【野草】SQL Server之索引解析(二)
堆表通过IAM连接一起,查询时全表扫描。
结构
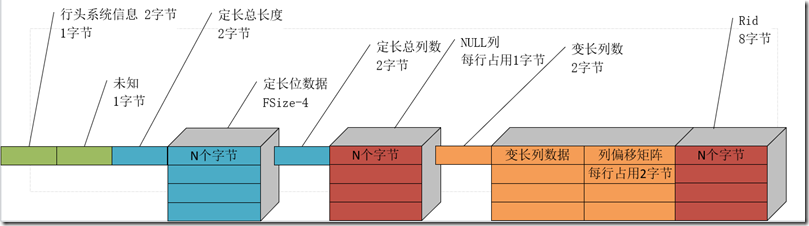
- 中间节点数据结构:
中间2字节有疑问?
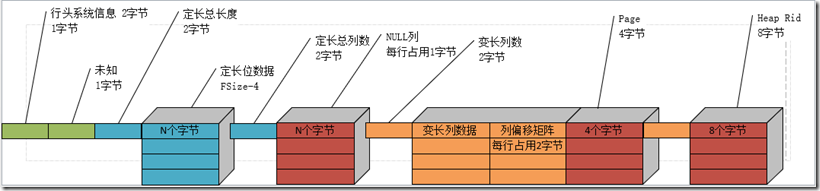
- (非聚集唯一索引)行数据结构+分割符?+ Page(4)
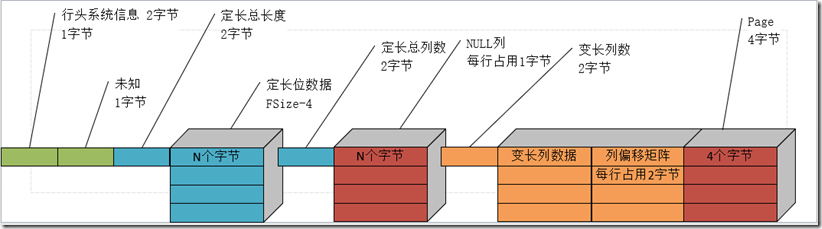
- 堆表非聚集索引结构
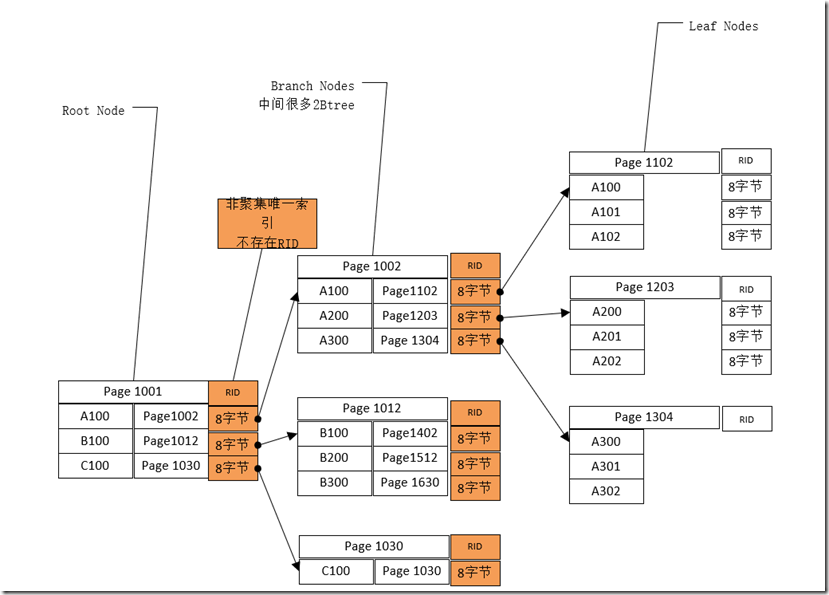
组织结构
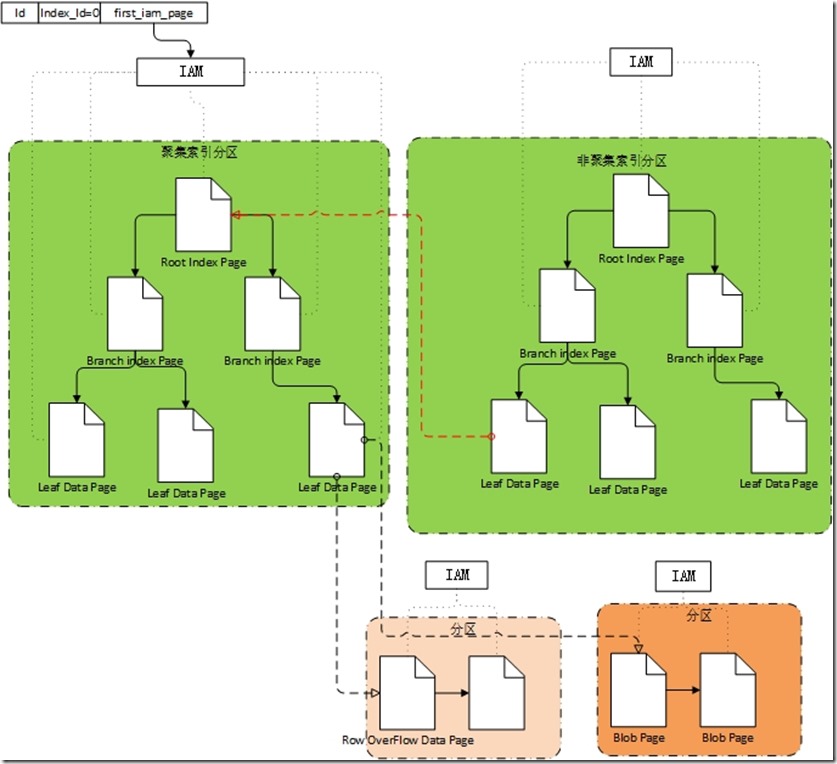
聚集索引表由根节点(Root Node)、中间节点(Branch Nodes)、叶子节点组成。
如果叶子节点不够多时,根节点(Root Node)、中间节点(Branch Nodes)将不存在。
- 根节点、中间节点行结构
- 系统头部信息(2字节)+Key+&+PageId
- 叶子节点
- 参见行数据结构
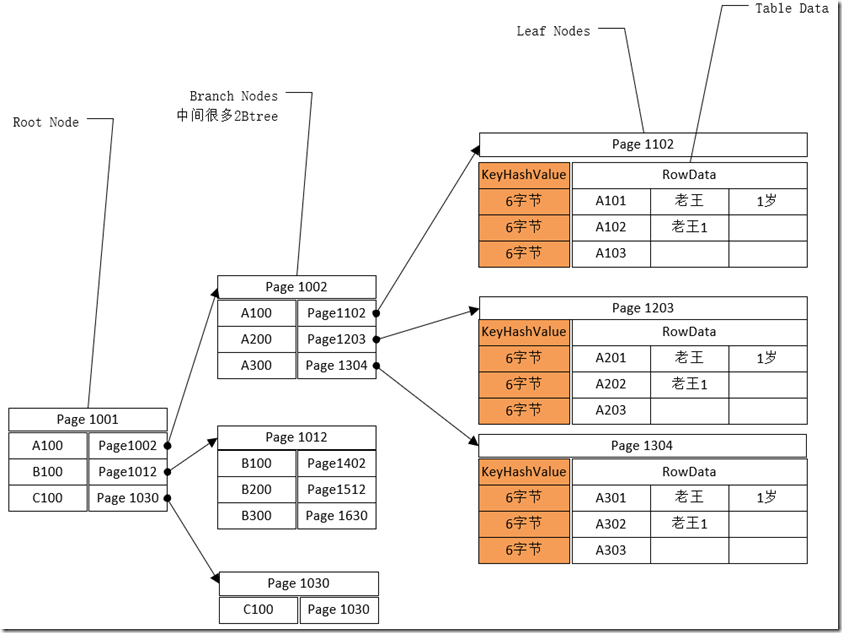
- 插入操作对BTree影响
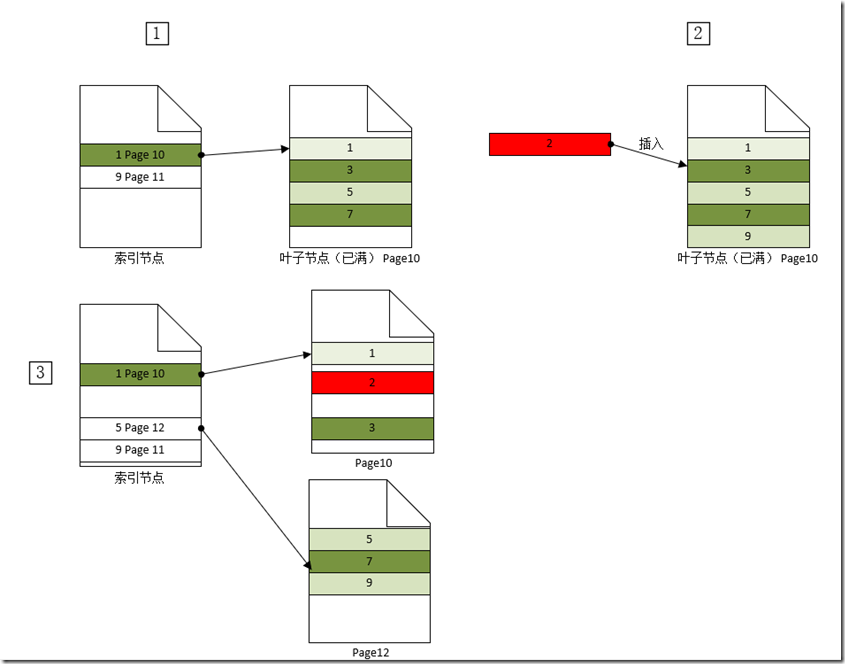
- 删除操作对索引树影响
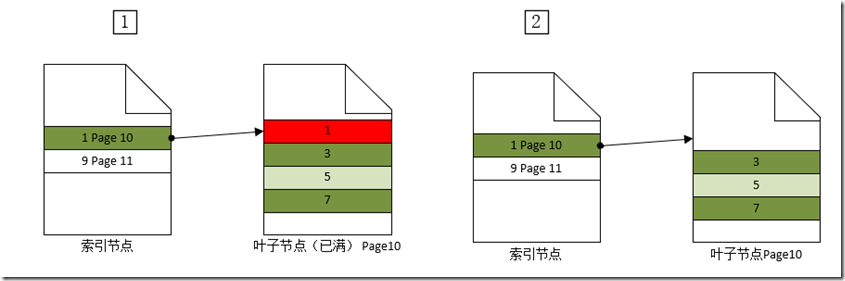
- 更新操作对索引树影响
注意事项
1. 聚集索引键值不能超过900字节,因为生成keyhashvalue时,如果大于900字节性能会有很大影响。Keyhashvalue用于查询页的数据行
2. 聚集索引键值尽量保持短,每页只有8096字节可用。减少中间节点的层数。
3. 聚集索引键值采用递增原则,有利于数据页连续性,减少BTree调整。
- 非聚集索引在索引表中数据结构
