关于Python文档读取UTF-8编码文件问题
近来接到一个小项目,读取目标文件中每一行url,并逐个请求url,拿到想要的数据。
#-*- coding:utf-8 -*-
class IpUrlManager(object):
def __init__(self):
self.newipurls = set()
#self.oldipurls = set() def Is_has_ipurl(self):
return len(self.newipurls)!=0 def get_ipurl(self):
if len(self.newipurls)!=0:
new_ipurl = self.newipurls.pop()
#self.oldipurls.add(new_ipurl)
return new_ipurl
else:
return None def download_ipurl(self,destpath):
try:
f = open(destpath,'r')
iter_f = iter(f)
lines = 0
for ipurl in iter_f:
lines = lines + 1
self.newipurls.add((ipurl.rstrip('\r\n'))
#log记录读取了多少行IP url
#print lines
finally:
if f:
f.close()
咋一眼看code写的没问题,每一个url 增加进newipurls set集合中。但是请求的过程中,requests.get后,会出现如下错误:
raise InvalidSchema("No connection adapters were found for '%s'" % url)

后来发现每次都是第一行的url请求失败。然后打印print 请求的url。也没发现异常。然后从根源上去找,好吧,print打印newipurls set集合看看。
果然,问题就在这里。

奇怪,为什么这个URL前面为默认加上了\xef\xbb\xbf 这几个字符呢?
上网看了一些资料,原来在python的file对象的readline以及readlines程序中,针对一些UTF-8编码的文件,开头会加入BOM来表明编码方式。
何为BOM?
所谓BOM,全称是Byte Order Mark,它是一个Unicode字符,通常出现在文本的开头,用来标识字节序(Big/Little Endian),除此以外还可以标识编码(UTF-8/16/32)。
其实如果大家有UltraEdit tool可以发现,在另存为文件的时候,可以保存为UTF-8 和UTF-8 无BOM的文件。
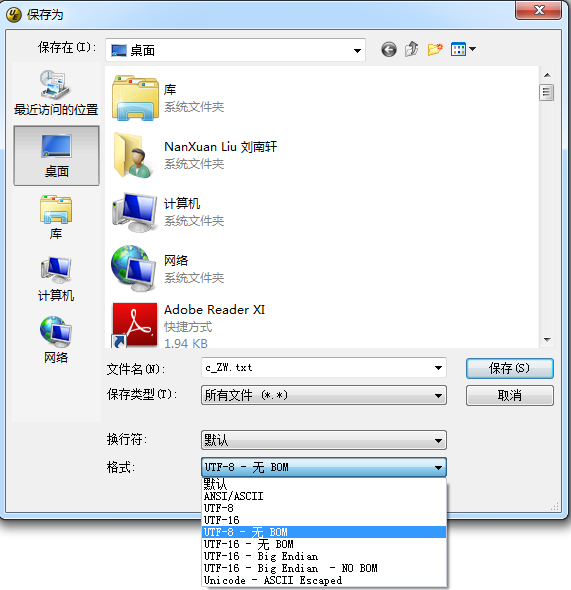
如果将文件另存在UTF-8的格式,则文件的开头默认会增加三个字节\xef\xbb\xbf。
怎么检测该文件是否为UTF-8 带BOM的呢?
import codecs
def download_ipurl(self,destpath):
try:
f = open(destpath,'r')
iter_f = iter(f)
lines = 0
for ipurl in iter_f:
lines = lines + 1
if ipurl[0:3] == codecs.BOM_UTF8:
self.newipurls.add((ipurl.rstrip('\r\n')).lstrip('\xef\xbb\xbf'))
#print self.newipurls
#log记录读取了多少行IP url
#print lines
finally:
if f:
f.close()
引用codecs模块,来判断前三个字节是否为BOM_UTF8。如果是,则剔除\xef\xbb\xbf字节。
其实大家可以通过其他方式剔除BOM字节,我写的比较粗糙。
关于Python文档读取UTF-8编码文件问题的更多相关文章
- 吴裕雄--天生自然python学习笔记:python文档操作批量替换 Word 文件中的文字
我们经常会遇到在不同的 Word 文件中的需要做相同的文字替换,若是一个一个 文件操作,会花费大量时间 . 本节案例可以找出指定目录中的所有 Word 文件(包含 子目录),并对每一个文件进行指定的文 ...
