Spark框架详解
一、引言
Introduction
本文主要讨论 Apache Spark 的设计与实现,重点关注其设计思想、运行原理、实现架构及性能调优,附带讨论与 Hadoop MapReduce 在设计与实现上的区别。不喜欢将该文档称之为“源码分析”,因为本文的主要目的不是去解读实现代码,而是尽量有逻辑地,从设计与实现原理的角度,来理解 job 从产生到执行完成的整个过程,进而去理解整个系统。
讨论系统的设计与实现有很多方法,本文选择 问题驱动 的方式,一开始引入问题,然后分问题逐步深入。从一个典型的 job 例子入手,逐渐讨论 job 生成及执行过程中所需要的系统功能支持,然后有选择地深入讨论一些功能模块的设计原理与实现方式。也许这样的方式比一开始就分模块讨论更有主线。
本文档面向的是希望对 Spark 设计与实现机制,以及大数据分布式处理框架深入了解的 Geeks。
因为 Spark 社区很活跃,更新速度很快,本文档也会尽量保持同步,文档号的命名与 Spark 版本一致,只是多了一位,最后一位表示文档的版本号。
由于技术水平、实验条件、经验等限制,当前只讨论 Spark core standalone 版本中的核心功能,而不是全部功能。诚邀各位小伙伴们加入进来,丰富和完善文档。
关于学术方面的一些讨论可以参阅相关的论文以及 Matei 的博士论文,也可以看看我之前写的这篇 blog。
好久没有写这么完整的文档了,上次写还是三年前在学 Ng 的 ML 课程的时候,当年好有激情啊。这次的撰写花了 20+ days,从暑假写到现在,大部分时间花在 debug、画图和琢磨怎么写上,希望文档能对大家和自己都有所帮助。
Contents
https://github.com/JerryLead/SparkInternals
Spark Version: 1.0.2
Doc Version: 1.0.2.0
本文档首先讨论 job 如何生成,然后讨论怎么执行,最后讨论系统相关的功能特性。具体内容如下:
- Overview 总体介绍
Spark详解01概览|Spark部署|执行原理 - Job logical plan 介绍 job 的逻辑执行图(数据依赖图)
Spark详解02Job 逻辑执行图 - Job physical plan 介绍 job 的物理执行图
Spark详解03Job 物理执行图 - Shuffle details 介绍 shuffle 过程
Spark详解04Shuffle 过程 - Architecture 介绍系统模块如何协调完成整个 job 的执行
Spark详解05架构Architecture - Cache and Checkpoint 介绍 cache 和 checkpoint 功能
Spark详解06容错机制Cache 和 Checkpoint - Broadcast 介绍 broadcast 功能
Spark详解07广播变量Broadcast - Job Scheduling 尚未撰写
- Fault-tolerance 尚未撰写
可以直接点 md 文件查看。
喜欢看 pdf 版本的可以去 这里 下载。
如果使用 Mac OS X 的话,推荐下载 MacDown 后使用 github 主题去阅读这些文档。
Examples
写文档期间为了 debug 系统,自己设计了一些 examples,放在了 SparkLearning/src/internals 下。
二、我的理解
0、Spark概述
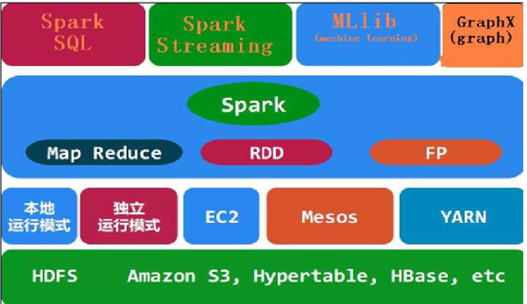
Spark是分布式的基于内存的迭代式计算框架,当然它也可以基于磁盘做迭代计算,根据Apache Spark开源组织官方描述,Spark基于磁盘做迭代计算也会比基于磁盘迭代的MapReduce框架快10余倍;而基于内存迭代计算则比MapReduce迭代快100倍以上。同时由于Spark是迭代式的计算框架,因此它天生擅长于将多步骤作业通过应用层面向过程的流水化操作将其转换成底层的多个作业串联操作,这在第一代计算框架MapReduce中需要我们程序员手动分解多个步骤的操作到各个作业中去。于此,我们如果基于Mapreduce来编写数据分析应用会耗费大量代码。然而如果基于Spark的API来构建应用会表现的非常的快速和高效,其Spark生态圈如下图所示:
1、Spark框架原理
Spark是基于内存的一种迭代式计算框架,其处理的数据可以来自于任何一种存储介质,如:关系数据库、本地文件系统、分布式存储、网络Socket字节流等;Spark从数据源存储介质中装载需要处理的数据到内存中,并将这些数据集抽象为RDD(弹性分布式数据集)对象,然后采用一系列的算子(封装计算逻辑的API)来处理这些RDD,并将处理好的结果以RDD的形式输出到内存或以数据流的方式持久化写入到其它存储介质中。
Spark框架拥有一系列的用于迭代计算的算子库,通过对这些算子的调用可以完成数据集在内存中的实时计算和处理,Spark在提交一个应用之后会在Spark客户端启动一个Driver进程,之后就是该Driver进程负责与Spark集群中Master节点进行数据交互,同时Driver进程会跟踪和收集Master节点反馈回来的数据处理工况。Spark集群中Master节点接收到Driver进程申请应用的请求后会基于Spark框架内部机制分析应用并将提交的应用拆解为各个可以直接执行的作业,这些作业之间根据设计的业务逻辑流程或为并发执行、或为串行执行都有Spark的分析器来实现决策,每个作业的内部又可以细分为各个任务,每个任务都对应一个具体的执行进程。Spark根据分析器拆分的作业以及任务的类型和数量将其分配到各个工作节点上去,每个工作节点上都有一个Worker进程来响应Master节点的调度处理;分配的具体任务都是由Spark在各个工作节点上生成的Executor进程来予以处理;在任务调度过程中,从一个任务到另一个任务的过渡或为在一个Executor进程内部完成数据转移、或为在不同的Executor进程之间完成数据转移;如果数据在不同的Executor之间完成数据转移则称为Stage(迭代步骤),计算过程中数据在不同的Stage之间迁移和交互涉及到数据在处理进程之间的重新分配过程,通常数据的重新分配会产生网络IO操作,网络IO操作会为分布式计算带来附加的集群负载,这是所有分布式计算所具备的共同特征,也是分布式计算为什么仅适用于处理大数据集的一个根源所在。
每个节点上的任务操作结束之后都会将计算结果反馈给Worker进程,Worker进程负责将任务计算完成之后的状态就汇报给Master进程,Master进程负责数据输入、计算、调度和数据输出的整个迭代过程。每个任务结束之后Master进程都会将其注销,同时根据输入数据集的分配以启动新的任务继续处理剩余的数据。待指定的数据集全部处理结束之后,Master节点将数据集的处理结果反馈给Spark客户端,同时关闭与Spark客户端的连接。
https://www.cnblogs.com/tgzhu/p/5818374.html
https://blog.csdn.net/yejingtao703/article/details/79438572
Spark框架详解的更多相关文章
- Spark2.1.0——内置Web框架详解
Spark2.1.0——内置Web框架详解 任何系统都需要提供监控功能,否则在运行期间发生一些异常时,我们将会束手无策.也许有人说,可以增加日志来解决这个问题.日志只能解决你的程序逻辑在运行期的监控, ...