- 根节点(root nodes)、中间节点(page nodes)结构:2字节系统信息+非聚集索引键值+ChildPage(4字节)+Key
- 叶子节点leaf nodes数据结构:2字节系统信息+非聚集索引键值+ Key(keyhasvalue)
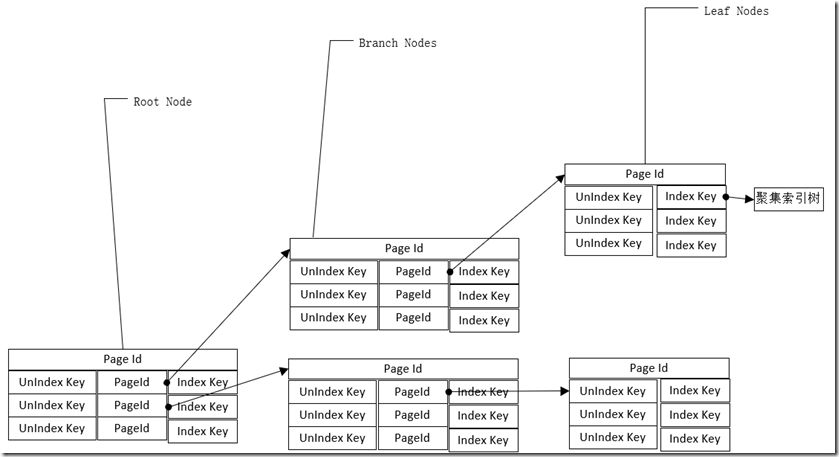
索引覆盖
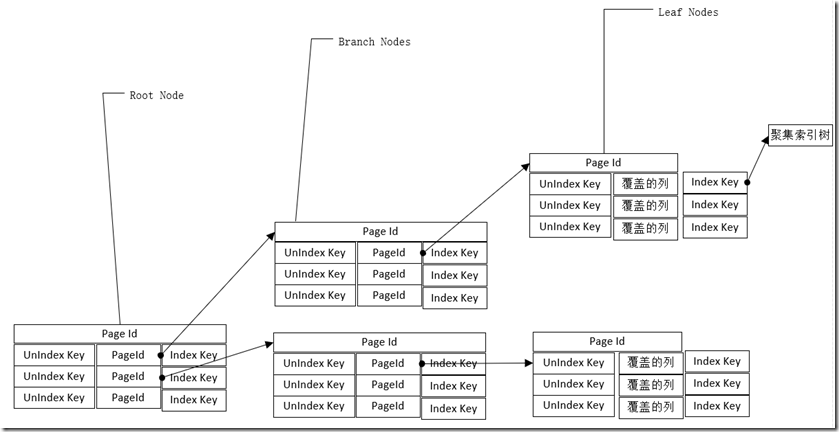
避免聚集索引查找
最大键列数为 16,最大索引键大小为 900 字节
过滤索引
索引tree是否包含部分数据。一部分不需要建立索引,减少索引层数。
- 建立聚集索引规则
- 唯一性:如果非唯一性,索引节点会增加一列唯一表示。
- 静态的: 如果对聚集索引键值进行更新时,中间节点页会发生变化,叶子节点页也会发生变化。操作次数增加,页空间造成浪费。
- 连续性:非连续性会造成页分拆,页空间浪费,碎片增多。
- 键值大小:键值长度越长,中间节点的层数越多,读取层数越多,性能下降。
- 索引覆盖
对常用查询指定列的索引可以适当增加列覆盖。
- 非聚集索引
- 数据密度原则:数据密度是指列值唯一的记录占总记录数的百分比,这个比率越高,则说明此列越适合建立索引。
- 复合索引键列顺序:在索引中,索引的顺序主要由索引中的每一个键列确定,因此,对于复合索引,索引中的列顺序是很重要的,应该优先把数据密度大,选择性列,存储空间小的列放在索引键列的前面。
- 选择性原则:选择性是满足条件的记录占总记录数的百分比,这个比率应该尽可能低,这样才能保证通过索引扫描后,只需要从基础表提取很少的数据。
DBCC IND
用于分析表组织和索引组织查询命令。
- 命令行
DBCC IND ( { 'dbname' | dbid }, { 'objname' | objid }, { nonclustered indid | 1 | 0 | -1 | -2 } [, partition_number] )
