HashMap线程不安全的体现
前言:我们都知道HashMap是线程不安全的,在多线程环境中不建议使用,但是其线程不安全主要体现在什么地方呢,本文将对该问题进行解密。
1.jdk1.7中的HashMap
在jdk1.8中对HashMap做了很多优化,这里先分析在jdk1.7中的问题,相信大家都知道在jdk1.7多线程环境下HashMap容易出现死循环,这里我们先用代码来模拟出现死循环的情况:
public class HashMapTest {
public static void main(String[] args) {
HashMapThread thread0 = new HashMapThread();
HashMapThread thread1 = new HashMapThread();
HashMapThread thread2 = new HashMapThread();
HashMapThread thread3 = new HashMapThread();
HashMapThread thread4 = new HashMapThread();
thread0.start();
thread1.start();
thread2.start();
thread3.start();
thread4.start();
}
}
class HashMapThread extends Thread {
private static AtomicInteger ai = new AtomicInteger();
private static Map<Integer, Integer> map = new HashMap<>();
@Override
public void run() {
while (ai.get() < 1000000) {
map.put(ai.get(), ai.get());
ai.incrementAndGet();
}
}
}
上述代码比较简单,就是开多个线程不断进行put操作,并且HashMap与AtomicInteger都是全局共享的。在多运行几次该代码后,出现如下死循环情形:
其中有几次还会出现数组越界的情况:

