大数据ssh疑点跟踪
相信运维的对ssh免密登陆应该是对这个再清楚不过的吧,由于我们大数据对于安全这方便管控的很严格,单独找一台物理机作为跳板机,其他的机器都必须要从这个跳板机免密登陆,由于机器比较的多,其中dn30这个域名ssh无法登陆,但是对应的IP地址是可以正常ssh免密登陆的,如图1所示:

【图1】
我检查了一下目标端dn30的authorized_keys内容,cm跳板的hadoop的公钥已经给了dn30,这一点没毛病呀,再检查ssh目录以及下面的文件权限也没问题呀(如图2所示),究竟什么情况能导致这个问题呢?

【图2】
最后查看了dn30的known_hosts的内容,发现里面记录的竟然是search03的ssh连接秘钥对,而search03的known_hosts记录的却是dn30的ssh连接秘钥对;两台机器与本地的域名不一致,为什么会这样呢?这才记起来,原来这两台机器装完之后,已经做了ssh域名免密登陆,现在的这个dn30机器应该是search03,而search03应该是dn30,因为dn30硬盘故障,是后面恢复的,所以域名解析互换了,但是秘钥对还保存在know_hosts里面,知道了原因,这就好办了,我们直接登陆到两台机器上直接rm -rf /home/hadoop/.ssh/known_hosts或者>/home/hadoop/.ssh/known_hosts清空。
随后我们在尝试ssh dn30,还是不行,难道这不是根本原因吗?目标端的不是已经清空了knows_hosts对应的ssh连接信息吗?
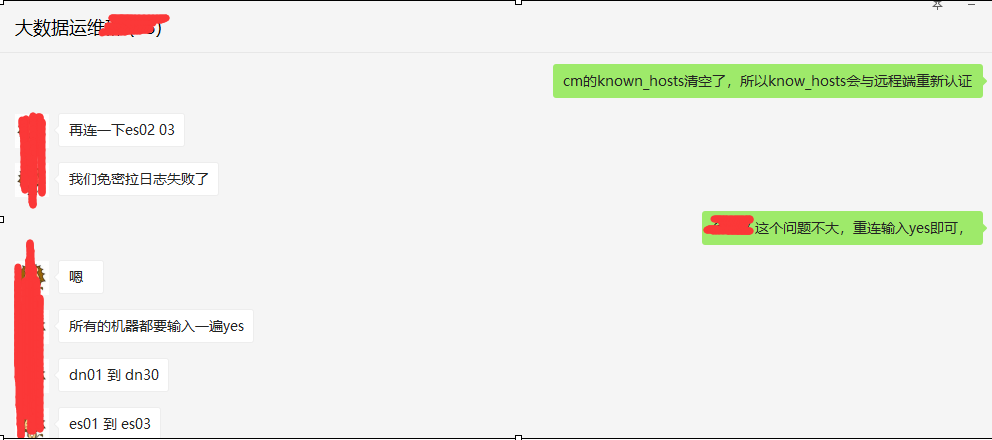
其实细心的同学们会发现,源端还是有个knows_hosts,这里面才是真正记录ssh免密远端主机的秘钥认证信息(如图3所示),我们只有清理源端的knows_hosts的信息才能真正的解决问题
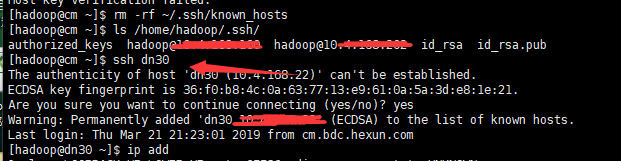
注意,这里千万别不要rm -rf knows_host或者>knows_hosts,这样的话里面记录所有的机器都需要重新认证,虽然问题不是很大,但是这样线上某些严格依赖ssh域名免密的程序就会收到影响(我就这样背一次锅,血的教训,不但要重新认证,还要被训一下,哎!如图4所示)

