【Spark篇】--Spark中Standalone的两种提交模式
一、前述
Spark中Standalone有两种提交模式,一个是Standalone-client模式,一个是Standalone-master模式。
二、具体
1、Standalone-client提交任务方式
- 提交命令
./spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.
0-hadoop2.6.0.jar 100
./spark-submit --master spark://node01:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi ../li
b/spark-examples-1.6.0-hadoop2.6.0.jar 100
解释:--class org.apache.spark.examples.SparkPi main函数
../lib/spark-examples-1.6.0-hadoop2.6.0.jar jar包
100 main函数需要参数
- 执行原理图解

- 执行流程
1、client模式提交任务后,会在客户端启动Driver进程。
2、Driver会向Master申请启动Application启动的资源。
3、资源申请成功,Driver端将task发送到worker端执行。
4、worker将task执行结果返回到Driver端。
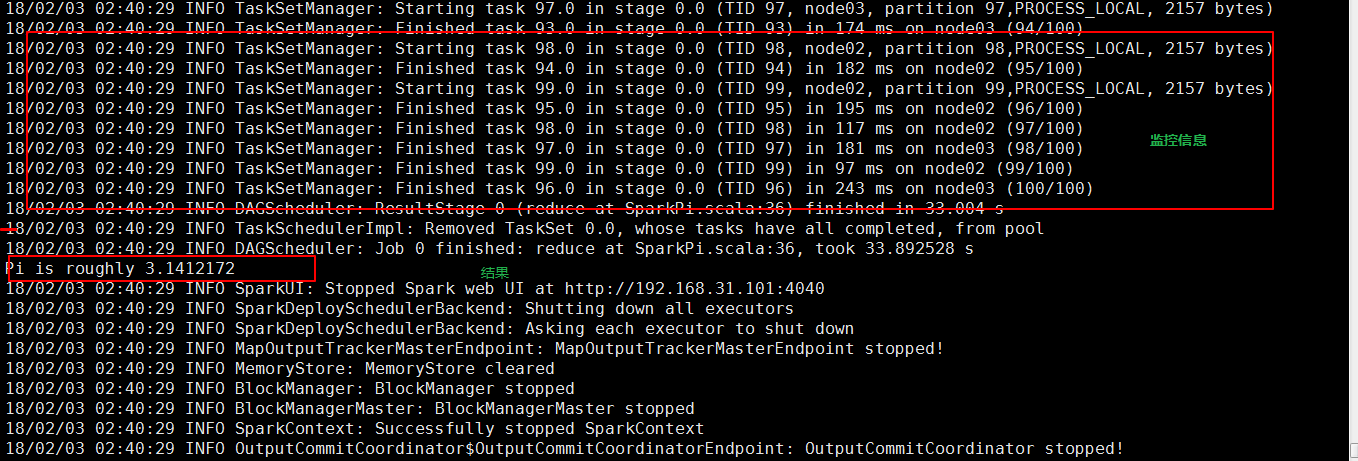
- 总结
个application到集群运行,次网卡流量暴增的问题。(因为要监控task的运行情况,会占用很多端口,如上图的结果图)客户端网卡通信,都被task监控信息占用。
2、Client端作用
1. Driver负责应用程序资源的申请
2. 任务的分发。
3. 结果的回收。
4. 监控task执行情况。
2、Standalone-cluster提交任务方式
- 提交命令
./spark-submit --master spark://node01:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../
lib/spark-examples-1.6.0-hadoop2.6.0.jar 100

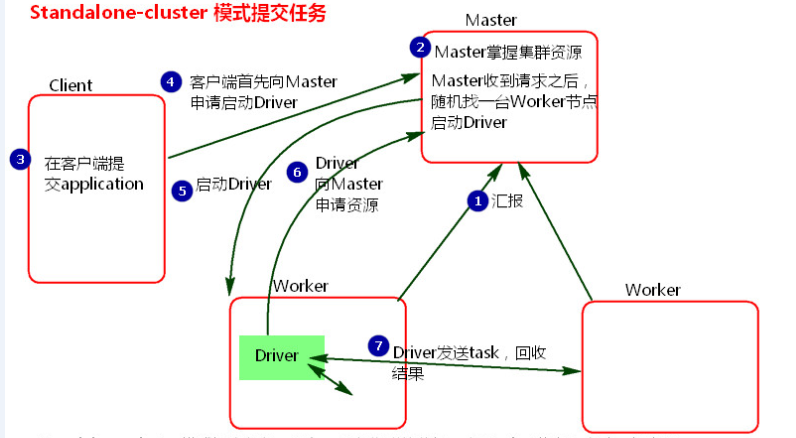
- 执行原理图解
- 执行流程
1、cluster模式提交应用程序后,会向Master请求启动Driver.(而不是启动application)
2、Master接受请求,随机在集群一台节点启动Driver进程。
3、Driver启动后为当前的应用程序申请资源。Master返回资源,并在对应的worker节点上发送消息启动Worker中的executor进程。
4、Driver端发送task到worker节点上执行。
5、worker将执行情况和执行结果返回给Driver端。Driver监控task任务,并回收结果。
- 总结
1、当在客户端提交多个application时,Driver会在Woker节点上随机启动,这种模式会将单节点的网卡流量激增问题分散到集群中。在客户端看不到task执行情况和结果。要去webui中看。cluster模式适用于生产环境
2、 Master模式先启动Driver,再启动Application。
【Spark篇】--Spark中Standalone的两种提交模式的更多相关文章
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
- 小记--------spark的两种提交模式
spark的两种提交模式:yarn-cluster . yarn-client 图解
- spark基于yarn的两种提交模式
一.spark的三种提交模式 1.第一种,Spark内核架构,即standalone模式,基于Spark自己的Master-Worker集群. 2.第二种,基于YARN的yarn-cluster模式. ...