这里我们着重分析为什么会出现死循环的情况,通过jps和jstack命名查看死循环情况,结果如下:
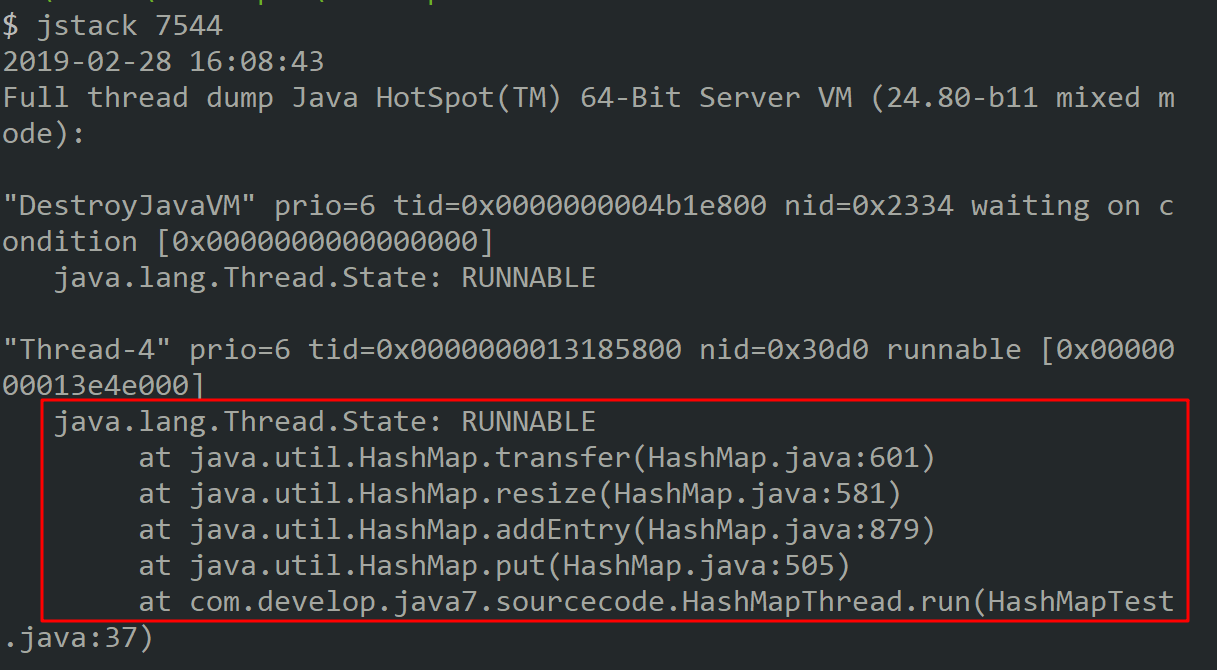
从堆栈信息中可以看到出现死循环的位置,通过该信息可明确知道死循环发生在HashMap的扩容函数中,根源在transfer函数中,jdk1.7中HashMap的transfer函数如下:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
总结下该函数的主要作用:
在对table进行扩容到newTable后,需要将原来数据转移到newTable中,注意10-12行代码,这里可以看出在转移元素的过程中,使用的是头插法,也就是链表的顺序会翻转,这里也是形成死循环的关键点。下面进行详细分析。
1.1 扩容造成死循环分析过程
前提条件:
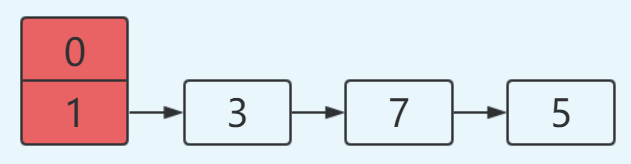
这里假设
#1.hash算法为简单的用key mod链表的大小。
#2.最开始hash表size=2,key=3,7,5,则都在table[1]中。
#3.然后进行resize,使size变成4。
未resize前的数据结构如下:
如果在单线程环境下,最后的结果如下:
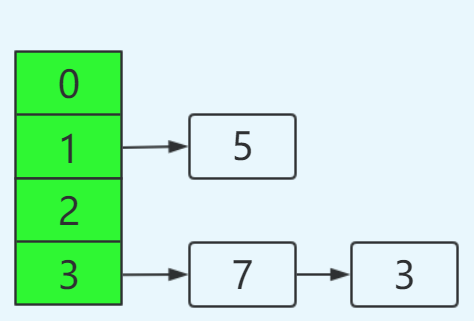
这里的转移过程,不再进行详述,只要理解transfer函数在做什么,其转移过程以及如何对链表进行反转应该不难。
然后在多线程环境下,假设有两个线程A和B都在进行put操作。线程A在执行到transfer函数中第11行代码处挂起,因为该函数在这里分析的地位非常重要,因此再次贴出来。

此时线程A中运行结果如下:
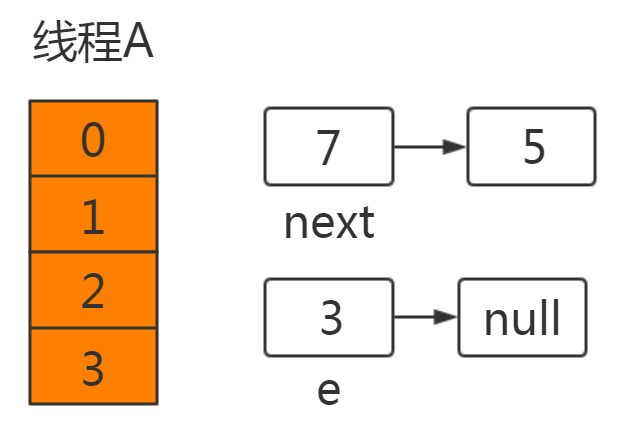
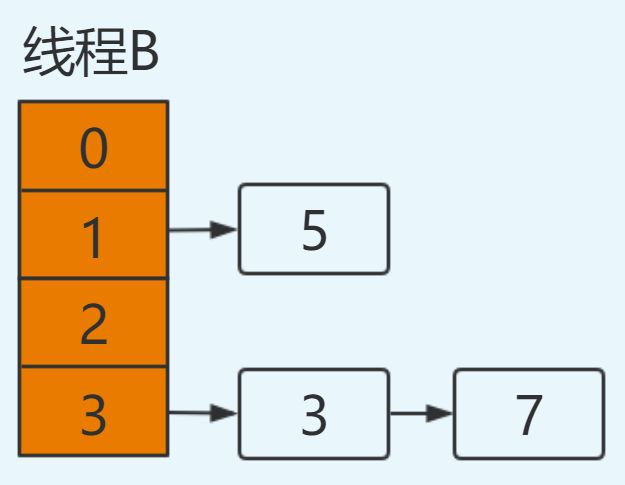
线程A挂起后,此时线程B正常执行,并完成resize操作,结果如下:
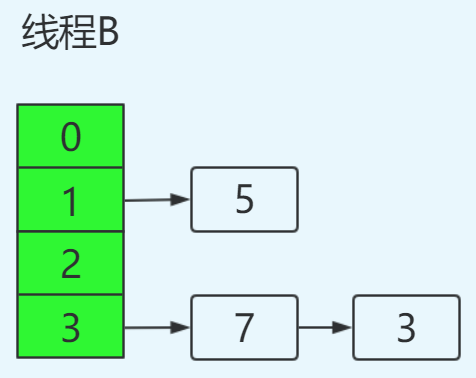
这里需要特别注意的点:由于线程B已经执行完毕,根据Java内存模型,现在newTable和table中的Entry都是主存中最新值:7.next=3,3.next=null。