- 参数
- Dbname:数据库名
- Dbid:数据库Id
- Objname:表名
- Objid:表ID
- nonclustered indid:非聚集索引ID,-2 根节点 -1 中间节点 Branch Nodes 0 叶子节点、1 所有节点
- 下列查询语句等同于 DBCC IND
Select * from sys.dm_db_database_page_allocations(DB_ID(), object_id('TestData8000'),NULL,NULL,'DETAILED')
sys.dm_db_database_page_allocations(@DatabaseId , @TableId , @IndexId , @PartionID , @Mode)
- @DatabaseId:数据库Id
- @TableId:表名
- @indexId:
- @PartionId:分区Id
堆表
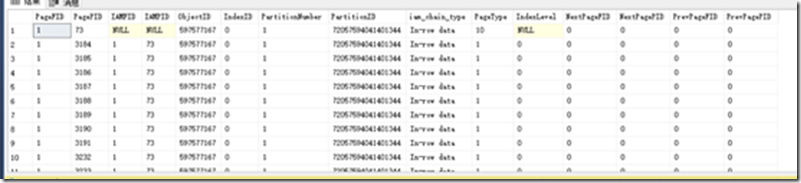
聚集索引表
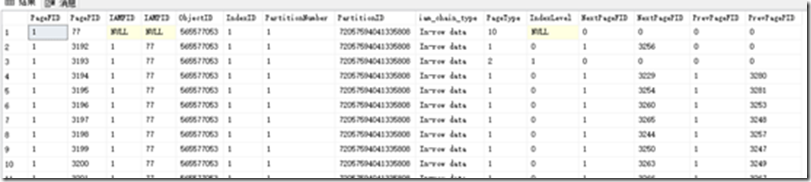
查询结果集,字段说明
|
列 |
说明 |
|
PageFID |
索引所在文件Id |
|
PagePid |
索引所在页Id |
|
IAMFID |
索引所在IAM文件Id |
|
IAMPID |
索引所在IAM的页Id |
|
objectId |
对象ID,表对象ID |
|
IndexId |
索引类型 0堆、1聚集索引、2-250非聚集索引 |
|
PartitionNumber |
索引所在分区编号 |
|
PartitionId |
索引所在的分区Id |
|
Iam_Chain_Type |
该页存放的数据类型、in-row data 数据页或索引页、Row-overflow-data 溢出数据行页 Blob data 大文件类型页 |