- python文档自动翻译
关键方法 提取文档内容 读取TXT文档 txt文档的读取很简单,直接用python自带的open()方法就好,代码如下所示: # 读取TXT文档 def read_txt(path): '''实现TX ...
- 基于 Python 官方 GitHub 构建 Python 文档
最近在学 Python,所以总是在看 Python 的官方文档, https://docs.python.org/2/ 因为祖传基因的影响,我总是喜欢把这些文档保存到本地,不过 Python 的文档实 ...
- python 文档
python 文档 https://docs.python.org/2/library/index.html
- Apache PDFbox开发指南之PDF文档读取
转载请注明来源:http://blog.csdn.net/loongshawn/article/details/51542309 相关文章: <Apache PDFbox开发指南之PDF文本内容 ...
- 9.9 Python 文档字符串
9.9 Python 文档字符串. 进入 Python 标准库所在的目录. 检查每个 .py 文件看是否有__doc__ 字符串, 如果有, 对其格式进行适当的整理归类. 你的程序执行完毕后, 应该会 ...
- 第8.19节 使用__doc__访问Python文档字符串(DocStrings )
__doc__特殊变量用于查看类.函数.模块的帮助信息,这些帮助信息存放在文档字符串中. 一. 关于文档字符串 关于文档字符串前面很多章节提到过,DocStrings 文档字符串用于程序的文档说明,并 ...
- 小讲堂:Mobox文档管理软件中的文件外链是什么?
今天我们来讨论Mobox文档管理软件中的文件外链是什么?熟悉MOBOX的朋友们应该知道,如果有文件需要分享给其他同事,直接可以进行文件共享.对方会在AM的即时通讯客户端有消息提醒,点击消息提醒可以看到 ...
- SharePoint 2010遍历文档库中所有的文件,文件夹
转:http://hi.baidu.com/sygwin/item/f99600849d51a12b110ef3eb 创建一个可视WebPart,并拖放一个label控件到ascx文件上,用于显示结果 ...
随机推荐
- 新的一年新的气象 云计算与SOA
[David S.Linthicum]著 云计算和SOA是不同的概念,但是它们却相互联系.SOA是架构模式,而云计算是架构的实例,或者说是架构的一种选择,SOA更具整体性和战略性,它解决的是包括业务驱 ...
- android webview无法加载网页
主要原因是没有在AndroidManifest.xml里面设置如下: <user-permission android:name="android.permission.INTERNE ...
- sql第一课笔记
这是我看了imooc的视频教程之后重新写的笔记. 虽然之前也是学习过SQL Server数据库,但是也是忘记得差不多了.现在重新捡起来,安装一次数据库练习,使用的是mysql. 第一课是最简单的创建, ...
- ORACLE功能GREATEST功能说明具体实例
1 语法 GREATEST(expr_1, expr_2, ...expr_n) 2 说明 GREATEST(expr_1, expr_2, ...expr_n ...
- android 自定义progressDialog实现
我们在项目中经常会遇到这样一个应用场景:执行某个耗时操作时,为了安抚用户等待的烦躁心情我们一般会使用进度条之类的空间,在android中让 大家最容易想到的就是progressbar或者progres ...
- oracle中imp命令具体解释
oracle中imp命令具体解释 Oracle的导入有用程序(Import utility)同意从数据库提取数据,而且将数据写入操作系统文件.imp使用的基本格式:imp[username[/pass ...
- 专业DBA 遇到的问题集
http://blog.csdn.net/mchdba/article/category/1596355/3
- When does layoutSubviews get called?
转自:http://blog.logichigh.com/2011/03/16/when-does-layoutsubviews-get-called/ It’s important to optim ...
- [转] Maven镜像配置
参考:许晓斌的<Maven实战> 镜像是为了提供更快的服务 如图:X就认为是Y的一个镜像. 编辑settings.xml配置中央仓库镜像: <settings> ... < ...
- 关于 iOS socket 都在这里了
socket(套接字)是通信的基石,是支持TCP/IP协议的网络通信的基本操作单元,包含进行网络通信必须的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程 ...