此时切换到线程A上,在线程A挂起时内存中值如下:e=3,next=7,newTable[3]=null,代码执行过程如下:
newTable[3]=e ----> newTable[3]=3
e=next ----> e=7
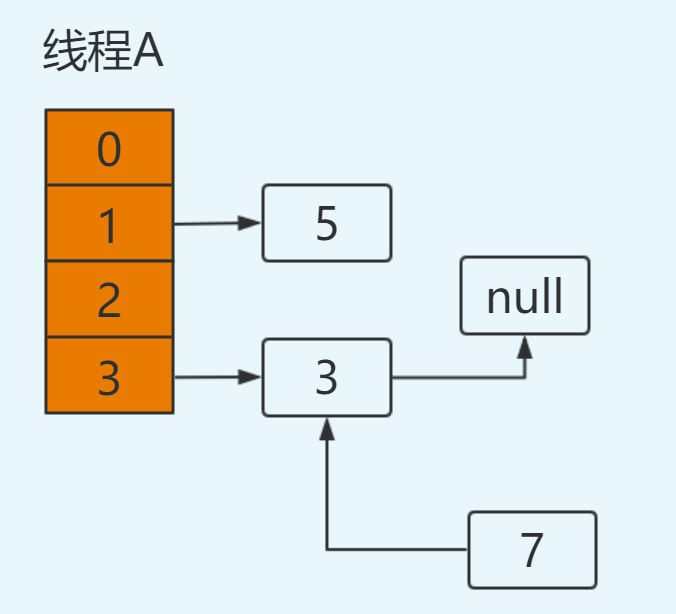
继续循环:
e=7
next=e.next ----> next=3【从主存中取值】
e.next=newTable[3] ----> e.next=3【从主存中取值】
newTable[3]=e ----> newTable[3]=7
e=next ----> e=3
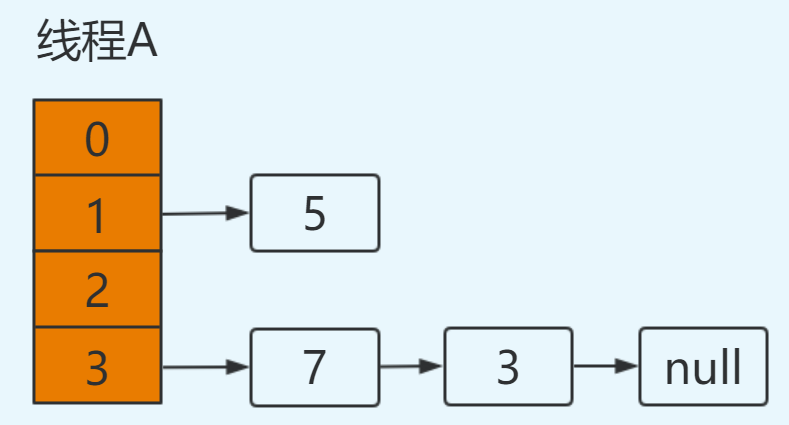
再次进行循环:
e=3
next=e.next ----> next=null
e.next=newTable[3] ----> e.next=7 即:3.next=7
newTable[3]=e ----> newTable[3]=3
e=next ----> e=null
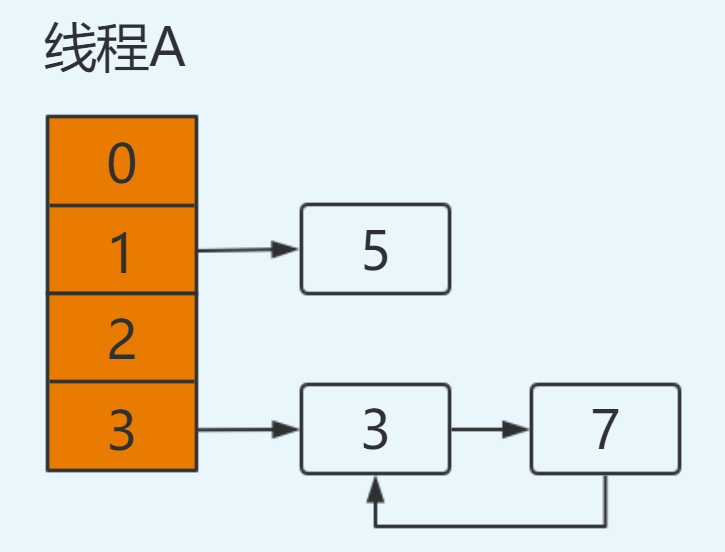
在后续操作中只要涉及轮询hashmap的数据结构,就会在这里发生死循环,造成悲剧。
1.2 扩容造成数据丢失分析过程
遵照上述分析过程,初始时:
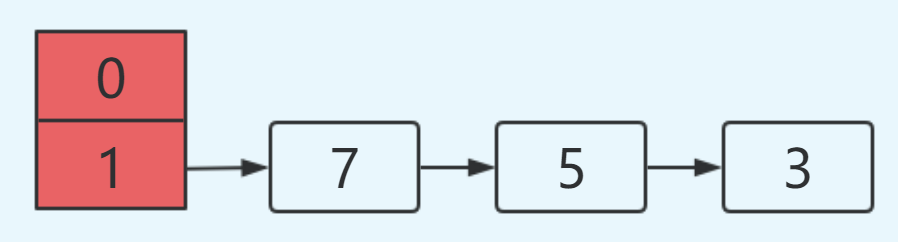
线程A和线程B进行put操作,同样线程A挂起:

此时线程A的运行结果如下:
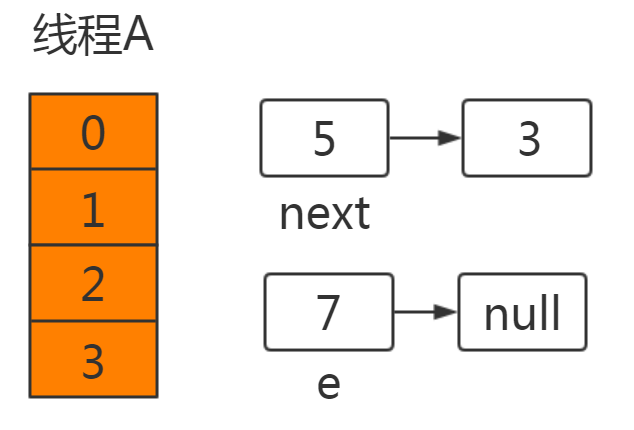
此时线程B已获得CPU时间片,并完成resize操作:
同样注意由于线程B执行完成,newTable和table都为最新值:5.next=null。
此时切换到线程A,在线程A挂起时:e=7,next=5,newTable[3]=null。
执行newtable[i]=e,就将7放在了table[3]的位置,此时next=5。接着进行下一次循环:
e=5
next=e.next ----> next=null,从主存中取值