【图3】
【图4】
最后我们在尝试ssh dn30免密成功~
【小结】
一台主机上有多个Linux系统,会经常切换,那么这些系统使用同一ip,登录过一次后就会把ssh信息记录在本地的~/.ssh/known_hsots文件中,切换该系统后再用ssh访问这台主机就会出现冲突警告,需要手动删除修改known_hsots里面的内容
ssh会把你每个你访问过计算机的公钥(public key)都记录在~/.ssh/known_hosts。当下次访问相同计算机时,OpenSSH会核对公钥。如果公钥不同,OpenSSH会发出警告, 避免你受到DNS Hijack之类的攻击。
虽然是小技术点,但以小见大,很多细节性的问题还是得多注意,稍微不注意,线上操作需谨慎,切勿冲动!
大数据ssh疑点跟踪的更多相关文章
- 大数据【一】集群配置及ssh免密认证
八月迷情,这个月会对大数据进行一个快速的了解学习. 一.所需工具简介 首先我是在大数据实验一体机上进行集群管理学习,管理五台实验机,分别为master,slave1,slave2,slave3,cli ...
- 使用tar+pigz+ssh实现大数据的高效传输
以前我们跨主机拷贝大数据的时候,比如要拷贝超过100GB的mysql原始数据,我们通常的做法如下: 在源端打包压缩为tar.gz文件 采用scp或者rsync等方式拷贝到目标主机 在目标主机解压文件 ...
- Spark大数据针对性问题。
1.海量日志数据,提取出某日访问百度次数最多的那个IP. 解决方案:首先是将这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中.注意到IP是32位的,最多有个2^32个IP.同样可以采 ...
- java 与大数据学习较好的网站
C# C#中 Thread,Task,Async/Await,IAsyncResult 的那些事儿!https://www.cnblogs.com/doforfuture/p/6293926.html ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
- 大数据(hadoop)
大数据 一.概述 二.大数据特点 三.大数据部门组织结构 hadoop框架 一.hadoop是什么 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 主要解决,海量数据的存储和海量数 ...
- ElasticSearch大数据分布式弹性搜索引擎使用
阅读目录: 背景 安装 查找.下载rpm包 .执行rpm包安装 配置elasticsearch专属账户和组 设置elasticsearch文件所有者 切换到elasticsearch专属账户测试能否成 ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
随机推荐
- 2017-12-20python全栈9期第五天第一节之昨日内容回顾和作业讲解之字母变大写
#!/user/bin/python# -*- coding:utf-8 -*-lis = [2,3,'k',['qwe',20,['k1',['tt','3','1']],89],'ab','adv ...
- JDK常用命令行工具(基于JDK10)
虽然我是在jdk10环境下, 但是大体上和jdk8是差不多的. 总共有这么多 本来想着一口气把所有命令都边学边总结一下的, 结果发现....有些还真的不是很常用....或者说我这个水平还接触不到那么多 ...
- mysqldump 备份数据和恢复
命令行下具体用法如下: mysqldump -u用戶名 -p密码 -d 数据库名 表名 > 脚本名; 一.导出数据: 导出整个数据库结构和数据mysqldump -h localhost -u ...
- iview服务不可以被访问解决办法
一般情况是因为服务的host设置为localhsot了,修改为0.0.0.0即可. 打开...\iview-admin-dev\node_modules\webpack-dev-server\bin下 ...
- Linux 文件格式转码工具
Linux 系统下文件编码转换格式工具 ICONV 下载 https://ftp.gnu.org/pub/gnu/libiconv/libiconv-1.15.tar.gz 源码安装: $ ./con ...
- HDU-6031 Innumerable Ancestors(二分+树上倍增)
题意 给一棵树,$m$次询问,每次询问给两个点集问从两个点集中各取一个点的$LCA$的最大深度. 思路 二分答案.对于某个二分过程中得到的$Mid$,如果可行则两个点集在$Mid$所在的深度存在公共的 ...
- 第30月第13天 supportedInterfaceOrientationsForWindow旋转
1. 对于做视频横屏播放的情况下:做旋转有3种方法. 第一种:就是网上说的用旋转矩阵方法CGAffineTransformMakeRotation来做,直接旋转某个view,之后setFrame,至于 ...
- temp 和 tmp 文件
TMP和TEMP文件是各种软件或系统产生的临时文件,也就是常说的垃圾文件.Windows产生的临时文件,本质上和虚拟内存没什么两样,只不过临时文件比虚拟内存更具有针对性,单独为某个程序服务而已.而它的 ...
- Android Ndef Message解析
@concept:NDEF NFC Form论坛定义的NFC数据交换通用数据格式. 如上所示:一条NDEF消息由诸多Record记录组成,Record又由Header和Payload组成,Header ...
- 【转】详解web.xml中元素的加载顺序
顺序为: context-param --> listeners --> filters --> servlets(如DispatcherServlet等) 详见<https: ...