, i++)
{
hash = (hash << ) + (*str);
if((x = hash & 0xF0000000L) != )
{
hash ^= (x >> );
}
hash &= ~x;
} return hash;
}
/* End Of ELF Hash Function */ unsigned int BKDRHash(const char* str, unsigned int len)
{
unsigned int seed = ; /* 31 131 1313 13131 131313 etc.. */
unsigned int hash = ;
unsigned int i = ; for(i = ; i < len; str++, i++)
{
hash = (hash * seed) + (*str);
} return hash;
}
/* End Of BKDR Hash Function */ unsigned int SDBMHash(const char* str, unsigned int len)
{
unsigned int hash = ;
unsigned int i = ; for(i = ; i < len; str++, i++)
{
hash = (*str) + (hash << ) + (hash << ) - hash;
} return hash;
}
/* End Of SDBM Hash Function */ unsigned int DJBHash(const char* str, unsigned int len)
{
unsigned int hash = ;
unsigned int i = ; for(i = ; i < len; str++, i++)
{
hash = ((hash << ) + hash) + (*str);
} return hash;
}
/* End Of DJB Hash Function */ unsigned int DEKHash(const char* str, unsigned int len)
{
unsigned int hash = len;
unsigned int i = ; for(i = ; i < len; str++, i++)
{
hash = ((hash << ) ^ (hash >> )) ^ (*str);
}
return hash;
}
/* End Of DEK Hash Function */ unsigned int BPHash(const char* str, unsigned int len)
{
unsigned int hash = ;
unsigned int i = ;
for(i = ; i < len; str++, i++)
{
hash = hash << ^ (*str);
} return hash;
}
/* End Of BP Hash Function */ unsigned int FNVHash(const char* str, unsigned int len)
{
const unsigned int fnv_prime = 0x811C9DC5;
unsigned int hash = ;
unsigned int i = ; for(i = ; i < len; str++, i++)
{
hash *= fnv_prime;
hash ^= (*str);
} return hash;
}
/* End Of FNV Hash Function */
数据下载:http://pan.baidu.com/s/1hqBTks0
Github 地址:https://github.com/jihite/Bloom-Filter
5. 扩展
如何删除存储数组中的元素?
思路:把存储数组的每一个元素扩展一下(原来是1b)用来存储该位置被置1的次数。存储是,计数次数加一;删除的时候,计数次数减一。
实例学习Bloom Filter的更多相关文章
- Bloom Filter:海量数据的HashSet
Bloom Filter一般用于数据的去重计算,近似于HashSet的功能:但是不同于Bitmap(用于精确计算),其为一种估算的数据结构,存在误判(false positive)的情况. 1. 基本 ...
- 探索C#之布隆过滤器(Bloom filter)
阅读目录: 背景介绍 算法原理 误判率 BF改进 总结 背景介绍 Bloom filter(后面简称BF)是Bloom在1970年提出的二进制向量数据结构.通俗来说就是在大数据集合下高效判断某个成员是 ...
- Bloom Filter 布隆过滤器
Bloom Filter 是由伯顿.布隆(Burton Bloom)在1970年提出的一种多hash函数映射的快速查找算法.它实际上是一个很长的二进制向量和一些列随机映射函数.应用在数据量很大的情况下 ...
- Bloom Filter学习
参考文献: Bloom Filters - the math http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html B ...
- 【转】探索C#之布隆过滤器(Bloom filter)
原文:蘑菇先生,http://www.cnblogs.com/mushroom/p/4556801.html 背景介绍 Bloom filter(后面简称BF)是Bloom在1970年提出的二进制向量 ...
- bloom filter
Bloom filter 是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员. 结 构 二进制 召回率 ...
- Bloom Filter 概念和原理
Bloom filter 是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员.如果检测结果为是,该元素不一定 ...
- 【转】Bloom Filter布隆过滤器的概念和原理
转自:http://blog.csdn.net/jiaomeng/article/details/1495500 之前看数学之美丽,里面有提到布隆过滤器的过滤垃圾邮件,感觉到何其的牛,竟然有这么高效的 ...
- [爬虫学习笔记]基于Bloom Filter的url去重模块UrlSeen
Url Seen用来做url去重.对于一个大的爬虫系统,它可能已经有百亿或者千亿的url,新来一个url如何能快速的判断url是否已经出现过非常关键.因为大的爬虫系统可能一秒钟就会下载 ...
随机推荐
- find命令小结
find命令小结 find命令用于在系统中查找文件,配合 -exec 选项或 xargs命令还能对查找到得文件执行一些列的自动化操作. 基本格式:find [-H] [-L] [-P] [path.. ...
- Python中docstring文档的写法
该写法根据Python的PEP 257文档总结. 类的函数称为方法(method),模块里的函数称为函数(function) 每一个包,模块,类,函数,方法都应该包含文档,包括类的__init__方法 ...
- 编辑器未包含main类型解决方法
将文件移到 src 这个 Java Source Folder 下面去,现在在外面的 java 文件不会被当成一个需要编译的类,eclipse 不会编译 Java Source Folder 外面的任 ...
- 转字符驱动实例gpio
概述: 字符设备驱动程序: 是按照字符设备要求完成的由操作系统调用的代码. 重点理解以下内容: 1. 驱动是写给操作系统的代码,它不是直接给用户层程序调用的,而是给系统调用的 2. 所以驱动要向系 ...
- 在Windows下忘记MySQL最高用户权限密码的解决方案
1.打开MySQL配置文件 my.ini中,添加上skip-grant-tables,可以添加到文件的末尾或者是这添加到[mysqld]的下面(直接添加在my.ini文件最后亲测可以,但是在[mysq ...
- 修改myeclipse的jsp模板
在myeclipse的安装目录下: C:\Users\Seeker\AppData\Local\MyEclipse Professional\plugins 找到com.genuitec.eclips ...
- C# 获取数组的子集
private static void PrintSubItems(int[] source) { int i = 1; int total = int.Parse(Math.Pow(2, sourc ...
- 文件中的类都不能进行设计,因此未能为该文件显示设计器。设计器检查出文件中有以下类: FormMain --- 未能加载基类“WinForm.Win.FormsBase.FormMainBase”。请确保已引用该程序集并已生成所有项目
出现该问题的原因:FormMain从FormMainBase继承之后,一旦修改FormMainBase就会出现这个问题 解决方案:(1-4是搜索网友的) 1: 关闭VS所有窗口,后重启.即可返回正常. ...
- 【UVA】【11427】玩纸牌
数学期望 也是刘汝佳老师白书上的例题……感觉思路很神奇啊 //UVA 11427 #include<cmath> #include<cstdio> #include<cs ...
- Linux显示中文乱码解决方法
vi /etc/sysconfig/i18n 将内容改为 LANG="zh_CN.GB18030" LANGUAGE="zh_CN.GB18030:zh_CN.GB231 ...