关于HTTP协议学习(二)
一,目录结构
二,HTTP Cookie & Session
1. 我们看到的 cookie
我们通过浏览器随意打开一个网站,比如网址为https://www.cnblogs.com/。在 chrome 浏览器中打开这个网站,进入开发者模式,点击Resources栏 -> 选择cookies,我们会看到如下图所示的界面:
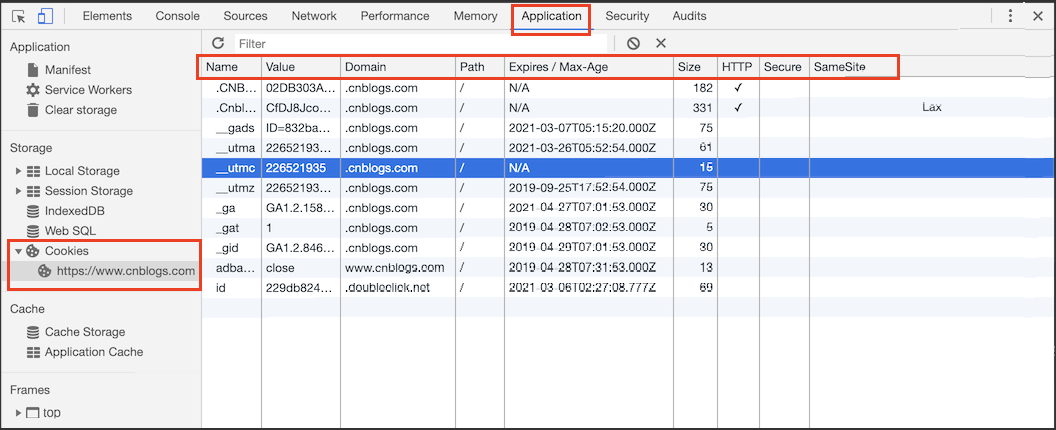
解释一下:左边栏Cookies下方会列举当前网页中设置过cookie的域都有哪些。上图中只有一个域,即“www.cnblogs.com”。而右侧区域显示的就是某个域下具体的 cookie 列表,对应上图就是“www.cnblogs.com”域下设置的多个个cookie。
在这个网页中我往https://www.cnblogs.com/getlist接口发了一个 Ajax 请求,request header如下图所示:
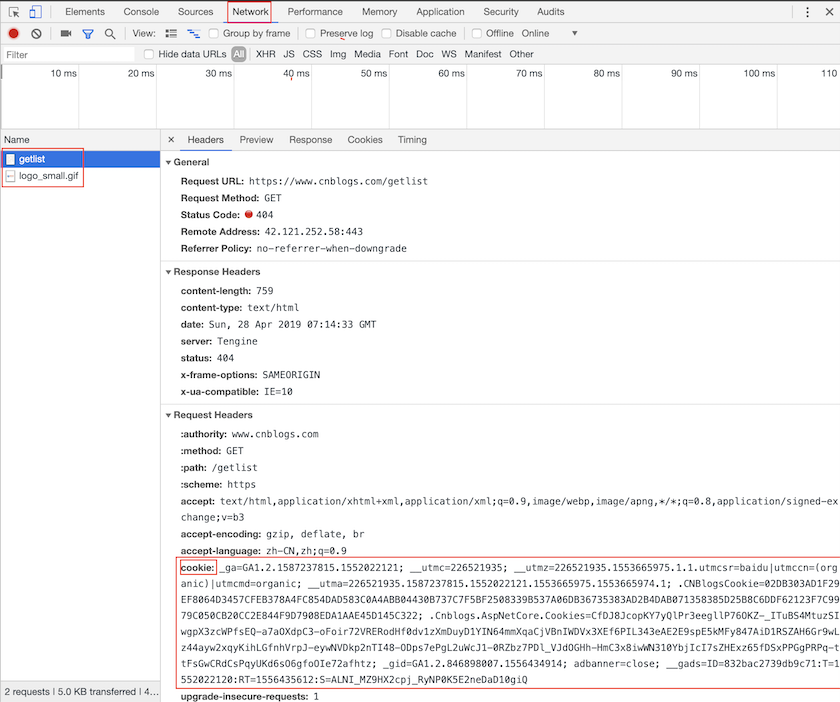
从上图中我们会看到request header中自动添加了Cookie字段(我并没有手动添加这个字段),Cookie字段的值其实就是我设置的那4个 cookie。这个请求最终会发送到https://www.cnblogs.comm这个服务器上,这个服务器就能从接收到的request header中提取那4个cookie。
上面两张图展示了cookie的基本通信流程:设置cookie => cookie被自动添加到request header中 => 服务端接收到cookie。这个流程中有几个问题需要好好研究:
什么样的数据适合放在
cookie中?cookie是怎么设置的?cookie为什么会自动加到request header中?cookie怎么增删查改?
