HDFS概述
HDFS概述
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HDFS产出背景及定义
1>.HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理磁盘中,但是不方便维护和管理,迫切需求一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
2>.HDFS定义
HDFS全称为:Hadoop Distributed File System,它是一个文件系统,用于存储文件,通过目录树来定位;其次,他是分布式的,由很多服务联合起来实现其功能,集群中的服务器有各自的角色。
3>.HDFS的使用场景
适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
二.HDFS优缺点
1>.优点
一.高容错性
>.数据自动保存多个副本,它通过增加副本的形式,提高容错性;
>.某一个副本丢失以后,它可以自动恢复; 二.适合处理大数据
>.数据规模:能够处理数据规模达到GB,TB,甚至PB级别的数据;
>.文件规模:能够处理百万规模以上的文件数量,数量相当之大; 三.可构建在廉价机器上,通过多副本机智,提高可靠性。
2>.缺点
一.不适合低延迟数据访问,比如毫秒级的存储数据,是做不到的; 二.无法高效的对大量小文件进行存储
>.存储大量小文件的话,他会占用NameNode大量的内存来存储文件目录块信息。这样是不可取的,因为NameNode的内存总是有限的;
>.小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标; 三.不支持并发写入,文件随机修改
>.一个文件只能有一个写,不允许多个线程同时写;
>.仅支持数据append(追加),不支持文件的随机修改。
三.HDFS组成架构
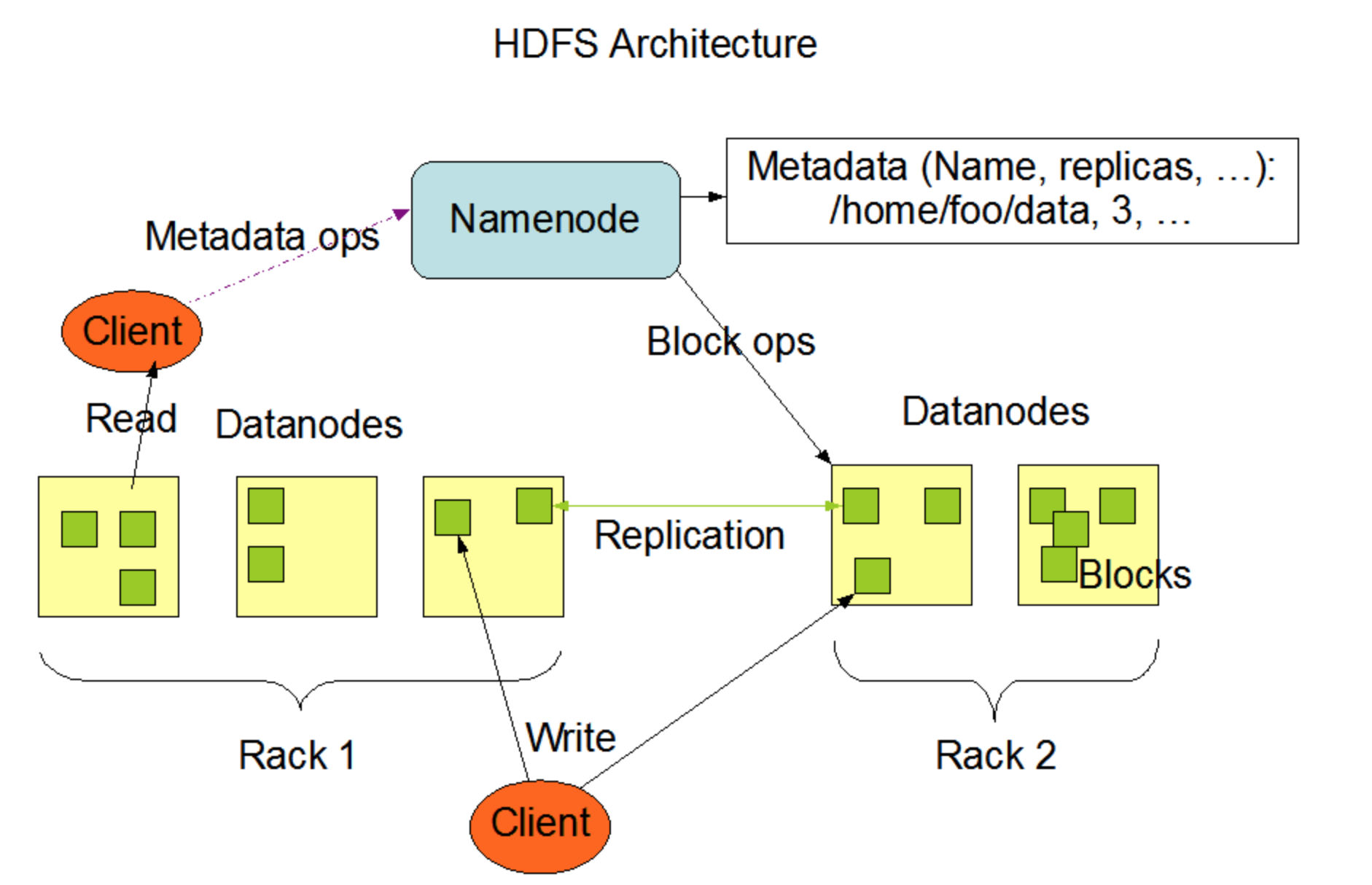
一.NameNode
就是Master,他是一个主管,管理者。
>.管理HDFS的名称空间;
>.配置副本策略;
>.管理数据块(Block)映射信息;
>.处理客户端读写请求; 二.DataNode
就是Slave。NameNode下达命令,DataNode执行实际的操作。
>.存储实际的数据块;
>.执行数据块的读/写操作; 三.Client
就是客户端。
>.文件切分,文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
>.与NameNode交互,获取文件的位置信息;