|
PageType |
数据类型见页类型 |
|
IndexLevel |
索引级别 null 根级,0 叶子级,其他索引级 |
|
NextPageFID |
双链表前级文件Id |
|
NextPagePID |
双链表前级页Id |
|
PrevPageFID |
双链表后级文件Id |
|
PrevPagePID |
双链表后级页Id |
DBCC Page
用于查看页数据信息。
DBCC PAGE
(
['database name'|database id], -- can be the actual name or id of the database
file number, -- the file number where the page is found
page number, -- the page number within the file
print option = [0|1|2|3] -- display option; each option provides differing levels of information
)
- database name:数据库名
- file Number:页所在文件Id
- Page Number:页id
- Print 0、1、2、3:不同的级别,3为最高级
--DBCC IND('DataPageTestDb','TestData8000',-1) 先查看表在数据里页数据信息
--DBCC PAGE(DataPageTestDb,1,8,3) 以文本信息查看
--DBCC PAGE(DataPageTestDb,1,8,3) with tableresults,以表格信息查看
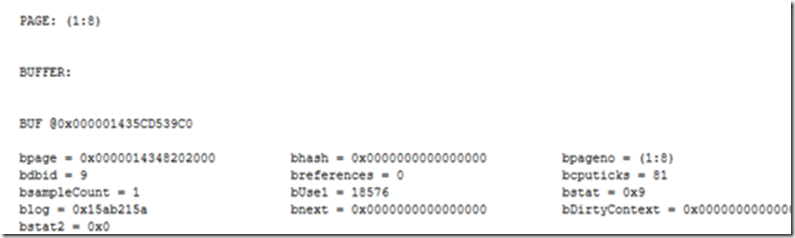