我们要带着这几个问题继续往下阅读。
2.cookie 是怎么工作的?
首先必须明确一点,存储cookie是浏览器提供的功能。cookie 其实是存储在浏览器中的纯文本,浏览器的安装目录下会专门有一个 cookie 文件夹来存放各个域下设置的cookie。
当网页要发http请求时,浏览器会先检查是否有相应的cookie,有则自动添加在request header中的cookie字段中。这些是浏览器自动帮我们做的,而且每一次http请求浏览器都会自动帮我们做。这个特点很重要,因为这关系到“什么样的数据适合存储在cookie中”。
存储在cookie中的数据,每次都会被浏览器自动放在http请求中,如果这些数据并不是每个请求都需要发给服务端的数据,浏览器这设置自动处理无疑增加了网络开销;但如果这些数据是每个请求都需要发给服务端的数据(比如身份认证信息),浏览器这设置自动处理就大大免去了重复添加操作。所以对于那设置“每次请求都要携带的信息(最典型的就是身份认证信息)”就特别适合放在cookie中,其他类型的数据就不适合了。
但在 localStorage 出现之前,cookie被滥用当做了存储工具。什么数据都放在cookie中,即使这些数据只在页面中使用而不需要随请求传送到服务端。当然cookie标准还是做了一些限制的:每个域名下的cookie 的大小最大为4KB,每个域名下的cookie数量最多为20个(但很多浏览器厂商在具体实现时支持大于20个)。
3.cookie 的格式
* document.cookie
JS 原生的 API提供了获取cookie的方法:document.cookie(注意,这个方法只能获取非 HttpOnly 类型的cookie)。在 console 中执行这段代码可以看到结果如下图:

打印出的结果是一个字符串类型,因为cookie本身就是存储在浏览器中的字符串。但这个字符串是有格式的,由键值对 key=value构成,键值对之间由一个分号和一个空格隔开。
* cookie 的属性选项
每个cookie都有一定的属性,如什么时候失效,要发送到哪个域名,哪个路径等等。这些属性是通过cookie选项来设置的,cookie选项包括:expires(有效期)、domain(域名)、path(路径)、secure(安全性)、HttpOnly()。在设置任一个cookie时都可以设置相关的这些属性,当然也可以不设置,这时会使用这些属性的默认值。在设置这些属性时,属性之间由一个分号和一个空格隔开。代码示例如下:
* expires
expires选项用来设置“cookie 什么时间内有效”。expires其实是cookie失效日期,expires必须是 GMT 格式的时间(可以通过 new Date().toGMTString()或者 new Date().toUTCString() 来获得)。
如expires=Thu, 25 Feb 2016 04:18:00 GMT表示cookie将在2016年2月25日4:18分之后失效,对于失效的cookie浏览器会清空。如果没有设置该选项,则默认有效期为session,即会话cookie。这种cookie在浏览器关闭后就没有了。
expires是 http/1.0协议中的选项,在新的http/1.1协议中expires已经由max-age选项代替,两者的作用都是限制cookie 的有效时间。expires的值是一个时间点(cookie失效时刻= expires),而max-age的值是一个以秒为单位时间段(cookie失效时刻= 创建时刻+ max-age)。
另外,max-age的默认值是-1(即有效期为session);若max-age有三种可能值:负数、0、正数。负数:有效期session;0:删除cookie;正数:有效期为创建时刻+ max-age
* domain 和 path