>.与Datanode交互,读取或者写入数据;
>.Client提供一些命令来管理HDFS,比如NameNode格式化;
>.Client可以通过一些命令来访问HDFS,比如对HDFS增删改查操作; 四.Secondary NameNode
并非NameNode的热备,当NameNode刮掉的时候,它并不能马上替换NameNode并提供服务。
>.辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
>.在紧急情况下,可辅助恢复NameNode;
四.HDFS文件块大小
HDFS中文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.x版本是128M,在Hadoop1.x版本中是64M。
一.为什么Hadoop2.x版本中是128M
>.如果寻址时间为10ms,即查找到目标的bolck的时间为10ms;
>.寻址时间为传输时间的1%时,则为最佳状态。因此,传输时间=寻址时间/0.01=10ms/0.01=1000ms=1s
>.而目前磁盘的传输速度普遍为100MB/s
>.因此block的大小为=1s*100MB/s=100M
>.这个100M在外国的程序员无法用二进制表示,于是开发人员为了方便好记就找了一个二进制和改制相似的数字设置为默认值,因此Hadoop默认的大小为128MB。当然,这是为脑补出来的答案,哈哈哈~ 二.为什么块的大小不能设置太小,也不能设置太大?
>.HDFS的块设置太小,会增加寻址时间,呈现一直在找块的开始位置;
>.如果块设置的太大,从磁盘传输数据的时间会明显大雨定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。 总结:HDFS块的大小设置,主要取决于磁盘传输速度。随着科技的发展,磁盘的速度在不久的将来也会有所提高的,而Hadoop的版本默认值也会在不断的变大,这是很合理的。
关于如何测试磁盘的读写速度,可参考我之前的笔记:https://www.cnblogs.com/yinzhengjie/p/9935478.html。
HDFS概述的更多相关文章
- HDFS概述(一)
HDFS概述(一) 1. HDFS产出的背景及定义 1.1 HDFS产生的背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需 ...
- HDFS概述和Shell操作
大数据技术之Hadoop(HDFS) 第一章 HDFS概述 HDFS组成架构 HDFS文件块大小 第二章 HDFS的Shell操作(开发重点) 1.基本语法 bin/hadoop fs 具体命令 ...