- 【Spark篇】---SparkStreaming+Kafka的两种模式receiver模式和Direct模式
一.前述 SparkStreamin是流式问题的解决的代表,一般结合kafka使用,所以本文着重讲解sparkStreaming+kafka两种模式. 二.具体 1.Receiver模式 原理图 ...
- 【Spark篇】---Spark中yarn模式两种提交任务方式
一.前述 Spark可以和Yarn整合,将Application提交到Yarn上运行,和StandAlone提交模式一样,Yarn也有两种提交任务的方式. 二.具体 1.yarn-clien ...
- Spark on YARN两种运行模式介绍
本文出自:Spark on YARN两种运行模式介绍http://www.aboutyun.com/thread-12294-1-1.html(出处: about云开发) 问题导读 1.Spark ...
- spark on mesos 两种运行模式
spark on mesos 有粗粒度(coarse-grained)和细粒度(fine-grained)两种运行模式,细粒度模式在spark2.0后开始弃用. 细粒度模式 优点 spark默认运行的 ...
- Spark on YARN的两种运行模式
Spark on YARN有两种运行模式,如下 1.yarn-cluster:适合于生产环境. Spark的Driver运行在ApplicationMaster中,它负责向YARN Re ...
- Spark Streaming中空batches处理的两种方法(转)
原文链接:Spark Streaming中空batches处理的两种方法 Spark Streaming是近实时(near real time)的小批处理系统.对给定的时间间隔(interval),S ...
随机推荐
- HDU 2204 Eddy's 爱好 (容斥原理)
<题目链接> 题目大意: Ignatius 喜欢收集蝴蝶标本和邮票,但是Eddy的爱好很特别,他对数字比较感兴趣,他曾经一度沉迷于素数,而现在他对于一些新的特殊数比较有兴趣. 这些特殊数是 ...
- scrapy + selenium 的动态爬虫
动态爬虫 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会 ...
- python-MYSQL(包括ORM)交互
1.首先,我们必须得连上我们的MYSQL数据库.个人遇到连不上MYSQL数据的问题主要有:数据库的权限问题.数据库表权限的问题 同时获取数据库中的数据等. //==================== ...
- CentOS修改yum源
在安装完CentOS后一般需要修改yum源,才能够在安装更新rpm包时获得比较理想的速度.国内比较快的有163源.sohu源.这里以163源为例子. 1. cd /etc/yum.repos.d 2. ...
- 通过excel获取一串连续的数字
输入一个格式的数字 点击按住右下角 拖动即可
- 字符串转义为HTML
有时候后台返回的数据中有字符串,并需要将字符串转化为HTML,下面封装了一个方法,如下 // html转义 function htmlspecialchars_decode(string, quote ...
- python练习题目
1.查看本机安装python版本 2.用python打印"Hello World",给出源代码和执行结果 a.命令行窗口输出(前提:python程序加入PATH系统环境变量) b. ...
- 小程序重新封装打印函数console.log
习惯性使用console.log打印获取到的数据,信息等,然后上星期大佬看见了说怎么那么多打印信息出来,线上那个也是吗?问我能不能线上的就不打印出来? 我就说那就封装一个打印函数呗. 重写一个没问题, ...
- thinkphp5使用空模块
今天想做一个功能,可以后台设置url是二级域名(也是指向同一个服务器)还是一级域名(域名/模块),网上找了找,TP3.2开始取消了空模块.所以只能自己修改框架源码了. ----------有点晚,明天 ...
- Mysql初学入门
最近研究了一下Mysql的初学应用,在此进行整理记录. 1.Windows系统下的安装 我用的是win10系统,在http://dev.mysql.com/downloads/mysql/ 下载相应版 ...