domain是域名,path是路径,两者加起来就构成了 URL,domain和path一起来限制 cookie 能被哪些 URL 访问。
一句话概括:某cookie的 domain为“baidu.com”, path为“/ ”,若请求的URL(URL 可以是js/html/img/css资源请求,但不包括 XHR 请求)的域名是“baidu.com”或其子域如“api.baidu.com”、“dev.api.baidu.com”,且 URL 的路径是“/ ”或子路径“/home”、“/home/login”,则浏览器会将此 cookie 添加到该请求的 cookie 头部中。
所以domain和path这2个选项共同决定了cookie何时被浏览器自动添加到请求头部中发送出去。如果没有设置这两个选项,则会使用默认值。domain的默认值为设置该cookie的网页所在的域名,path默认值为设置该cookie的网页所在的目录。
特别说明1:
发生跨域xhr请求时,即使请求URL的域名和路径都满足 cookie 的 domain 和 path,默认情况下cookie也不会自动被添加到请求头部中。若想知道原因请阅读本文最后一节)特别说明2:
domain是可以设置为页面本身的域名(本域),或页面本身域名的父域,但不能是公共后缀 public suffix。举例说明下:如果页面域名为 www.baidu.com, domain可以设置为“www.baidu.com”,也可以设置为“baidu.com”,但不能设置为“.com”或“com”。
* secure
secure选项用来设置cookie只在确保安全的请求中才会发送。当请求是HTTPS或者其他安全协议时,包含 secure 选项的 cookie 才能被发送至服务器。
默认情况下,cookie不会带secure选项(即为空)。所以默认情况下,不管是HTTPS协议还是HTTP协议的请求,cookie都会被发送至服务端。但要注意一点,secure选项只是限定了在安全情况下才可以传输给服务端,但并不代表你不能看到这个 cookie。
下面我们设置一个 secure类型的 cookie:
之后你就能在控制台中看到这个 cookie 了,如下图所示:
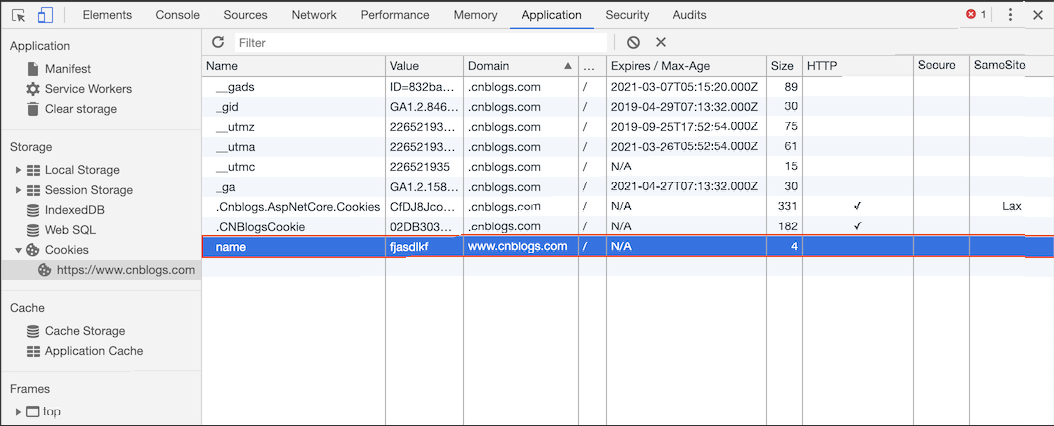
这里有个坑需要注意下:
如果想在客户端即网页中通过 js 去设置secure类型的 cookie,必须保证网页是https协议的。在http协议的网页中是无法设置secure类型cookie的。
* httpOnly
这个选项用来设置cookie是否能通过 js 去访问。默认情况下,cookie不会带httpOnly选项(即为空),所以默认情况下,客户端是可以通过js代码去访问(包括读取、修改、删除等)这个cookie的。当cookie带httpOnly选项时,客户端则无法通过js代码去访问(包括读取、修改、删除等)这个cookie。
在客户端是不能通过js代码去设置一个httpOnly类型的cookie的,这种类型的cookie只能通过服务端来设置。
那我们在页面中怎么知道哪些cookie是httpOnly类型的呢?看下图:
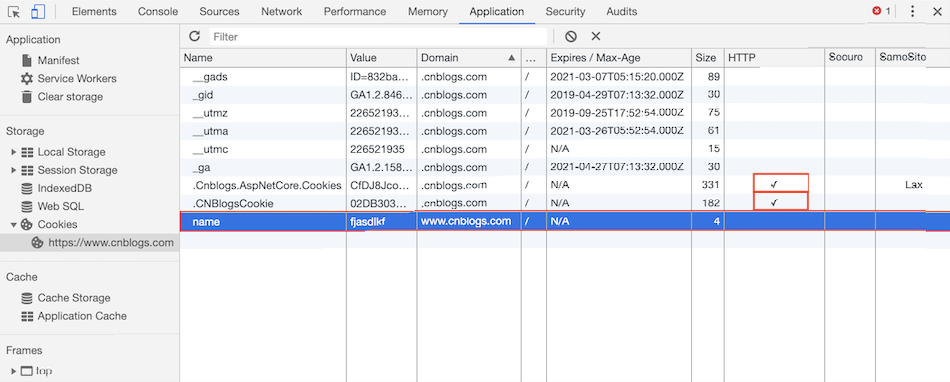
凡是httpOnly类型的cookie,其 HTTP 一列都会打上√,如上图中的PA_VTIME。你通过document.cookie是不能获取的,也不能修改PA_VTIME的。
——
httpOnly与安全从上面介绍中,大家是否会有这样的疑问:为什么我们要限制客户端去访问
cookie?其实这样做是为了保障安全。试想:如果任何 cookie 都能被客户端通过