e.next=newTable[1] ----> e.next=5,从主存中取值
newTable[1]=e ----> newTable[1]=5
e=next ----> e=null
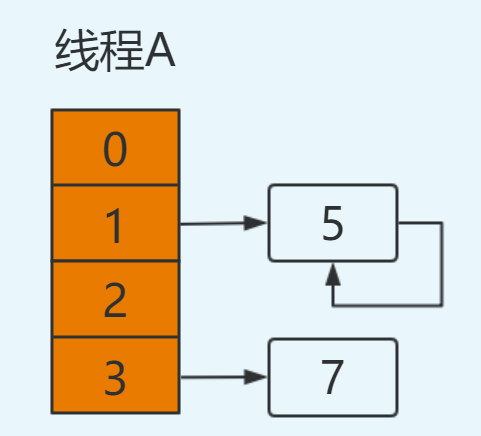
2.jdk1.8中HashMap
在jdk1.8中对HashMap进行了优化,在发生hash碰撞,不再采用头插法方式,而是直接插入链表尾部,因此不会出现环形链表的情况,但是在多线程的情况下仍然不安全,这里我们看jdk1.8中HashMap的put操作源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有hash碰撞则直接插入元素
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
这是jdk1.8中HashMap中put操作的主函数, 注意第6行代码,如果没有hash碰撞则会直接插入元素。如果线程A和线程B同时进行put操作,刚好这两条不同的数据hash值一样,并且该位置数据为null,所以这线程A、B都会进入第6行代码中。假设一种情况,线程A进入后还未进行数据插入时挂起,而线程B正常执行,从而正常插入数据,然后线程A获取CPU时间片,此时线程A不用再进行hash判断了,问题出现:线程A会把线程B插入的数据给覆盖,发生线程不安全。
这里只是简要分析下jdk1.8中HashMap出现的线程不安全问题的体现,后续将会对java的集合框架进行总结,到时再进行具体分析。
总结
首先HashMap是线程不安全的,其主要体现:
#1.在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失。
#2.在jdk1.8中,在多线程环境下,会发生数据覆盖的情况。
by Shawn Chen,2019.03.02,上午。
HashMap线程不安全的体现的更多相关文章
- 谈谈HashMap线程不安全的体现
原文出处: Hosee HashMap的原理以及如何实现,之前在JDK7与JDK8中HashMap的实现中已经说明了. 那么,为什么说HashMap是线程不安全的呢?它在多线程环境下,会发生什么情况呢 ...