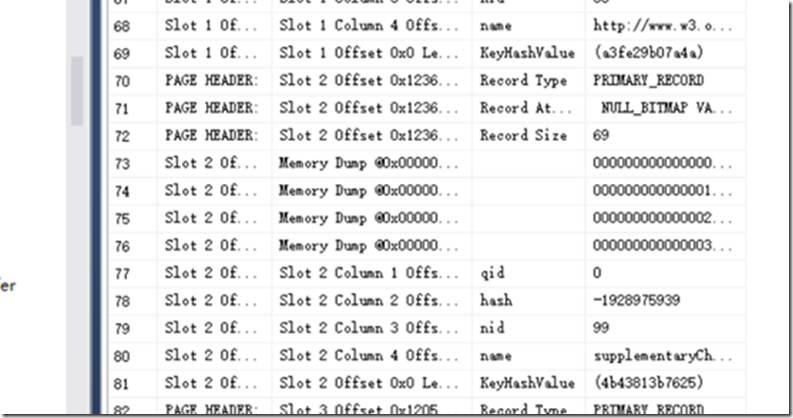
查看索引情况
--dbcc show_statistics ([tablename], [indexname])
--dbcc show_statistics (TestDataUnIndex, PK_TestDataUnIndex)
命令详细见
https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms174384(v=sql.105)
-- 打开IO开销统计 set STATISTICS io ON
-- 打开执行时间统计 set STATISTICS TIME ON
-- Select * from Table
或
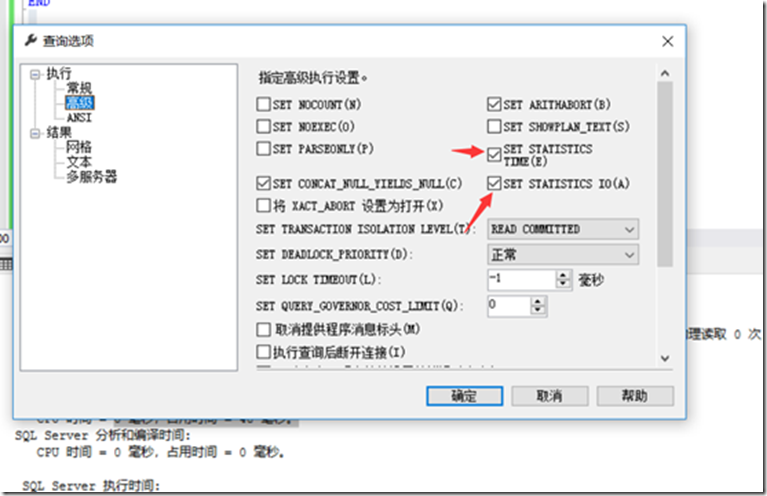
Sql Profiler 用于跟踪程序生成的语句。
参考文章
https://www.cnblogs.com/yx007/p/7268310.html
下图用于跟踪Net sqlclient data provider 产生的语句,net体系应用。
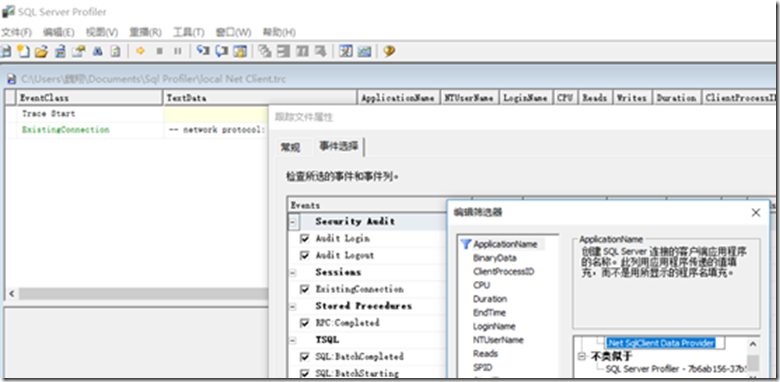
以下语句用于跟踪,在线运行时,SQL操作用时比较长的语句
SELECT TOP total_worker_time/execution_count AS [Avg CPU Time], (SELECT SUBSTRING(text,statement_start_offset/, (CASE WHEN statement_end_offset = - then LEN(CONVERT(nvarchar(max), text)) * ELSE statement_end_offset end -statement_start_offset)/) FROM sys.dm_exec_sql_text(sql_handle)) AS query_text, * FROM sys.dm_exec_query_stats ORDER BY [Avg CPU Time] DESC