document.cookie获取会发生什么可怕的事情。当我们的网页遭受了 XSS 攻击,有一段恶意的script脚本插到了网页中。这段script脚本做的事情是:通过document.cookie读取了用户身份验证相关的 cookie,并将这些 cookie 发送到了攻击者的服务器。攻击者轻而易举就拿到了用户身份验证信息,于是就可以摇摇大摆地冒充此用户访问你的服务器了(因为攻击者有合法的用户身份验证信息,所以会通过你服务器的验证)。
4.如何设置 cookie?
知道了cookie的格式,cookie的属性选项,接下来我们就可以设置cookie了。首先得明确一点:cookie既可以由服务端来设置,也可以由客户端来设置。
* 服务端设置 cookie
不管你是请求一个资源文件(如 html/js/css/图片),还是发送一个ajax请求,服务端都会返回response。而response header中有一项叫set-cookie,是服务端专门用来设置cookie的。如下图所示,服务端返回的response header中有5个set-cookie字段,每个字段对应一个cookie(注意不能将多个cookie放在一个set-cookie字段中),set-cookie字段的值就是普通的字符串,每个cookie还设置了相关属性选项。

注意:
一个
set-Cookie字段只能设置一个cookie,当你要想设置多个 cookie,需要添加同样多的set-Cookie字段。服务端可以设置cookie 的所有选项:
expires、domain、path、secure、HttpOnly
* 客户端设置 cookie
在网页即客户端中我们也可以通过js代码来设置cookie。如我当前打开的网址为https://www.cnblogs.com/,在控制台中我们执行了下面代码:
document.cookie = "name=Jonh; ";
查看浏览器 cookie 面板如下图所示,cookie确实设置成功了,而且属性选项 domain、path、expires都用了默认值。

再执行下面代码:
document.cookie="age=12; expires=Thu, 26 Feb 2116 11:50:25 GMT; domain=sankuai.com; path=/";
查看浏览器cookie 面板,如下图所示,新的cookie设置成功了,而且属性选项 domain、path、expires都变成了设定的值。

注意:
客户端可以设置cookie 的下列选项:
expires、domain、path、secure(有条件:只有在https协议的网页中,客户端设置secure类型的 cookie 才能成功),但无法设置HttpOnly选项。
* 用 js 如何设置多个 cookie
当要设置多个cookie时, js 代码很自然地我们会这么写:
document.cookie = "name=Jonh; age=12; class=111";
但你会发现这样写只是添加了第一个cookie“name=John”,后面的所有cookie都没有添加成功。所以最简单的设置多个cookie的方法就在重复执行document.cookie = "key=name",如下:
document.cookie = "name=Jonh";
document.cookie = "age=12";
document.cookie = "class=111";
5.如何修改、删除cookℹ️e
* 修改 cookie
要想修改一个cookie,只需要重新赋值就行,旧的值会被新的值覆盖。但要注意一点,在设置新cookie时,path/domain这几个选项一定要旧cookie 保持一样。否则不会修改旧值,而是添加了一个新的 cookie。
* 删除 cookie
删除一个cookie 也挺简单,也是重新赋值,只要将这个新cookie的expires 选项设置为一个过去的时间点就行了。但同样要注意,path/domain/这几个选项一定要旧cookie 保持一样。