- Spark2.1.0——内置RPC框架详解
Spark2.1.0——内置RPC框架详解 在Spark中很多地方都涉及网络通信,比如Spark各个组件间的消息互通.用户文件与Jar包的上传.节点间的Shuffle过程.Block数据的复制与备份等 ...
- jQuery Validate验证框架详解
转自:http://www.cnblogs.com/linjiqin/p/3431835.html jQuery校验官网地址:http://bassistance.de/jquery-plugins/ ...
- mina框架详解
转:http://blog.csdn.net/w13770269691/article/details/8614584 mina框架详解 分类: web2013-02-26 17:13 12651人 ...
- lombok+slf4j+logback SLF4J和Logback日志框架详解
maven 包依赖 <dependency> <groupId>org.projectlombok</groupId> <artifactId>lomb ...
- [Cocoa]深入浅出 Cocoa 之 Core Data(1)- 框架详解
Core data 是 Cocoa 中处理数据,绑定数据的关键特性,其重要性不言而喻,但也比较复杂.Core Data 相关的类比较多,初学者往往不太容易弄懂.计划用三个教程来讲解这一部分: 框架详解 ...
- iOS 开发之照片框架详解(2)
一. 概况 本文接着 iOS 开发之照片框架详解,侧重介绍在前文中简单介绍过的 PhotoKit 及其与 ALAssetLibrary 的差异,以及如何基于 PhotoKit 与 AlAssetLib ...
- Quartz.NET作业调度框架详解
Quartz.NET作业调度框架详解 http://www.cnblogs.com/lmule/archive/2010/08/28/1811042.html
- mapreduce框架详解
hadoop 学习笔记:mapreduce框架详解 开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感 ...
随机推荐
- SpringBoot报错:Invalid bound statement (not found)
错误原因: 没有发现Mybatis配置文件的路径 解决方法: 检查Mapper包名与xml文件标签的namespace数据名称是否相同 <mapper namespace="com.t ...
- Android Architecture Components--项目实战
转载请注明出处,谢谢! 上个月Google Android Architecture Components 1.0稳定版发布,抽工作间隙写了个demo,仅供参考 Github地址:https://gi ...
- Pinpoint在Win7下搭建
Pinpoint在Win7下搭建 注:原创作品,未经允许严禁转载 对于Pinpoint是什么这个问题,在此不做任何讨论,因此本篇文章适用人群为了解Pinpoint相关基础理论知识,需要进行Window ...
- js原型与继承
demofunction Fun(){} var foo = new Fun();foo.__proto__ === Fun.prototype 摘要 1.js本身不提供类实现,es6引入了class ...
- linux下SS 网络命令详解
ss命令用来显示处于活动状态的套接字信息. ss命令可以用来获取socket统计信息,它可以显示和netstat类似的内容. 但ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比n ...
- Java设计模式之单例模式,笔记完整到不敢想象
单例模式: 作用 保证一个类只有一个实例,并且提供一个访问该实例的全局访问入口 单例模式的常用 1.Windows的任务管理器2.Windows的回收站,也是一个单例应用3.项目中的读取配置文件的对象 ...
- WordPress独立下载页面与演示插件:xydown
我的博客是个资源分享的网站,所以需要提供下载,之前一直是在内容里直接添加个下载链接,感觉不是很美观,而且也麻烦,所以今天找了下看看有没有可以用的下载插件 xydown,这是一款可以独立下载页面与演示的 ...
- You need to use a Theme.AppCompat theme (or descendant) with this activity 问题解决
You need to use a Theme.AppCompat theme (or descendant) with this activity 问题解决 问题代码 void initCommit ...
- JDK 和 OpenJDK 的区别
历史上的原因是,openjdk是jdk的开放原始码版本,以GPL协议的形式放出.在JDK7的时候,openjdk已经成为jdk7的主干开发,sun jdk7是在openjdk7的基础上发布的,其大部分 ...
- [Swift]LeetCode148. 排序链表 | Sort List
Sort a linked list in O(n log n) time using constant space complexity. Example 1: Input: 4->2-> ...