select request_session_id,OBJECT_NAME(resource_associated_entity_id) tableName from sys.dm_tran_locks where resource_type='OBJECT' use master go --检索死锁进程 select spid, blocked, loginame, last_batch, status, cmd, hostname, program_name from sysprocesses where spid in ( select blocked from sysprocesses where blocked <> 0 ) or (blocked <>0) select request_session_id,OBJECT_NAME(resource_associated_entity_id) tableName from sys.dm_tran_locks where resource_type='OBJECT'
|
类型 |
字节数 |
定长 |
变长 |
blob类型 |
|
uniqueidentifier |
16 |
1 |
||
|
date |
3 |
1 |
||
|
time |
5 |
1 |
||
|
datetime2 |
8 |
1 |
||
|
datetimeoffset |
10 |
1 |
||
|
tinyint |
1 |
1 |
||
|
smallint |
2 |
1 |
||
|
int |
4 |
1 |
||
|
smalldatetime |
4 |
1 |
||
|
real |
4 |
1 |
||
|
money |
8 |
1 |
||
|
datetime |
8 |
1 |
||
|
float |
8 |
1 |
||
|
sql_variant |
8016 |
1 |
||
|
bit |
1 |
1 |
||
|
decimal(18.2) |
9 |
1 |
||
|
numeric(18.2) |
9 |
1 |
||
|
varchar(max) |
1 |
|||
|
nvarchar(max) |
1 |
|||
|
varbinary(max) |
1 |
|||
|
XML |
1 |
|||
|
Image |
1 |
|||
|
text |
||||
|
ntext |
||||
|
varchar() |
1 |
|||
|
nvarchar() |
1 |
|||
|
varbinary() |
1 |
|||
|
char |
1 |
|||
|
nchar |
1 |
【野草】SQL Server之索引解析(二)的更多相关文章
- SQL Server之索引解析(一)
SQL Server之索引解析(一) 1.写在前面 微软专门给出SQL Server设计思路及实现路线,从7大体系结构阐述是如何实现,通过了解这些,我们就可以总结出数据库设计原则.编程中sql写法 ...
- 【野草】SQL Server之索引解析(一)
1.写在前面 微软专门给出SQL Server设计思路及实现路线,从7大体系结构阐述是如何实现,通过了解这些,我们就可以总结出数据库设计原则.编程中sql写法及注意事项,从而优化我们的系统性能,本系列 ...
- SQL Server之索引解析(二)
1.堆表 堆表通过IAM连接一起,查询时全表扫描. 1.1 非聚集索引 结构 叶子节点数据结构:行数据结构+Rid(8字节) 中间节点数据结构: (非聚集非唯一索引)行数据结构+Page(4)+2+ ...