6.cookie 编码
cookie其实是个字符串,但这个字符串中逗号、分号、空格被当做了特殊符号。所以当cookie的 key 和 value 中含有这3个特殊字符时,需要对其进行额外编码,一般会用escape进行编码,读取时用unescape进行解码;当然也可以用encodeURIComponent/decodeURIComponent或者encodeURI/decodeURI(三者的区别可以参考这篇文章)。
var key = escape("name;value");
var value = escape("this is a value contain , and ;");
document.cookie= key + "=" + value + "; expires=Thu, 26 Feb 2116 11:50:25 GMT; domain=sankuai.com; path=/";
7.跨域请求中 cookie
之前在介绍 XHR 的一篇文章里面提过:默认情况下,在发生跨域时,cookie 作为一种 credential 信息是不会被传送到服务端的。必须要进行额外设置才可以。具体原因和如何设置可以参考我的这篇文章:你真的会使用XMLHttpRequest吗?
另外,关于跨域资源共享 CORS极力推荐大家阅读阮一峰老师的这篇 跨域资源共享 CORS 详解。
8.总结补充
(1) 什么时候 cookie 会被覆盖:name/domain/path 这3个字段都相同的时候;
如果显式设置了 domain,则设置成什么,浏览器就存成什么;但如果没有显式设置,则浏览器会自动取 url 的 host 作为 domain 值;
新的规范中,显式设置 domain 时,如果 value 最前面带点,则浏览器处理时会将这个点去掉,所以最后浏览器存的就是没有点的(注意:但目前大多数浏览器并未全部这么实现)
前面带点‘.’和不带点‘.’有啥区别:
带点:任何 subdomain 都可以访问,包括父 domain
不带点:只有完全一样的域名才能访问,subdomain 不能(但在 IE 下比较特殊,它支持 subdomain 访问)
三,HTTP Cache
下面我贴出2道题,大家可以尝试解答下:
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>page页</title></head><body>
<img src="data:images/head.png" />
<a href="page.html">重新访问page页</a></body></html>
首次访问该页面,页面中 head.png 响应头信息如下:
HTTP/1.1 OK
Cache-Control: no-cache
Content-Type: image/png
Last-Modified: Tue, Nov :: GMT
Accept-Ranges: bytes
Date: Thu, Nov :: GMT
Content-Length:
问题1:请问当点击“重新访问 page 页”链接重新加载该页面后, head.png 如何二次加载?
问题2:如果将上述信息中的 Cache-Control 设置为 private,那么结果又会如何呢?
首先我将 Http 缓存体系分为以下三个部分: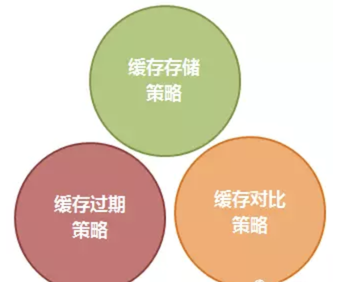
1. 缓存存储策略
用来确定 Http 响应内容是否可以被客户端缓存,以及可以被哪些客户端缓存
这个策略的作用只有一个,用于决定 Http 响应内容是否可缓存到客户端