- HDFS概述(6)————用户手册
目的 本文档是使用Hadoop分布式文件系统(HDFS)作为Hadoop集群或独立通用分布式文件系统的一部分的用户的起点.虽然HDFS旨在在许多环境中"正常工作",但HDFS的工作 ...
- HDFS概述(5)————HDFS HA
HA With QJM 目标 本指南概述了HDFS高可用性(HA)功能以及如何使用Quorum Journal Manager(QJM)功能配置和管理HA HDFS集群. 本文档假设读者对HDFS集群 ...
- HDFS概述(4)————HDFS权限
概述 Hadoop分布式文件系统(HDFS)的权限模型与POSIX模型的文件和目录权限模型一致.每个文件和目录与所有者和组相关联.该文件或目录将权限划分为所有者的权限,作为该组成员的其他用户的权限.以 ...
- HDFS概述(3)————HDFS Federation
本指南概述了HDFS Federation功能以及如何配置和管理联合集群. 当前HDFS背景 HDFS主要有两层: 1.Namespace (1)包含目录,文件和块. (2)它支持所有命名空间相关的文 ...
- HDFS概述(1)————HDFS架构
概述 Hadoop分布式文件系统(HDFS)是一种分布式文件系统,用于在普通商用硬件上运行.它与现有的分布式文件系统有许多相似之处.然而,与其他分布式文件系统的区别很大.HDFS具有高度的容错能力,旨 ...
- HDFS概述(2)————Block块大小设置
以下内容转自:http://blog.csdn.net/samhacker/article/details/23089157?utm_source=tuicool&utm_medium=ref ...
- Hadoop之HDFS概述
一.HDFS产生背景及定义 1.HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文 ...
随机推荐
- Android深入理解Context(一)Context关联类和Application Context创建过程
前言 Context也就是上下文对象,是Android较为常用的类,但是对于Context,很多人都停留在会用的阶段,这个系列会带大家从源码角度来分析Context,从而更加深入的理解它. 1.Con ...
- vue.js 学习笔记3——TypeScript
目录 vue.js 学习笔记3--TypeScript 工具 基础类型 数组 元组 枚举 字面量 接口 类类型 类类型要素 函数 函数参数 this对象和类型 重载 迭代器 Symbol.iterat ...
- 【English】十二、英语句子种类,陈述句、疑问句、祈使句、感叹句
一.英语句子按照用途可以分为4类 种类.用途.例句 陈述句 用于说明事实或说话人的看法(事实不就是别人发起并被同意的看法) My name is Jennt Green. I like him bec ...
- Python基础之if判断,while循环,循环嵌套
if判断 判断的定义 如果条件满足,就做一件事:条件不满足,就做另一件事: 判断语句又被称为分支语句,有判断,才有分支: if判断语句基本语法 if语句格式: if 判断的条件: 条件成立后做的事 . ...
- 【spring源码分析】IOC容器初始化(五)
前言:前几篇文章已经将BeanDefinition的加载过程大致分析完成,接下来继续分析其他过程. AbstractApplicationContext#refresh public void ref ...
- 【原创】小说:我是一条DQL
SQL执行流程图如下 本文改编自<高性能Mysql>,烟哥用小说的形式来讲这个内容. 序章 自我介绍 我是一条sql,就是一条长长的字符串,不要问我长什么样,因为我比较傲娇. 额~~不是我 ...
- Java的基本类型和包装类型
测试的JDK版本:java version "1.7.0_79".Java的9中基本类型:void.char.boolean.byte.short.int.long.float.d ...
- C语言之将弧度值转换为角度值
#include<stdio.h> #include<stdlib.h> #define pi 3.141592 void conver_radian(float radian ...
- Quick Sort(三向切分的快速排序)(Java)
//三向切分的快速排序 //这种切分方法对于数组中有大量重复元素的情况有比较大的性能提升 public static void main(String[] args) { Scanner input ...
- EXCEL记录
ー.重要快捷键 Ctrl + F → 查找 Ctrl + H → 替换 Ctrl + G → 定位 Ctrl + 1 → 设置单元格格式 Ctrl + Enter → 一并输入多个单元格 Ctrl + ...