- SQL Server 数据加密功能解析
SQL Server 数据加密功能解析 转载自: 腾云阁 https://www.qcloud.com/community/article/194 数据加密是数据库被破解.物理介质被盗.备份被窃取的最 ...
- 公司内部培训SQL Server传统索引结构PPT分享
公司内部培训SQL Server传统索引结构PPT分享 下载地址 http://files.cnblogs.com/files/lyhabc/SQLServer%E4%BC%A0%E7%BB%9F%E ...
- Sql Server来龙去脉系列之二 框架和配置
本节主要讲维持数据的元数据,以及数据库框架结构.内存管理.系统配置等.这些技术点在我们使用数据库时很少接触到,但如果要深入学习Sql Server这一章节也是不得不看.本人能力有限不能把所有核心的知识 ...
- SQL Server 数据库索引
原文:SQL Server 数据库索引 一.什么是索引 减少磁盘I/O和逻辑读次数的最佳方法之一就是使用[索引] 索引允许SQL Server在表中查找数据而不需要扫描整个表. 1.1.索引的好处: ...
- SQL Server 创建索引方法
转自 <SQL Server 创建索引的 5 种方法> 地址:https://www.cnblogs.com/JiangLe/p/4007091.html 前期准备: create tab ...
- SQL Server 查询优化 索引的结构与分类
一.索引的结构 关系型数据库中以二维表来表达关系模型,表中的数据以页的形式存储在磁盘上,在SQL SERVER中,数据页是磁盘上8k的连续空间,那么,一个表的所有数据页在磁盘上是如何组织的呢?分两种情 ...
随机推荐
- Egret获取和显示时间,年,月,日,时分秒
let now = new Date(); this.nowYear = now.getFullYear(); this.nowMonth = now.getMonth() + 1; let noww ...
- 正则匹配ts的引用
ts文件引入代码如下: import { IView, GridView, Sizing as GridViewSizing, Box, IGridViewStyles } from './gridv ...
- react.JS基础
1.ReactDOM.render() React.render 是 React 的最基本方法,用于将模板转为 HTML 语言,并插入指定的 DOM 节点. <!DOCTYPE html> ...
- Tips_信息列表(手风琴)效果的多种实现方法
效果图: 一.纯CSS实现 <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...
- VS2017Release+x64失败,LNK1104,无法打开文件"msvcprt.lib"
采用VS2017+Qt5.10联合开发环境建立开发,将Qt的库包含到VS中使用VS2017的Debug+x64模式调试程序,通过并出现对应的EXE应用程序! 但是转换到Release+x64模式出现问 ...
- nginx连接数优化
一.一般来说nginx 配置文件中对优化比较有作用的为以下几项: 1. worker_processes 8; nginx 进程数,建议按照cpu 数目来指定,一般为它的倍数 (如,2个四核的cpu计 ...
- iOS浏览器 new Date() 返回 NaN
问题 项目中某个地方用到了倒计时,因此打算通过 new Date() 函数实现.但在 iPhone 真机测试的时候,显示的结果不符合预期.通过调试发现 iOS 中 new Date('2017-01- ...
- topic的leader显示为none的解决办法
1.查看kafka的topic详细信息 bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --topic test --describe 配置delete. ...
- 反爬虫:利用ASP.NET MVC的Filter和缓存(入坑出坑)
背景介绍: 为了平衡社区成员的贡献和索取,一起帮引入了帮帮币.当用户积分(帮帮点)达到一定数额之后,就会“掉落”一定数量的“帮帮币”.为了增加趣味性,帮帮币“掉落”之后所有用户都可以“捡取”,谁先捡到 ...
- RabbitMQ消息队列系列教程(二)Windows下安装和部署RabbitMQ
摘要 本篇经验将和大家介绍Windows下安装和部署RabbitMQ消息队列服务器,希望对大家的工作和学习有所帮助! 目录 一.Erlang语言环境的搭建 二.RabbitMQ服务环境的搭建 三.Ra ...