对于 Cache-Control 头里的 Public、Private、no-cache、max-age 、no-store 他们都是用来指明响应内容是否可以被客户端存储的,其中前4个都会缓存文件数据(关于 no-cache 应理解为“不建议使用本地缓存”,其仍然会缓存数据到本地),后者 no-store 则不会在客户端缓存任何响应数据。另关于 no-cache 和 max-age 有点特别,我认为它是一种混合体,下面我会讲到。
通过 Cache-Control:Public 设置我们可以将 Http 响应数据存储到本地,但此时并不意味着后续浏览器会直接从缓存中读取数据并使用,为啥?因为它无法确定本地缓存的数据是否可用(可能已经失效),还必须借助一套鉴别机制来确认才行, 这就是我们下面要讲到的“缓存过期策略”。
2. 缓存过期策略
客户端用来确认存储在本地的缓存数据是否已过期,进而决定是否要发请求到服务端获取数据
这个策略的作用也只有一个,那就是决定客户端是否可直接从本地缓存数据中加载数据并展示(否则就发请求到服务端获取)
刚上面我们已经阐述了数据缓存到了本地后还需要经过判断才能使用,那么浏览器通过什么条件来判断呢? 答案是:Expires,Expires 指名了缓存数据有效的绝对时间,告诉客户端到了这个时间点(比照客户端时间点)后本地缓存就作废了,在这个时间点内客户端可以认为缓存数据有效,可直接从缓存中加载展示。
不过 Http 缓存头设计并没有想象的那么规矩,像上面提到的 Cache-Control(这个头是在Http1.1里加进来的)头里的 no-cache 和 max-age 就是特例,它们既包含缓存存储策略也包含缓存过期策略,以 max-age 为例,他实际上相当于:
Cache-Control:public/private(这里不太确定具体哪个)
Expires:当前客户端时间 + maxAge 。
而 Cache-Control:no-cache 和 Cache-Control:max-age=0 (单位是秒)相当
这里需要注意的是:
Cache-Control 中指定的缓存过期策略优先级高于 Expires,当它们同时存在的时候,后者会被覆盖掉。
缓存数据标记为已过期只是告诉客户端不能再直接从本地读取缓存了,需要再发一次请求到服务器去确认,并不等同于本地缓存数据从此就没用了,有些情况下即使过期了还是会被再次用到,具体下面会讲到。
3. 缓存对比策略
将缓存在客户端的数据标识发往服务端,服务端通过标识来判断客户端 缓存数据是否仍有效,进而决定是否要重发数据。
客户端检测到数据过期或浏览器刷新后,往往会重新发起一个 http 请求到服务器,服务器此时并不急于返回数据,而是看请求头有没有带标识( If-Modified-Since、If-None-Match)过来,如果判断标识仍然有效,则返回304告诉客户端取本地缓存数据来用即可(这里要注意的是你必须要在首次响应时输出相应的头信息(Last-Modified、ETags)到客户端)。至此我们就明白了上面所说的本地缓存数据即使被认为过期,并不等于数据从此就没用了的道理了。
关于 Last-Modified,这个响应头使用要注意,可能会影响到缓存过期策略,具体原因,后面我会通过解答开篇提到的2道题来作说明。
以上就是我所认识的缓存策略,下面我将缓存策略三要素和常用的几个缓存头(项)结合一起,让大家更清晰的认识到它们之间的关系:
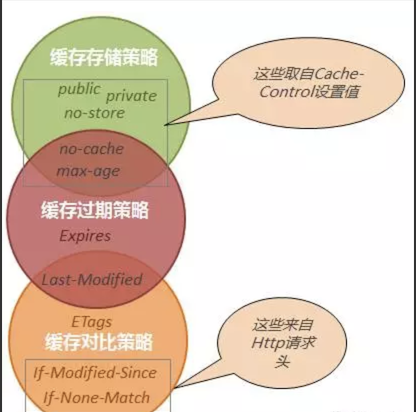
通过上图我可以清晰的看到各缓存项分别属于哪个缓存策略范畴,这其中有部分重叠,它表明这些缓存项具有多重缓存策略,所以实际在分析缓存头的时候,除了常规的头外,我们还需要将这些具有双重缓存策略的项分解开来。
最后我们回到最开始提到的2道题目,我们来一起分解下:
第一道题:
HTTP/1.1 OK
Cache-Control: no-cache
Content-Type: image/png
Last-Modified: Tue, Nov :: GMT