- Java基础知识强化之集合框架笔记80:HashMap的线程不安全性的体现
1. HashMap 的线程不安全性的体现: 主要是下面两方面: (1)多线程环境下,多个线程同时resize()时候,容易产生死锁现象.即:resize死循环 (2)如果在使用迭代器的过程中有其他线 ...
- HashMap的实现原理?如何保证HashMap线程安全?
A:HashMap简单说就是它根据建的hashcode值存储数据的,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历的顺序是不确定的. B:HashMap基于哈希表,底层结构由数组来实 ...
- (转载)两种方法让HashMap线程安全
HashMap不是线程安全的,往往在写程序时需要通过一些方法来回避.其实JDK原生的提供了2种方法让HashMap支持线程安全. 方法一:通过Collections.synchronizedMap() ...
- HashMap&线程
1.HashMap概念 HashMap是一个散列表,存储内容是键值对(key-value)的映射, HashMap继承了AbstractMap,实现了Map.Cloneable.java.io.Ser ...
- 为什么HashMap线程不安全,Hashtable和ConcurrentHashMap线程安全
HashMap源码 public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final ...
- 如何保证HashMap线程安全
可使用Java 1.5推荐的java.util.concurrent包ConcurrentHashMap来实现,内部不再使用类似HashTable的synchronized同步锁,而是使用Reentr ...
- HashMap源码分析(一)
前言:相信不管在生产过程中还是面试过程中,HashMap出现的几率都非常的大,因此有必要对其源码进行分析,但要注意的是jdk1.8对HashMap进行了大量的优化,因此笔者会根据不同版本对HashMa ...
- 【Java】几道常见的秋招面试题
前言 只有光头才能变强 Redis目前还在看,今天来分享一下我在秋招看过(遇到)的一些面试题(相对比较常见的) 0.final关键字 简要说一下final关键字,final可以用来修饰什么? 这题我是 ...
随机推荐
- react~props和state的介绍与使用
props是参数的传递,从上层模块向下层模块进行拿传递:而state是提局域变量,一般在本模块内使用,props是不能改变的,而state可以通过setState去修改自身的值. props Reac ...
- Windows证书操作
查看证书 在快捷命令栏输入mmc打开控制台 选择文件-->添加或删除管理单元 添加,选择计算机账户,本地计算机 添加完成证书后可以将localhost证书删除 生成localhost证书 打开v ...
- Magicodes.WeiChat——发送模板消息
在微信开发中,经常会使用到模板消息.因此框架中对此进行了一些封装,并且提供了后台操作界面以及日志查看等功能,下面开始逐步介绍开发操作以及使用. 微信公众平台配置 首先,需要申请开通模板消息功能,如下图 ...
- shell32.dll 控制网络
//禁用 SetNetworkAdapter(False) //启用 SetNetworkAdapter(True) //添加引用system32/shell32.dll private static ...
- PHP反射原理的实现
反射 反射,直观理解就是根据到达地找到出发地和来源.我们可以仅仅通过一个光秃秃对象就能知道它所属的类.拥有哪些方法. 反射是指在PHP运行状态中,扩展分析PHP程序,导出或提出关于类.方法.属性.参数 ...
- openjduge 求简单表达式的值
表达式求值 总时间限制: 10000ms 单个测试点时间限制: 1000ms 内存限制: 131072kB 给定一个只包含加法和乘法的算术表达式,请你编程计算表达式的值. 输入 输入仅有一行 ...
- 原生js实现数据单向绑定
Object.defineProperty()方法直接在对象上定义一个新属性,或修改对象上的现有属性,并返回该对象. Object.defineProperty(obj, prop, descript ...
- 【转】Js正则表达式
//校验是否全由数字组成 var patrn=/^[0-9]{1,20}$/ //校验登录名:只能输入5-20个以字母开头.可带数字.“_”.“.”的字串 var patrn=/^[a-zA-Z]{1 ...
- 程序员奇谈之我写的程序不可能有bug篇
程序员在普通人的印象里是一份严(ku)谨(bi)的职业,也是一个被搞怪吐槽乐此不疲的职业,程序员们面对复杂的代码敲打电脑时连眉头都不会皱一下,但是有一个词却是他们痛苦的根源,它就是Bug. 有不少的新 ...
- centos7 + python 2.7 + pip + openvswitch 杂项问题
问题1: virtual box 安装centos7 后,网口无ip, 解决方法是:配置网口上电后,默认状态为down, 修改“onboot=yes”, 修改后保存配置重启系统. 2. 安装pip的 ...