Accept-Ranges: bytes
Date: Thu, Nov :: GMT
Content-Length:
分析上述 Http 响应头发现有以下两项与缓存相关:
Cache-Control: no-cache
Last-Modified: Tue, Nov :: GMT
我们上面讲到了 Cache-Control: no-cache 相当于 Cache-Control: max-age=0,且他们都是多重策略头,我们需将其分解:
Cache-Control: no-cache 等于 Cache-Control: max-age=0,
接着 Cache-Control: max-age=0 又可分解成:
Cache-Control: public/private (不确定是二者中的哪一个)
Expires: 当前时间
最终我们得到了以下完整的缓存策略三要素:

所以最终结果是:浏览器会再次请求服务端,并携带上 Last-Modified 指定的时间去服务器对比:
a)对比失败:服务器返回200并重发数据,客户端接收到数据后展示,并刷新本地缓存。
b)对比成功:服务器返回304且不重发数据,客户端收到304状态码后从本地读取缓存数据。以下为模拟此种情况下请求后的抓包情况:

这道题本身不难,但若认为 no-cache 不会缓存数据到本地,那么你理解起来就会很矛盾,因为如果文件数据没有被本地缓存,服务器返回304后将会无法展示出图片内容,但实际上它是能正常展示的。这道题很好的证明了 no-cache 也会缓存数据到本地这一说法。
第二道题:
HTTP/1.1 OK
Cache-Control: private
Content-Type: image/png
Last-Modified: Tue, Nov :: GMT
Accept-Ranges: bytes
Date: Thu, Nov :: GMT
Content-Length:
解题思路和上题一样,首先先找到缓存相关项:
Cache-Control: private
Last-Modified: Tue, Nov :: GMT
浏览器后续请求都直接取的本地缓存,看来的确存在某种缓存过期策略(根据我上面的缓存过期策略理论,浏览器如果直接从本地加载缓存数据,说明它相信本地缓存数据有效,那一定存在某种缓存过期判断条件)。这个问题百思不得其解,困扰了我好久,直到一次偶然的机会我在 Fiddler 响应信息面板里的 Caching 选项卡中找到了答案:
原来,在没有提供任何浏览器缓存过期策略的情况下,浏览器遵循一个启发式缓存过期策略:
根据响应头中2个时间字段 Date 和 Last-Modified 之间的时间差值,取其值的10%作为缓存时间周期。
最终我们得到了以下完整的缓存策略三要素:
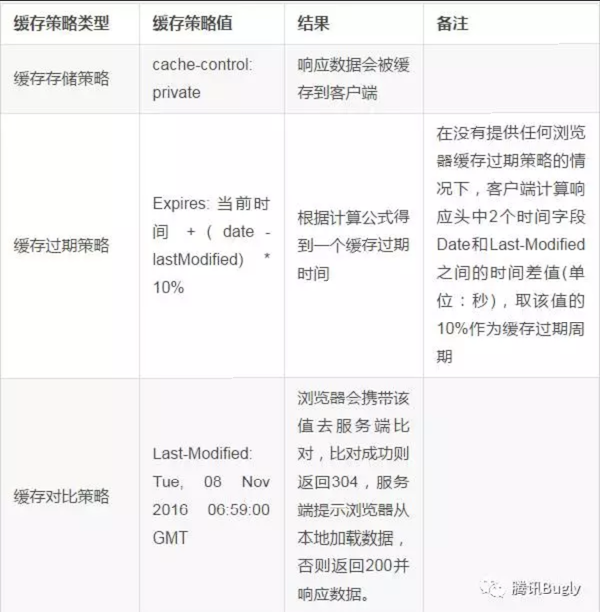
最终结果
浏览器会根据 Date 和 Last-Modified 之间的时间差值缓存一段时间,这段时间内会直接使用本地缓存数据而不会再去请求服务器(强制请求除外),缓存过期后,会再次请求服务端,并携带上 Last-Modified 指定的时间去服务器对比并根据服务端的响应状态决定是否要从本地加载缓存数据。
关于HTTP协议学习(二)的更多相关文章
- TCP/IP协议学习(二) LWIP用户自定义配置文件解析
LWIP协议支持用户配置,可以通过用户裁剪实现最优化配置,LWIP默认包含opts.h作为系统默认配置,不过通过添加lwipopts.h文件并包含在opts.h头文件之前就可以对lwip进行用户裁剪, ...
- HTTP协议学习笔记(二)
HTTP协议学习笔记(二) 1.HTTP报文 HTTP报文:用于HTTP协议交互的信息.请求报文:请求端(客户端)的HTTP报文叫做请求报文.响应报文:响应端(服务端)的HTTP报文叫做响应报文. H ...
- BGP协议学习总结
BGP学习总结 BGP是目前使用的唯一的自治系统间的路由协议,它是一种矢量路由协议,基于TCP的179号端口,它采用单播增量更新的方式更新路由,与其他的路由协议不同的是,BGP只要TCP可达,就可以建 ...
- TCP/IP协议学习之实例ping命令学习笔记
TCP/IP协议学习之实例ping命令学习笔记(一) 一. 目的为了让网络协议学习更有效果,在真实网络上进行ping命令前相关知识的学习,暂时不管DNS,在内网中,进行2台主机间的ping命令的整个详 ...
- TCP/IP协议学习(五) 基于C# Socket的C/S模型
TCP/IP协议作为现代网络通讯的基石,内容包罗万象,直接去理解理论是比较困难的:然而通过实践先理解网络通讯的理解,在反过来理解学习TCP/IP协议栈就相对简单很多.C#通过提供的Socket API ...
- emberjs学习二(ember-data和localstorage_adapter)
emberjs学习二(ember-data和localstorage_adapter) 准备工作 首先我们加入ember-data和ember-localstorage-adapter两个依赖项,使用 ...
- ReactJS入门学习二
ReactJS入门学习二 阅读目录 React的背景和基本原理 理解React.render() 什么是JSX? 为什么要使用JSX? JSX的语法 如何在JSX中如何使用事件 如何在JSX中如何使用 ...
- http协议学习系列
深入理解HTTP协议(转) http://www.blogjava.net/zjusuyong/articles/304788.html http协议学习系列 1. 基础概念篇 1.1 介绍 H ...
- HTTPS协议学习总结
目录 一:什么是HTTPS协议?二:客户端与服务端如何建立HTTPS协议连接?三:证书.加密协议.信息摘要.签名算法概念解释与关系梳理四:低版本操作系统作为客户端发送HTTPS失败分析五:参考资料 ...
- TweenMax动画库学习(二)
目录 TweenMax动画库学习(一) TweenMax动画库学习(二) TweenMax动画库学习(三) Tw ...
随机推荐
- 什么是DAPP
DAPP(Decentralized Application)去中心化的应用 DAPP可以是网站,也可以是手机app,只要主要逻辑和数据在区块链上就可以 在以太坊平台上,一个DAPP肯定基于一个或多个 ...
- WebService - [Debug] java.net.BindException: Can't assign requested address
Connected to the target VM, address: '127.0.0.1:57803', transport: 'socket' Exception in thread &quo ...
- PHP 【三】
字符串变量 $txt = "Hello world!"; 创建字符串后,就可以对它操作,可以在函数中使用,或者把它存储在变量中 并置运算符 [把两个字符串值连接起来] <?p ...
- PostgreSQL快速入门
一.PostgreSQL是什么? PostgreSQL是一个功能强大的开源对象关系数据库管理系统(ORDBMS). 用于安全地存储数据; 支持最佳做法,并允许在处理请求时检索它们. PostgreSQ ...
- Python 爬虫 某迅漫画 selemiun+plantomJS
目标站点需求分析 爬取某迅漫画到本地 涉及的库 selenium, PhantomJS time,urllib.request,os,random 模拟滑动窗口,获取完整网页 保存到文件中 获取本地h ...
- hdu3555数位dp基础
/* dp[i][0|1|2]:没有49的个数|最高位是9,没有49的个数|有49的个数 dp[i][0]=10*dp[i-1][0]-dp[i-1][1] dp[i][1]=dp[i-1][0] d ...
- MySql新增表的字段,删除表字段
1增加两个字段: create table id_name(id int,name varchar(20));//创建原始数据表 alter table id_name add age int,add ...
- redis-hash操作
hset(name, key, value) # name对应的hash中设置一个键值对(不存在,则创建:否则,修改) # 参数: # name,redis的name # key,name对应的has ...
- ReSharper反编译C#类库
经常会在使用C#类中的某个函数时想了解其中具体的代码,可是F12转到定义后只能看到函数简单的声明, 看不到方法体中的代码,这挺让人沮丧的.. 如下: F12进入后显示的是元数据, Equals函数只能 ...
- python运算符——比较运算符
比较运算符的运算结果会得到一个bool类型,也就是逻辑判定,要么是真True,要不就是False 大于“>” 小于“<” 不说了,看看不等于,用“!=”表示.大于等于“>=”和小 ...